前言
本篇文章是机器人自动寻路算法实现的第三章。我们要讨论的是一个在一个M×N的格子的房间中,有若干格子里有灰尘,有若干格子里有障碍物,而我们的扫地机器人则是要在不经过障碍物格子的前提下清理掉房间内的灰尘。具体的问题情景请查看人工智能: 自动寻路算法实现(一、广度优先搜索)这篇文章,即我们这个系列的第一篇文章。在前两篇文章里,我们介绍了通过广度优先搜索算法和深度优先算法来实现扫地机器人自动寻路的功能。两种算法都有各自的优点和缺点:对于广度优先搜索算法,程序会找到最优解,但是需要遍历的节点很多。而深度优先搜索则与之相反:遍历的节点很少,但是不一定会找到最优解,而且还有一种极端的情况,就是深度优先搜索在遍历的时候,如果遍历的那个分支是无限大,并且解并不在那个分支中而是在其他的分支中,那么深度优先搜索永远都找不到解。两种算法具体的比较在人工智能: 自动寻路算法实现(二、深度优先搜索)中有详细介绍。在这篇文章中,我们要介绍一种结合了前两种算法优点的算法,A*算法。
A*算法被广泛应用于游戏中的自动寻路功能,说明它作为一个路径规划的算法,确实有着很大的优势。以游戏举例来看,比如在游戏中我们想要找到从一个位置到另一个位置的路径,我们不仅尝试着找到最短距离的路径;我们还想要顾忌到消耗的时间。在一张地图上,穿过一片池塘速度会明显减慢,所以我们想要找到一条可以绕过水路的路径。
本文项目下载地址: https://github.com/tjfy1992/Robot-Path-planning-AStar
正文
算法介绍
首先我们来回顾一下广度优先搜索和深度优先搜索算法。我们从前两篇文章中可以得知,广度优先搜索算法中使用数据结构是队列,而深度优先搜索算法中适用的数据结构是栈。对于一个队列,节点总是先进先出(FIFO),因此对于队列中的第一个节点来说,它的所有直接子节点在队列中都是紧紧跟随在该节点之后,这样程序在运行的时候,对于第一个入队列的节点,就会先遍历完他所有的直接子节点,接着才会去遍历他的每个直接子节点的直接子节点。可以看出遍历的顺序就是一个类似金字塔的形状:第一行有一个头结点,第二行是该头结点的直接子节点,而第三行是直接子节点的直接子节点…每遍历一行都会找出这一行的所有子节点,所以这种算法被称为“广度优先搜索”。
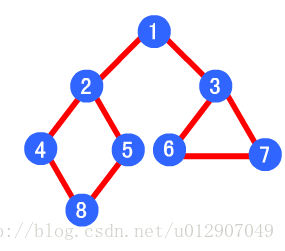
广度优先搜索的节点遍历顺序
而相对地,深度优先搜索就很好理解。对于任何一个节点,都会先去遍历它的第一个子节点的第一个子节点的第一个子节点…后进先出(LIFO)的栈则正好保证了这一点。这种“一条路走到黑”的方式,在它遍历的第一条路径就可能会找到解,但是由于不是横向遍历,路径的长度并不一定是最短,即程序不一定会给出最优解。
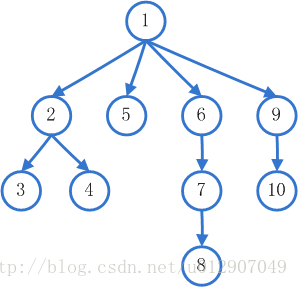
深度优先搜索的节点遍历顺序
这两种算法的优缺点都很明显,于是我们需要想出一种能结合两种算法优点的算法。我们可以做出如下处理:对于广度优先搜索算法的队列,如果我们可以想出一种方法,对队列进行排序,把前文中类似“穿过一片沼泽”这样的节点尽量放在最后去遍历,那么我们就可以在相对短的时间内找出一个最优解来。在A*算法中,我们对节点按以下的方式进行排序:
F = G + H其中,F是我们计算出的权值,F值越大,代表这个节点的收益越小,也就越接近于我们上文提到的“沼泽地”。
G指的是我们从初始节点到达现在的节点的过程中付出的代价。例如我们的机器人每走一格或每清理一个灰尘会耗费1个单位时间,那么机器人做了5个动作之后,我们的G值就是5。
H值是一个相对开放的概念,它指的是从目前状态到目标状态预计要付出的代价。这个值由算法工程师来进行估算,H值被估算的越准确,算法所需要遍历的节点就越少。以我们的扫地机器人举例,假如目前房间内只剩下一个灰尘,而这个灰尘就在机器人的东侧(右侧),那么机器人通过这种算法就可以直接选择先往东走去清理这个灰尘,而不是向其他方向走,避免了“南辕北辙”这种人工智障???的情况出现。

计算出这个值之后,我们就按这个F值在队列中进行排序。本例中源码由Java编写,在Java中有一种数据结构,PriorityQueue,即优先级队列,这种数据结构正好可以用来存放要遍历的节点。
代码
首先是Point类,用于表示坐标系中的点。这个文件与前两个算法中相同。代码如下:
public class Point {
private int X;
private int Y;
public Point(int x, int y){
this.X = x;
this.Y = y;
}
public int getX() {
return X;
}
public void setX(int x) {
X = x;
}
public int getY() {
return Y;
}
public void setY(int y) {
Y = y;
}
//判断两个点是否坐标相同
public static boolean isSamePoint(Point point1, Point point2){
if(point1.getX() == point2.getX() && point1.getY() == point2.getY())
return true;
return false;
}
}接下来是State类。如果把问题的情景(房间、机器人)比作一个系统,那么State类就表示某一时刻系统的状态,也就是我们要遍历的节点。注意这个类里比之前的两个算法多了两个属性,F值和G值。G值就是机器人从其实状态到当前状态所进行的操作次数。F值是G值和H值的和。而H值,在这里并没有列出来,因为我把它视为当前状态下仍未被清理的灰尘数量,也就是灰尘列表的size,通过当前状态的dirtList取size()即可得到,便不再单独设该属性。
