Python爬虫之爬取静态网站——爬取各大币交易网站公告(一)
了解爬虫之后,我们也渐渐掌握了根据网站的种类选择不同库来对其进行处理,提取我们想要的东西。
静态网站,我们往往利用requests库提取网站html信息,再通过正则表达式或BeautifulSoup库提取我们想要的信息。
注:本人面向对象目前还在学习,文中一切全为面向过程。
Python版本:Python3.X
运行平台:Windows
IDE:PyCharm
浏览器:Chrome
目标:获取公告标题时间链接,并以时间倒序,只输出本地时间前一天的公告内容。
静态网站
方法:利用正则表达式,requests库。由于这些网站操作几乎一样,此处便只以中币为例。
第一步,根据URL获取网页的HTML信息
利用requests库进行网页爬取。
import requests
if __name__=='__main__':
target = 'https://www.zb.cn/i/blog?type=proclamation'
req = requests.get(url=target)
html = req.content
html_doc = str(html, 'utf-8')
print(html_doc)
运行结果如下:
我们获得了HTML信息,接下来我们将要从中提取我们想要的公告标题时间以及其链接。
这里我们使用正则表达式。
第二步,利用正则表达式提取所需内容
首先同样对网站进行检查,得到如下界面:
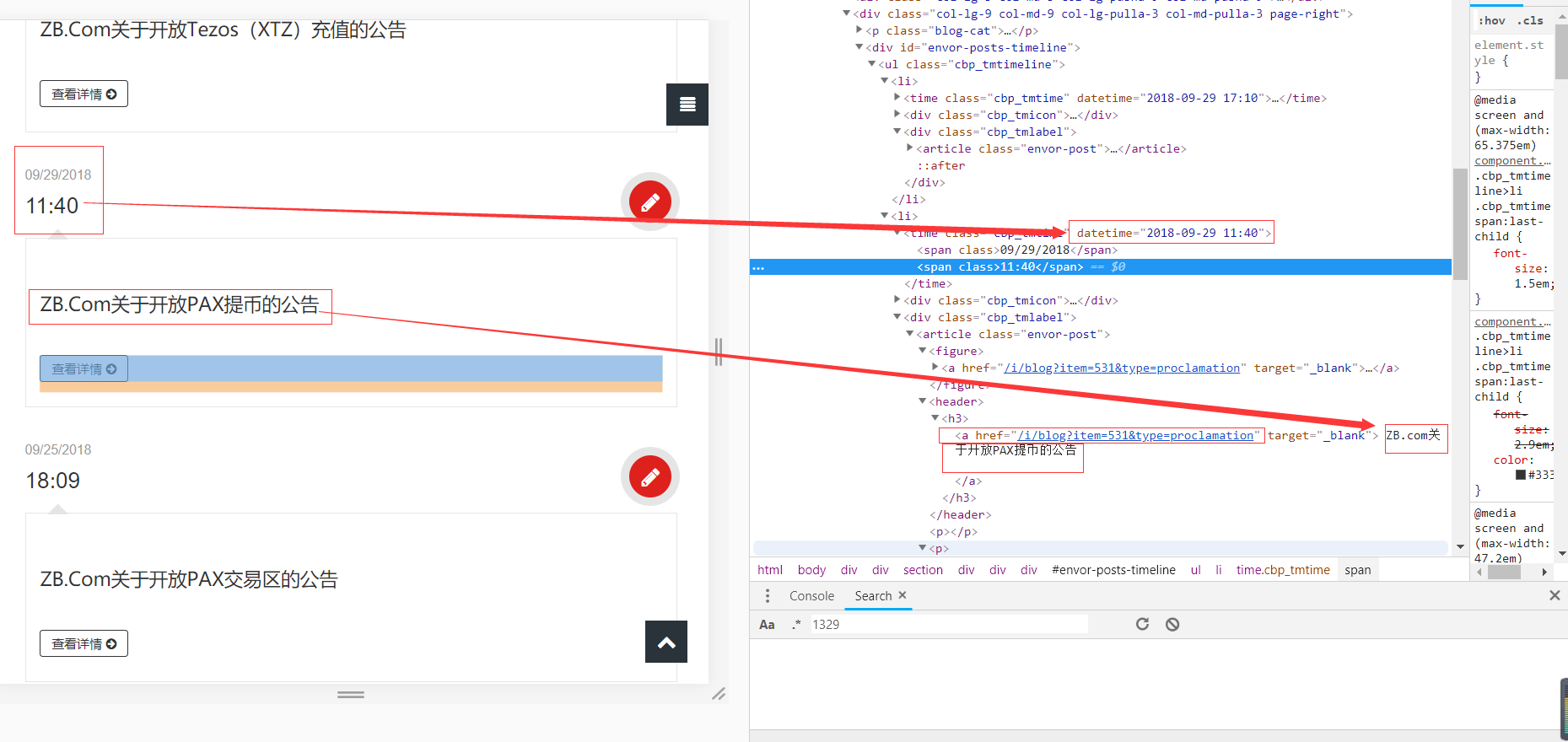
我们可以很清楚的看到我们想要的公告时间标题和链接,接下来就是从这些标签中提取信息了。
根据正则,我们知道我们只要匹配**<a href=“和target=”_blank">**就可以了。然后我们尝试一下:
正则表达式和代码如下:
href = re.findall(r'<a.href="(.*?)".target="_blank">', html_doc)
