1. 什么是 Hash Join
当sqlserver需要对包含大量记录的表做join的时候,往往会选择hash join,因为hash join性能优异。另外,hash join支持各种外连接和半连接。
Hash Join包含两个阶段。
第一阶段是build,sqlserver会读取一个表的所有记录生成一个保存在内存中的hash表。这个阶段往往会选择较小的表生成hash表,因为hash表太大的话会占大量内存,而且也会消耗较多的cpu资源。build阶段选择的表也称为left input或者build input。另外,hash表的key就是两个表join的equijoin字段。
第二阶段是probe,sqlserver会逐一迭代另一个表的所有记录来查询hash表,从而生成join结果。probe阶段选择的表也称为right input或者probe input。
以下的伪码说明了hash join的算法。
for each row R1 in the build table
begin
calculate hash value on R1 join key(s)
insert R1 into the hash table
end
for each row R2 in the probe table
begin
calculate hash value on R2 join key(s)
query the hash table, if R1 joins with R2
output (R1, R2)
end
从以上算法我们可以知道,在build阶段,hash join不会输出任何结果;从probe阶段开始,hash join才会输出结果。
2. hash join的内存分配
如前文所说,build阶段的hash表非常消耗内存。所以sqlserver会从做join操作的两个表中选择较小的那个表来生成hash表,并且根据这个表的大小来预估并分配所需的内存。但是,如果内存不够会怎样?这种情况下,hash表会有一小部分保存在磁盘上,其他部分仍然保存在内存中。当我们从build input中读取一条新的记录的时候,如果hash表在内存中,那么我们就把记录写进内存;如果hash表在磁盘上,那么我们就把记录写进磁盘。类似地,probe阶段如果内存不够,也会把部分记录写进磁盘。
3. hash join tree的类型
hash join tree的形状会影响内存的使用。如下图所示,hashjoin tree分为Left deep, right deep和 bushy hash。我们应该根据表的size和join的结果来决定使用哪种tree,不过大多数情况下,我们可以直接使用sqlserver的优化结果。下文举例一一介绍三种tree。
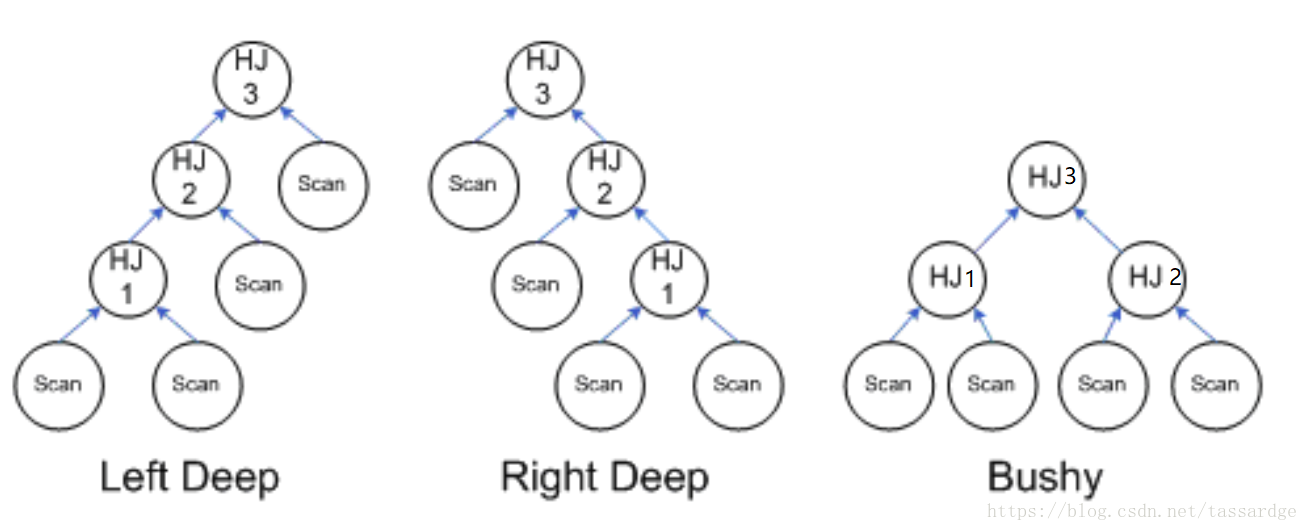
1)Left deep hash join
对于left deep,前一个join的probe output会成为下一个join的build input,这样同一时间只有相邻的两个pair会占用内存。所以对于上图的left deep,峰值内存是max(HJ1 + HJ2, HJ2 + HJ3)。实验代码如下:
IF EXISTS (SELECT * FROM sysObjects WHERE Name = 'T1')
DROP TABLE T1
IF EXISTS (SELECT * FROM sysObjects WHERE Name = 'T2')
DROP TABLE T2
IF EXISTS (SELECT * FROM sysObjects WHERE Name = 'T3')
DROP TABLE T3
create table T1 (a int, b int, x char(200))
create table T2 (a int, b int, x char(200))
create table T3 (a int, b int, x char(200))
set nocount on
declare @i int
set @i = 0
while @i < 100
begin
insert T1 values (@i * 2, @i * 5, @i)
set @i = @i + 1
end
set @i = 0
while @i < 1000
begin
insert T2 values (@i * 3, @i * 7, @i)
set @i = @i + 1
end
set @i = 0
while @i < 10000
begin
insert T3 values (@i * 5, @i * 11, @i)
set @i = @i + 1
end
SET STATISTICS PROFILE ON
select *
from (T1 join T2 on T1.a = T2.a)
join T3 on T1.b = T3.a
SET STATISTICS PROFILE OFF
DROP TABLE T1
DROP TABLE T2
DROP TABLE T3
以下是实验结果。sqlserver选择了left deep tree。我们先join T1 和 T2,并且因为T1比较小,所以选择T1生成hash表。又因为本次join只生成了34条记录远远小于T3,所以基于本次join的输出生成了下一次join的hash表。我觉得,当中间join的结果集较小的时候我们可以考虑用left deep。


2)right deep hash join
而对于right deep,前一个join的probe output会成为下一个join的probe input,这样会导致所有的pair同时占用内存计算hash表,所以对于上图的right deep,峰值内存是max(HJ1 + HJ2 + HJ3)。