import java.util.ArrayList;
import java.util.List;
public class State {
//机器人位置
private Point robotLocation;
//操作,分为N(向上移动一格), S(向下移动一格), W(向左移动一格), E(向右移动一格)以及C(清理灰尘)
private String operation;
//当前节点的父节点, 用于达到目标后进行回溯
private State previousState;
//灰尘所在坐标的list
private List<Point> dirtList;
//fvalue为gvalue和hvalue的和
private int fvalue;
//gvalue
private int cost;
public Point getRobotLocation() {
return robotLocation;
}
public void setRobotLocation(Point robotLocation) {
this.robotLocation = robotLocation;
}
public String getOperation() {
return operation;
}
public void setOperation(String operation) {
this.operation = operation;
}
public State getPreviousState() {
return previousState;
}
public void setPreviousState(State previousState) {
this.previousState = previousState;
}
public List<Point> getDirtList() {
return dirtList;
}
public void setDirtList(List<Point> dirtList) {
this.dirtList = new ArrayList<Point>();
for(Point point : dirtList){
this.dirtList.add(point);
}
}
public int getFvalue() {
return fvalue;
}
public void setFvalue(int fvalue) {
this.fvalue = fvalue;
}
public int getCost() {
return cost;
}
public void setCost(int cost) {
this.cost = cost;
}
//用于判断两个节点是否相同
public static boolean isSameState(State state1, State state2){
//若机器人位置不同,则节点不同
if(!Point.isSamePoint(state1.getRobotLocation(), state2.getRobotLocation()))
return false;
//若灰尘列表长度不同, 则节点不同
else if(state1.getDirtList().size() != state2.getDirtList().size())
return false;
//若前两者都相同, 则判断两个state中的灰尘列表中的灰尘坐标是否完全相同
else{
for(Point point : state1.getDirtList())
{
boolean same = false;
for(Point point2 : state2.getDirtList())
{
if(Point.isSamePoint(point, point2))
same = true;
}
if(!same)
return false;
}
}
//若满足上述所有条件, 则两节点相同。
return true;
}
}最后是算法的实现类,Robot类。该类使用了一个新的数据结构:PriorityQueue来作为存储节点的open list。PriorityQueue需要我们自定义一个比较器(Comparator)用于在插入元素时将该元素与列表中的元素进行比较,并插入适当的位置,保证PriorityQueue在任何时刻都是有序的。需要注意的一点是我们需要把F值较小的元素排在前面。
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.PriorityQueue;
import java.util.Queue;
import java.util.Scanner;
public class Robot {
//行数
public static int colomnNum;
//列数
public static int rowNum;
//障碍物数量
public static int obstacleNum;
//用于存放state的优先级队列
public static Queue<State> priorityQueue;
//地图
public static String[][] map;
//灰尘坐标列表
public static List<Point> dirtList;
//closeList,用于存放已经存在的state