import requests
import re
if __name__=='__main__':
target = 'https://www.zb.cn/i/blog?type=proclamation'
req = requests.get(url=target)
html = req.content
html_doc = str(html, 'utf-8')
href = re.findall(r'<a.href="(.*?)".target="_blank">', html_doc)
num=len(href)
n=0
while(n<num):
print(href[n])
n=n+1
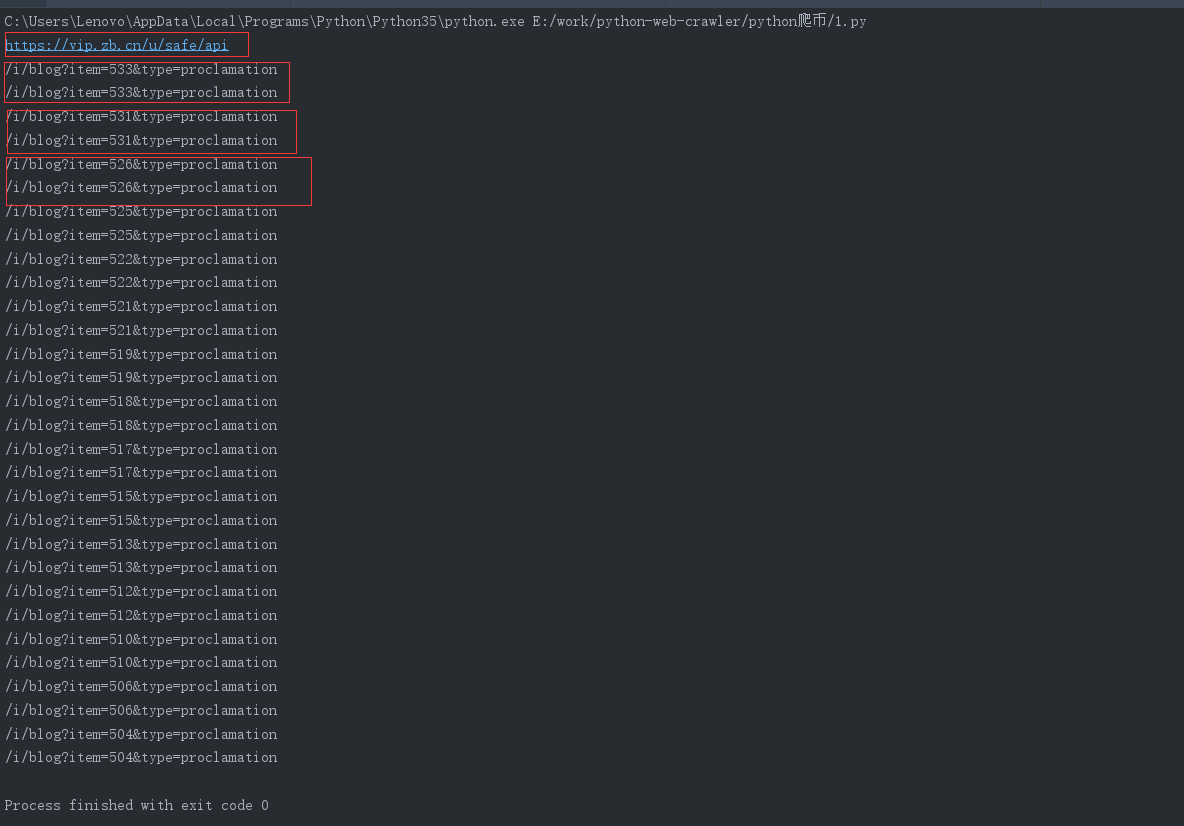
运行得到:
我们检查网站:
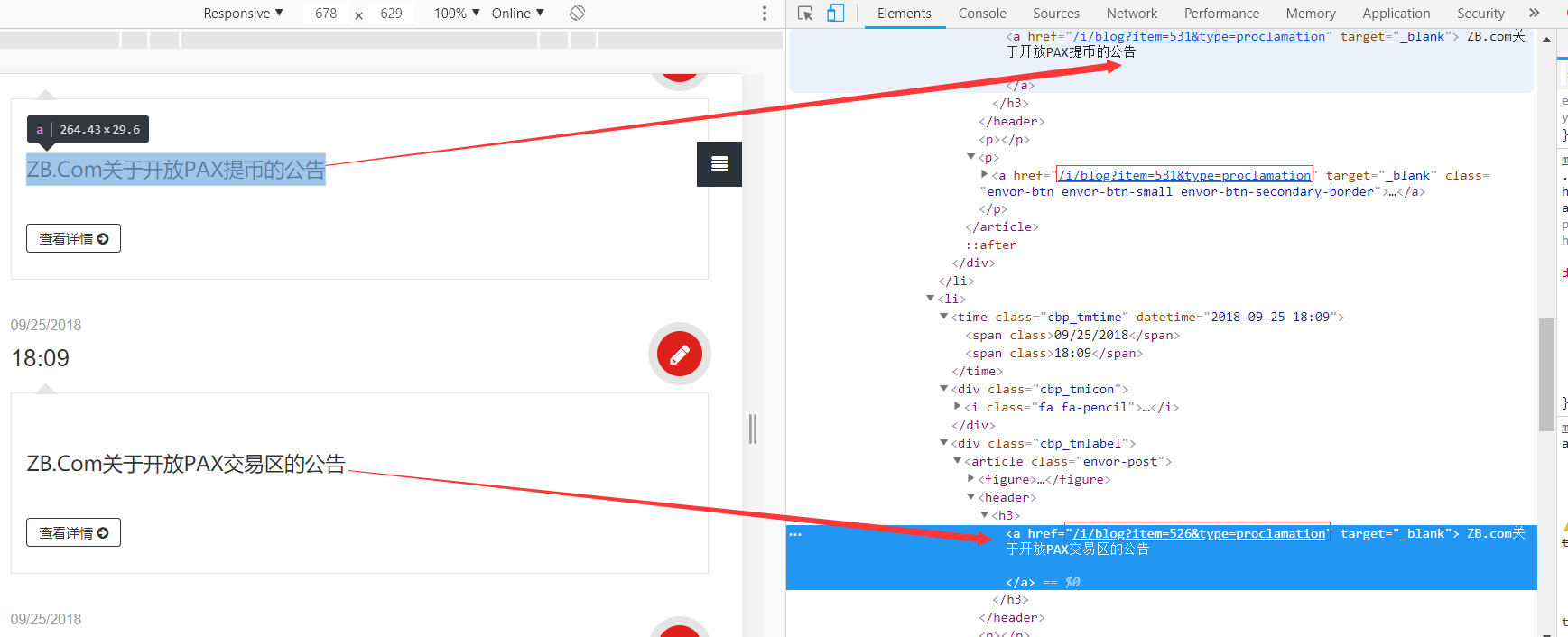
对比发现,我们确实得到了每一个公告的链接,但是每一个链接却是重复出现的,而且运行结果的第一个链接不是我们需要的,那我们接下来就需要更精确的匹配了。
再次检查网站:
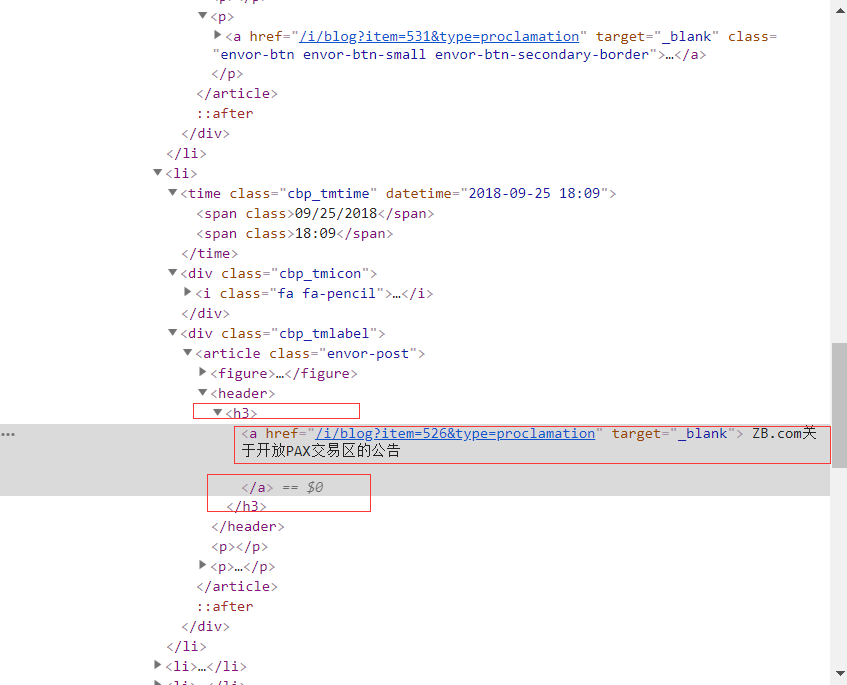
我们看到我们想要的链接和标题全在一个标签下,那我们是不是可以先提取标签的内容再提取其中的链接和标题呢?
尝试一下:
content = re.findall(r'<h3>(.*?)</h3>', html_doc, re.S)
运行得到:

我们发现我们得到了链接和标题,现在需要做的就是进行再次提取。
我们知道findall()提取的是列表,我们现在需要从中提取元素,其中每一个元素包括一个链接和标题。这里我们需要用到循环。
import requests
import re
if __name__=='__main__':
target = 'https://www.zb.cn/i/blog?type=proclamation'
req = requests.get(url=target)