以下是实验代码:
IF EXISTS (SELECT * FROM sysObjects WHERE Name = 'T1')
DROP TABLE T1
IF EXISTS (SELECT * FROM sysObjects WHERE Name = 'T2')
DROP TABLE T2
IF EXISTS (SELECT * FROM sysObjects WHERE Name = 'T3')
DROP TABLE T3
create table T1 (a int, b int, x char(200))
create table T2 (a int, b int, x char(200))
create table T3 (a int, b int, x char(200))
set nocount on
declare @i int
set @i = 0
while @i < 100
begin
insert T1 values (@i * 2, @i * 5, @i)
set @i = @i + 1
end
set @i = 0
while @i < 1000
begin
insert T2 values (@i * 3, @i * 7, @i)
set @i = @i + 1
end
set @i = 0
while @i < 10000
begin
insert T3 values (@i * 5, @i * 11, @i)
set @i = @i + 1
end
SET STATISTICS PROFILE ON
select *
from (T1 join T2 on T1.a = T2.a)
join T3 on T1.b = T3.a
where T1.a < 100
SET STATISTICS PROFILE OFF
DROP TABLE T1
DROP TABLE T2
DROP TABLE T3
以下是实验结果。因为有where T1.a < 100,并且T1.a = T2.a,所以有where T2.a < 100。因为T1和T2在where过滤之后都很小,所以sqlserver选择了right deep tree,这样两个join操作可以基于这两个表建立hash表,并且对较大的T3表做probe。这样要比基于join的中间结果生成hash表高效。我觉得,当有一个大表多个小表的时候,可以考虑用right deep。

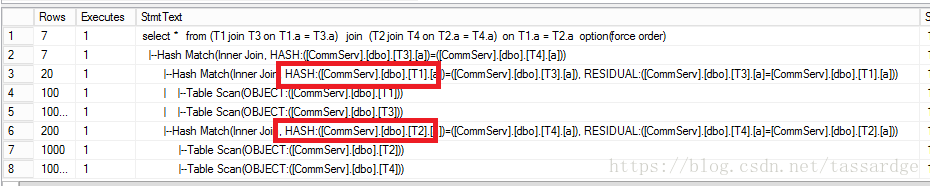
3)bushy hash join
对于bushy join,实际上是一颗平衡二叉树,它使用的内存会随着树的高度逐级减少。峰值内存显然是最底一层join的pair个数,在上图中应该是max(HJ1 + HJ2)。实验代码如下:
IF EXISTS (SELECT * FROM sysObjects WHERE Name = 'T1')
DROP TABLE T1
IF EXISTS (SELECT * FROM sysObjects WHERE Name = 'T2')
DROP TABLE T2
IF EXISTS (SELECT * FROM sysObjects WHERE Name = 'T3')
DROP TABLE T3
IF EXISTS (SELECT * FROM sysObjects WHERE Name = 'T4')
DROP TABLE T4
create table T1 (a int, b int, x char(200))
create table T2 (a int, b int, x char(200))
create table T3 (a int, b int, x char(200))
create table T4 (a int, b int, x char(200))
set nocount on
declare @i int
set @i = 0
while @i < 100
begin
insert T1 values (@i * 2, @i * 5, @i)
set @i = @i + 1
end
set @i = 0
while @i < 1000
begin
insert T2 values (@i * 3, @i * 7, @i)
set @i = @i + 1
end
set @i = 0
while @i < 10000
begin
insert T3 values (@i * 5, @i * 11, @i)
set @i = @i + 1
end
set @i = 0
while @i < 100000
begin
insert T4 values (@i * 5, @i * 11, @i)
set @i = @i + 1
end
SET STATISTICS PROFILE ON
select *
from (T1 join T3 on T1.a = T3.a)
join
(T2 join T4 on T2.a = T4.a)
on T1.a = T2.a
option(force order)
SET STATISTICS PROFILE OFF
DROP TABLE T1
DROP TABLE T2
DROP TABLE T3
DROP TABLE T4
以下是实验结果。所以,实验代码使用option(force order)强制生成bushy形状的tree。我们可以看到T1和T3,T2和T4分别做join,然后对两个join的结果再做join。可能是出于节省内存的目的考虑,sqlserver的优化很少会生成bushy tree。我个人也觉得,bushy tree没什么必要,因为bushy实际上可以用left deep或者right deep替代。