public static List<State> closeList;
//遍历总耗费
public static int cost = 0;
public static void main(String[] args) {
State initialState = new State();
Scanner sc = new Scanner(System.in);
System.out.println("Please Enter Row Number:");
rowNum = sc.nextInt();
System.out.println("Please Enter Colomn Number:");
colomnNum = sc.nextInt();
map = new String[rowNum][colomnNum];
dirtList = new ArrayList<Point>();
closeList = new ArrayList<State>();
sc.nextLine();
for(int i=0; i<rowNum; i++)
{
System.out.println("Please Enter the Elements in row " + (i + 1) + ":");
String line = sc.nextLine();
for(int j=0; j<colomnNum; j++)
{
//统计障碍物数量
if(line.charAt(j) == '#')
{
obstacleNum++;
}
//将灰尘格子坐标存入list中
if(line.charAt(j) == '*')
{
dirtList.add(new Point(i, j));
}
//设置机器人初始坐标
if(line.charAt(j) == '@')
{
initialState.setRobotLocation(new Point(i, j));
}
//初始化地图
map[i][j] = line.charAt(j) + "";
}
}
sc.close();
initialState.setDirtList(dirtList);
initialState.setCost(0);
initialState.setFvalue(0 + dirtList.size());
//优先级队列的自定义Comparator,比较规则是Fvalue较小的state排在队列前面
Comparator<State> cmp = new Comparator<State>() {
public int compare(State s1, State s2) {
return s1.getFvalue() - s2.getFvalue();
}
};
//初始化优先级队列
priorityQueue = new PriorityQueue<State>(5, cmp);
closeList.add(initialState);
priorityQueue.add(initialState);
cost++;
//遍历开始
while(!priorityQueue.isEmpty()){
//取出队列中第一个state
State state = priorityQueue.poll();
//如果达到目标,输出结果并退出
if(isgoal(state)){
output(state);
return;
}
calculate(state);
}
}
public static void calculate(State state){
//获取当前机器人的坐标
int x = state.getRobotLocation().getX();
int y = state.getRobotLocation().getY();
//如果当前的点是灰尘并且没有被清理
if(map[x][y].equals("*") && !isCleared(new Point(x, y), state.getDirtList())){
State newState = new State();
List<Point> newdirtList = new ArrayList<Point>();
//在新的state中,将灰尘列表更新,即去掉当前点的坐标
for(Point point : state.getDirtList())
{
if(point.getX() == x && point.getY() == y)
continue;
else
newdirtList.add(new Point(point.getX(), point.getY()));
}
newState.setDirtList(newdirtList);
newState.setCost(state.getCost() + 1);
//Fvalue为gvalue和hvalue的和
newState.setFvalue(newState.getCost() + newdirtList.size());
newState.setRobotLocation(new Point(x, y));
//C代表Clean操作
newState.setOperation("C");
newState.setPreviousState(state);
//若新产生的状态与任意一个遍历过的状态都不同,则进入队列
if(!isDuplicated(newState)){
priorityQueue.add(newState);
closeList.add(newState);
cost++;