html = req.content
html_doc = str(html, 'utf-8')
content = re.findall(r'<h3>(.*?)</h3>', html_doc,re.S)
a = len(content)
n = 0
while (n < a):
href = re.findall(r'<a href="(.*?)".target="_blank">',content[n], re.S)[0]
href = 'https://www.zb.cn%s' % href
title = re.findall(r'.target="_blank">(.*?)</a>',content[n], re.S)[0]
print(title,href)
n=n+1
运行结果如下:
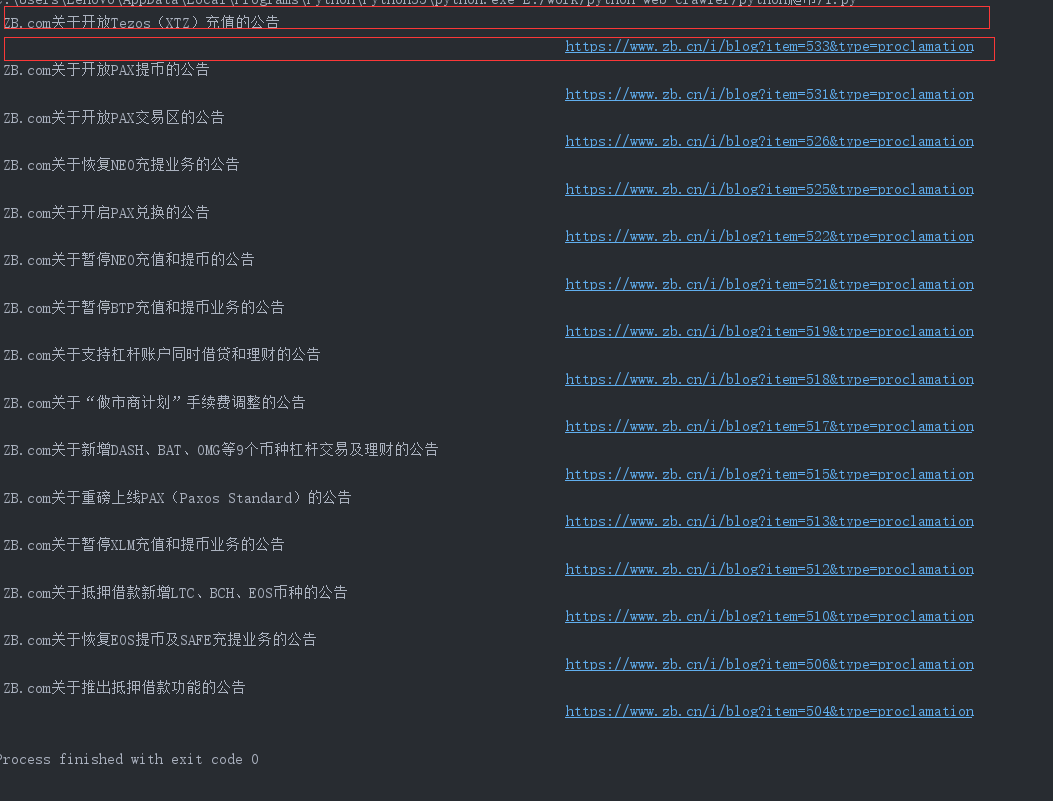
我们发现方法正确,不过标题和链接正好错开一行,接下来利用strip()清除空格换行
将 print(title,href)改成print(title.strip(),href),运行得到:

完成目标。
接下来提取时间,一种是在公告网站再次利用正则提取,另一种便是进入每一条公告链接的网站中进行提取。
我用的是第二种。注:方法很多,欢迎与我交流~
我们已经得到了链接,自然可以再次利用requests库得到每一个链接HTML信息,并利用正则表达式从中获取时间信息。只需要在循环中加入以下代码:
target = href
req = requests.get(url=target)
html = req.content
html_doc = str(html, 'utf-8')
time = re.findall(r'发布时间.<span>(.*?)</span> ', html_doc,re.S)[0]
运行得到:

第三步,提取前一天公告
我们已经将所需内容全部获取,现在只需要提取前一天公告,利用如下代码得到前一天日期:
