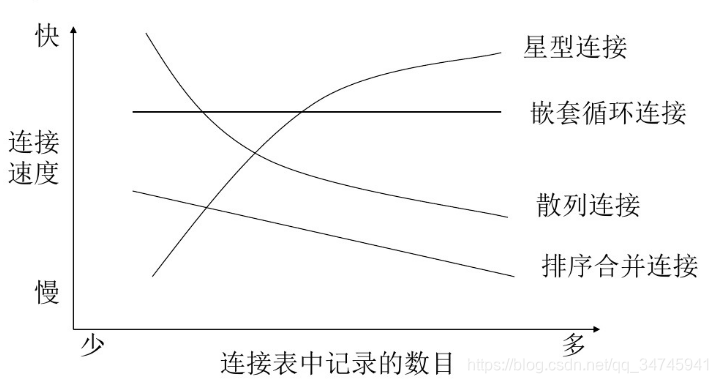
表连接方式
- 理论执行效率:
hash join > nested loops > sort merge join - CBO 优化器下,表连接方式不是固定的,可通过 hint 关键字进行强制变更。
- 优化不变原则:IO 消耗最小
| 表连接方式 | 工作原理 | 适用原则 |
|---|---|---|
| nested loops 嵌套循环 | 2层嵌套循环 | 1.驱动表数据量 < 1W 2.被查找表有索引 |
| hash join 散列连接 | 较小的表在 RAM 创建 hash table,较大的表读取记录,效率最高 | 1.等值连接 2. 驱动表大时,效果较好;驱动表小时,效果更好 3. 需要设置参数 HASH_AREA_SIZE |
| sort merge join 排序合并连接 | 记录排序然后合并 | 1. 非等值连接或排序 |
| star join 星型连接 | 多个维度表 和一个大的 数据表,然后嵌套循环连接 | 1.一般用于 数据仓库 2. 需要启用参数 STAR_TRANSFORMATION_ENABLED |
nested loops 嵌套循环
- 循环地 从一张表中读取数据(驱动表 outer table),然后访问另一张表(被查找表 inner table,
通常有索引)。驱动表中的每一行与 inner 表中的相应字段关联。
FOR o IN 1 .. n LOOP -- 一般 n < 1W
FOR i IN 1 .. m LOOP
索引字段 join;
END LOOP;
END LOOP
-- 内部连接过程
row source1 的 row1 -> probe -> row source2
row source1 的 row2 -> probe -> row source2
row source1 的 row3 -> probe -> row source2
...
row source1 的 rowN -> probe -> row source2
hash join 散列连接
- 这种连接方式是 Oracle 7.3 引入的,只能用于 CBO 优化器中
- 也有 nested loops 中所谓的驱动表概念,被 hash table 与 bitmap 的表为驱动表,当被构建的 hash table 与 bitmap 能被容纳在内存中时,这种连接方式的效率极高。
-- 内部连接过程
row source1 的 row1 -> build hash table and bitmap -> probe -> row source2
row source1 的 row2 -> build hash table and bitmap -> probe -> row source2
row source1 的 row3 -> build hash table and bitmap -> probe -> row source2
...
row source1 的 rowN -> build hash table and bitmap -> probe -> row source2
sort merge join 排序合并连接
- 先将关联表的关联列各自做排序,然后从各自的排序表中抽取数据,到另一个排序表中做匹配。
- 因为 merge join 需要做更多的排序,所以消耗的资源更多。 通常来讲,能够使用 merge join 的地方,hash join 都可以发挥更好的性能,即散列连接的效果都比排序合并连接要好。然而如果行源已经被排过序,在执行排序合并连接时不需要再排序了,这时排序合并连接的性能会优于散列连接
hint 关键字
- 注意检查语法:
select /*+ hint*/ ...中/* 和 +之间不能有空格,且必须紧跟 select 之后,否则无效 - 使用表别名:如果指定了表别名,就不能使用表名称
- 提示忽略:如果写错了,会被当做注释,不产生作用
| 表连接常用 hint 关键字 | 功能描述 |
|---|---|
/*+ LEADING(t)*/ |
将指定的表 t 作为连接次序中的首表 |
/*+ USE_NL(t1 t2)*/ |
强制将 t1,t2 使用嵌套循环 |
/*+ USE_HASH(t1 t2)*/ |
强制将 t1,t2 使用散列连接 |
/*+ USE_MERGE(t1 t2)*/ |
强制将 t1,t2 使用排序合并 |
/*+ PARALLEL(t N)*/ |
并行,表 t,并发数 N |
/*+ INDEX(t idx)*/ |
索引,表 t,索引名 idx |
SELECT /*+ leading(t1) use_hash(t1 t2)*/
t1.*
FROM table_a t1,
table_b t2
WHERE t1.a = t2.a;