}
}
//若当前机器人坐标下方有格子并且不是障碍物
if(x + 1 < rowNum)
{
if(!map[x+1][y].equals("#"))
{
State newState = new State();
newState.setDirtList(state.getDirtList());
newState.setRobotLocation(new Point(x + 1, y));
//S代表South,即向下方移动一个格子
newState.setOperation("S");
newState.setCost(state.getCost() + 1);
newState.setFvalue(newState.getCost() + state.getDirtList().size());
newState.setPreviousState(state);
if(!isDuplicated(newState)){
priorityQueue.add(newState);
//加入到closeList中
closeList.add(newState);
cost++;
}
}
}
//若当前机器人坐标上方有格子并且不是障碍物
if(x - 1 >= 0)
{
if(!map[x-1][y].equals("#"))
{
State newState = new State();
newState.setDirtList(state.getDirtList());
newState.setRobotLocation(new Point(x - 1, y));
//N代表North,即向上方移动一个格子
newState.setOperation("N");
newState.setCost(state.getCost() + 1);
newState.setFvalue(newState.getCost() + state.getDirtList().size());
newState.setPreviousState(state);
if(!isDuplicated(newState)){
priorityQueue.add(newState);
closeList.add(newState);
cost++;
}
}
}
//若当前机器人坐标左侧有格子并且不是障碍物
if(y - 1 >= 0)
{
if(!map[x][y-1].equals("#"))
{
State newState = new State();
newState.setDirtList(state.getDirtList());
newState.setRobotLocation(new Point(x, y - 1));
//W代表West,即向左侧移动一个格子
newState.setOperation("W");
newState.setCost(state.getCost() + 1);
newState.setFvalue(newState.getCost() + state.getDirtList().size());
newState.setPreviousState(state);
if(!isDuplicated(newState)){
priorityQueue.add(newState);
closeList.add(newState);
cost++;
}
}
}
//若当前机器人坐标右侧有格子并且不是障碍物
if(y + 1 < colomnNum)
{
if(!map[x][y+1].equals("#"))
{
State newState = new State();
newState.setDirtList(state.getDirtList());
newState.setRobotLocation(new Point(x, y + 1));
//E代表East,即向右侧移动一个格子
newState.setOperation("E");
newState.setCost(state.getCost() + 1);
newState.setFvalue(newState.getCost() + state.getDirtList().size());
newState.setPreviousState(state);
if(!isDuplicated(newState)){
priorityQueue.add(newState);
closeList.add(newState);
cost++;
}
}
}
}
//判断是否已经达到目标,即当前遍历到的state中手否已经没有灰尘需要清理
public static boolean isgoal(State state){
if(state.getDirtList().isEmpty())
return true;
return false;
}
//输出,由最后一个state一步一步回溯到起始state
public static void output(State state){
String output = "";
//回溯期间把每一个state的操作(由于直接输出的话是倒序)加入到output字符串之前,再输出output
while(state != null){
if(state.getOperation() != null)
output = state.getOperation() + "\r\n" + output;
state = state.getPreviousState();
}
System.out.println(output);