now_time = datetime.datetime.now() yes_time = now_time + datetime.timedelta(days=-1) yes_time_nyr = yes_time.strftime('%Y-%m-%d')
代码如下:
import requests
import re
import datetime
if __name__=='__main__':
now_time = datetime.datetime.now()
yes_time = now_time + datetime.timedelta(days=-1)
yes_time_nyr = yes_time.strftime('%Y-%m-%d')
target = 'https://www.zb.cn/i/blog?type=proclamation'
req = requests.get(url=target)
html = req.content
html_doc = str(html, 'utf-8')
content = re.findall(r'<h3>(.*?)</h3>', html_doc,re.S)
a = len(content)
n = 0
judge=[]
while (n < a):
href = re.findall(r'<a href="(.*?)".target="_blank">',content[n], re.S)[0]
href = 'https://www.zb.cn%s' % href
title = re.findall(r'.target="_blank">(.*?)</a>',content[n], re.S)[0]
target = href
req = requests.get(url=target)
html = req.content
html_doc = str(html, 'utf-8')
time =re.findall(r'发布时间.<span>(.*?)</span> ', html_doc,re.S)[0]
all=time+title.strip()+href
if yes_time_nyr in all:
print(all)
judge+=all
n=n+1
if(len(judge))==0:
print('本日无公告')
运行结果:

特例(1)
当我们用以上方法爬取比特儿时,我们会发现结果是这样的:

我们发现我们得到的公告是英文,而浏览该网站时,我们却发现公告是中文

观察网站我们发现它还有其他语言版本。
接下来我们对中文版本和英文版本进行比较
用F12热键,找到Network点击XHR,刷新得到:
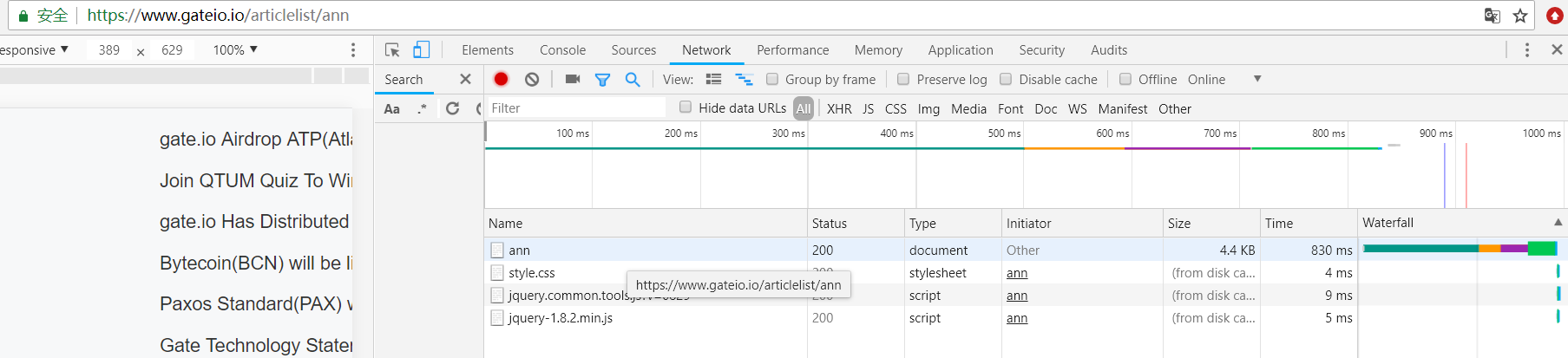
接下来点击ann,进入后会发现如下信息:
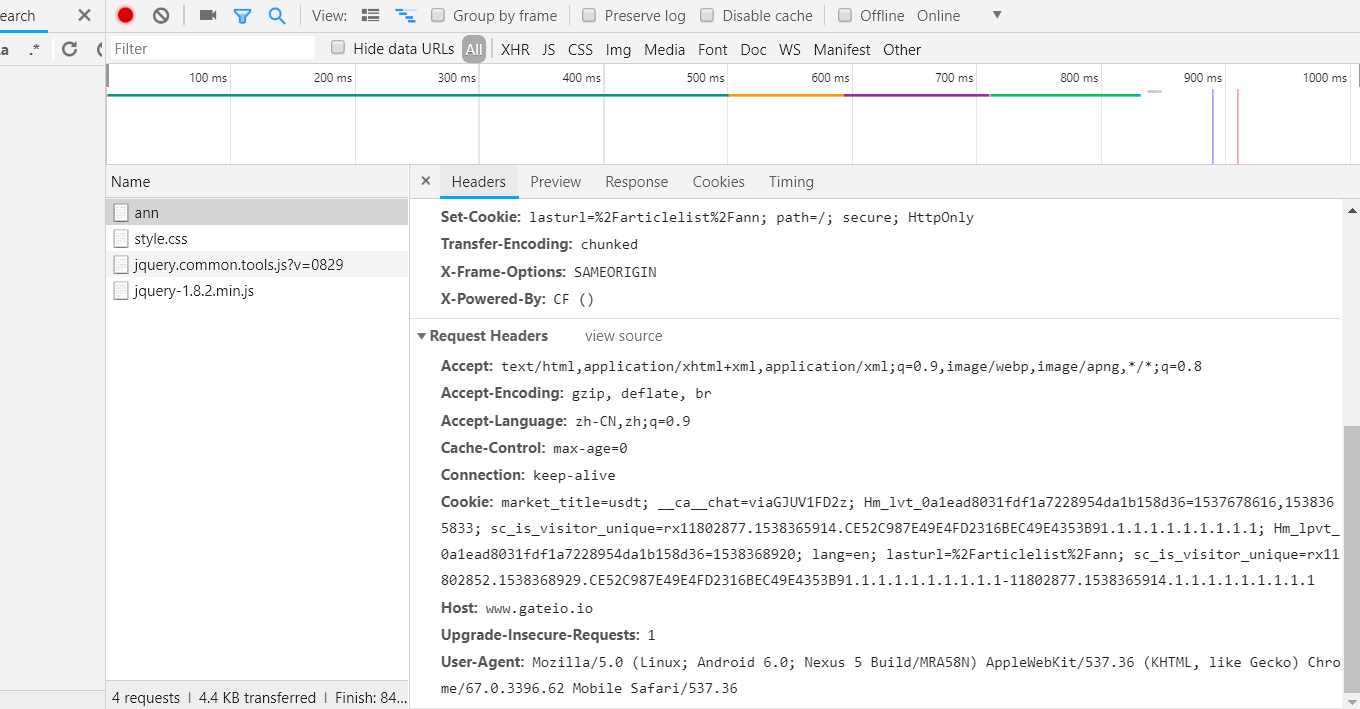
同样我们进入英文版界面得到相同信息。两者对比,我们发现这两个几乎完全相同,只有Cookie不同。
Cookie:
market_title=usdt; __ca__chat=viaGJUV1FD2z; Hm_lvt_0a1ead8031fdf1a7228954da1b158d36=1537678616,1538365833; sc_is_visitor_unique=rx11802877.1538365914.CE52C987E49E4FD2316BEC49E4353B91.1.1.1.1.1.1.1.1.1; Hm_lpvt_0a1ead8031fdf1a7228954da1b158d36=1538368920; lang=en; lasturl=%2Farticlelist%2Fann; sc_is_visitor_unique=rx11802852.1538368929.CE52C987E49E4FD2316BEC49E4353B91.1.1.1.1.1.1.1.1.1-11802877.1538365914.1.1.1.1.1.1.1.1.1
