数据库访问量很小时,数据库无需优化,直接使用即可。

但随着数据量以及访问量越来越高,在人们的智慧中一步步诞生了如下方案:
1、缓存+垂直拆分
使用缓存(Memcached、Redis)来缓解数据库压力【数据库的查询操作次数要远远大于增删改,我们将经常查询的数据放在缓存中,将大大缓解数据库的压力】,优化数据库结构和索引,垂直拆分(当数据量过于庞大,一个数据库放不下,则需要根据需求,例如根据业务进行拆分,业务1、业务2、业务3...)。

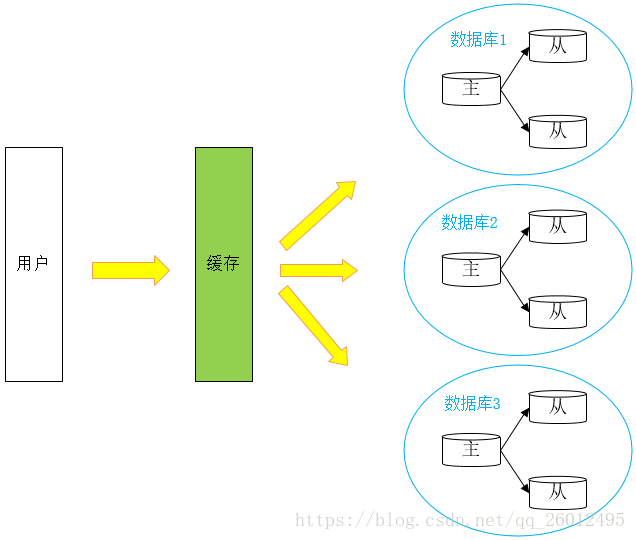
2、主从复制、读写分离
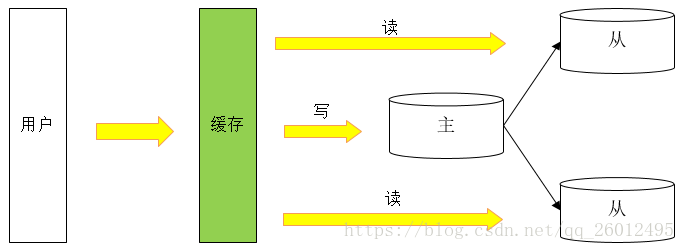
主数据库做动作,从数据库立即做相同动作与主数据库保持一致【主从复制,目的:容灾】。读:查;增删改:写。
读写分离,写的操作都放在主库,然后从库会立刻同步,读的操作都放在从库,减小数据库的压力。
3、分库分表+水平拆分+集群
扫描二维码关注公众号,回复:
3463463 查看本文章

在增加缓存以及主从复制、读写分离基础上,数据库主库写压力开始出现瓶颈。不论多么高配置的数据库,都会有自己的物理上限。
水平分割(包括库内分表 和 分库分表):例如一个600万数据的表,由于数据量大会使性能下降,假设分割成三个表,每个表两百万条。
数据库内分多少张表取决于单张表容量,库内分表能够解决单张表数据很大的查询效率问题,但是无法给数据库的并发操作带来效率上的提高,因为分表的实质还是在一个数据库上进行的操作,很容易受数据库IO性能的限制。
分库分表是将一张表的数据经过算法拆分后,放到不同的库中。例如hash算法。