//最后输出遍历过的节点(state)数量
System.out.println(cost);
}
//判断节点是否存在,即将state与closeList中的state相比较,若都不相同则为全新节点
public static boolean isDuplicated(State state){
for(State state2 : closeList){
if(State.isSameState(state, state2))
return true;
}
return false;
}
//判断地图中当前位置的灰尘在这个state中是否已经被除去。
public static boolean isCleared(Point point, List<Point> list){
for(Point p : list){
if(Point.isSamePoint(p, point))
return false;
}
return true;
}
} 测试结果与前两种算法比较
我们使用一个6×6的比较复杂的地图来测试。
地图为
@_#*_*
_*#__*
#*__#*
*_#__*
__#*__
_*__#*其中@表示机器人初始位置,*表示灰尘位置,#表示障碍物,_表示空格子。来看结果。
首先是A*算法,注意程序需要运行一段时间才会出结果:
Please Enter Row Number:
6
Please Enter Colomn Number:
6
Please Enter the Elements in row 1:
@_#*_*
Please Enter the Elements in row 2:
_*#__*
Please Enter the Elements in row 3:
#*__#*
Please Enter the Elements in row 4:
*_#__*
Please Enter the Elements in row 5:
__#*__
Please Enter the Elements in row 6:
_*__#*
S
E
C
S
C
S
W
C
E
S
S
C
E
E
N
C
E
E
S
C
N
N
C
N
C
N
C
N
C
W
W
C
42824可以看到遍历的节点数为42824个。
接下来是广度优先搜索算法,程序同样需要运行一段时间才会出结果:
Please Enter Row Number:
6
Please Enter Colomn Number:
6
Please Enter the Elements in row 1:
@_#*_*
Please Enter the Elements in row 2:
_*#__*
Please Enter the Elements in row 3:
#*__#*
Please Enter the Elements in row 4:
*_#__*
Please Enter the Elements in row 5:
__#*__
Please Enter the Elements in row 6:
_*__#*
S
E
C
S
C
S
W
C
S
S
E
C
E
E
N
C
E
E
S
C
N
N
C
N
C
N
C
N
C
W
W
C
56691需要遍历的节点是56691个。可以看出以上两种算法都可以得到最优解,而A*算法需要遍历的节点数要比广度优先搜索少14000个左右。
最后是深度优先搜索。
Please Enter Row Number:
6
Please Enter Colomn Number:
6
Please Enter the Elements in row 1:
@_#*_*
Please Enter the Elements in row 2:
_*#__*
Please Enter the Elements in row 3:
#*__#*
Please Enter the Elements in row 4:
*_#__*
Please Enter the Elements in row 5:
__#*__
Please Enter the Elements in row 6:
_*__#*
S
E
C
S
C
S
S
S
C
N
N
N
E
E
S
S
C
S
W
W
N
N
N
E
E
S
E
S
E
S
C
N
N
C
S
W
N
W
S
S
W
W
N
N
N
E
E
N
N
C
S
S
S
S
S
W
W
N
N
W
C
S
S
E
N
N
N
E
E
S
S
E
N
E
N
C
S
S
W
N
W
S
S
W
W
N
N
N
E
E
N
N
E
S
E
C
S
S
S
W
N
W
S
S
W
W
N
N
N
E
E
N
N
E
E
C
155可以看到深度优先搜索的效率特别高,在只遍历了155个节点的情况下得出了解。但是很显然机器人选择的线路比前两种算法长很多。并不是最优解。
结束语
我在文中说过,A*算法中H值的估算的准确度可以影响到算法的效率,即最终遍历到的节点的数量。遍历的节点数量越少,算法的执行速度就越快。本文中仅仅是把H值估算为剩余灰尘的数量,只是为了说明H值的意义,但是这样估算的准确度较低。在实际应用中,我们可以对H值进行更加准确的估算。比如在这个例子中,有一种思路是计算机器人当前位置与所有灰尘格子的距离的方差。但是这可能仍然不是特别准确,具体的思路和实现读者可以自己进行考虑和斟酌。当然这也是A*算法的最大魅力:工程师可以在不同的情况中对算法进行不同的优化。
更多文章请访问我的博客地址: http://blog.csdn.net/u012907049