Cookie:
market_title=usdt; __ca__chat=viaGJUV1FD2z; Hm_lvt_0a1ead8031fdf1a7228954da1b158d36=1537678616,1538365833; sc_is_visitor_unique=rx11802877.1538365914.CE52C987E49E4FD2316BEC49E4353B91.1.1.1.1.1.1.1.1.1; lang=cn; lasturl=%2Farticlelist%2Fann; sc_is_visitor_unique=rx11802877.1538370060.CE52C987E49E4FD2316BEC49E4353B91.2.2.1.1.1.1.1.1.1; Hm_lpvt_0a1ead8031fdf1a7228954da1b158d36=1538370061
所以我们猜测可能是因为Cookie的原因,我们尝试一下:
import requests
import re
import datetime
if __name__=='__main__':
now_time = datetime.datetime.now()
yes_time = now_time + datetime.timedelta(days=-1)
yes_time_nyr = yes_time.strftime('%Y-%m-%d')
f = open(r'cookies.txt', 'r')
cookies = {}
for line in f.read().split(';'):
name, value = line.strip().split('=', 1)
cookies[name] = value
target = 'https://www.gateio.io/articlelist/ann'
req = requests.get(url=target,cookies=cookies)
html = req.text
content = re.findall(r'<a href="(.*?).title="(.*?)\d*".target="_blank"',html)
a = len(content)
n = 0
judge = []
while (n < a):
url = content[n][0]
url = 'https://www.gateio.io%s' % url
url = url.replace('"', '')
title = content[n][1]
n = n + 1
target = url
req = requests.get(url=target)
html = req.text
news = re.findall(r'<div class="new-dtl-info">(.*?)</div>', html, re.S)[
0]
time = re.findall(r'<span>(.*?)</span>', news)[0]
all = time + '\t' + title + '\t' + url
if yes_time_nyr in all:
print(all)
judge += all
if len(judge) == 0:
print('本日无公告')
其中cookies.txt文档中存入我们得到的中文版的cookie。
运行得到:
目标完成。
特例(2)
有的网站在爬取后我们会发现得到的时间信息为格林时间,需要自己进行转换,这里给出转换代码如下:
utc = time
UTC_FORMAT = "%Y-%m-%dT%H:%M:%SZ"
utcTime = datetime.datetime.strptime(utc, UTC_FORMAT)
localtime = utcTime + datetime.timedelta(hours=8)
其中time为格林时间。