Mysql索引工作原理
Mysql数据库中的存储引擎(InnoDB),索引及使用
一,存储引擎
Mysql的存储引擎是插件式的存储引擎,是基于表的(意思就是每个表都可以单独设置存储引擎)
主要的存储引擎有:
MyISAM:在5.1以及之前的版本是默认的存储引擎
InnoDB:5.1 开始引入InooDB plugins 5.5后将InnoDB作为默认的存储引擎
MyISam和InnoDB主要区别:
| 特性 | InooDB | MyISAM |
| 事物 | 支持事务,回滚及系统崩溃修复 | 不支持 |
| 锁 | 有行锁 | 有表锁,没有行锁 |
| 插入速度 | 慢 | 快 |
| 内存及使用空间 | 高 | 低 |
| 索引 | 基于聚簇索引的,只可以有一个聚簇索引,二级索引(非主键索引)必须包含主键列 | 采用非聚簇索引 |
| 主键 | 支持自增长列(auto_increment) | 不支持 |
| 存储方式 | 分两种存储方式。表结构(.frm),数据(.innodb_data_home)和索引(.innodb_data_file_path); 第二种就是特有的表结构(.frm)和数据(.db)。 |
表结构(.frm),
扫描二维码关注公众号,回复:
3463254 查看本文章

数据文件(.MYD), 索引文件(.MYI) |
锁:MyISAM可以对整个表加锁,读取时会对读到的表加共享锁,写入时加排他锁。但是在读取查询时可以往表中插入记录(称为并发插入)。
索引:InnoDB不支持full text类型的索引,而MyISAM对blob和text等长字段,可以基于其前500个字段创建索引,MyISAM也支持全文索引。
存储结构:MyISAM类型的表支持三种不同的存储结构:静态型、动态型、压缩型(具体的区别在这不做解释),所以空间少,查的快
一个不准确的说法:查找频繁的表使用MyISam,例如商品表;写多读少,事务要求高的情景使用InnoDB,例如订单表。
二,索引是如何实现快速查找的
索引就是数据结构,索引一般使用Balance Tree(平衡树) 和Hash,此例中使用B+Tree存储。
使用hash检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根结点到枝结点,最后才能访问到叶结点这样多次的IO访问,
所以 Hash 索引的查询效率要远高于 B-Tree 索引,但是hash有以下的缺点:
1,Hash 检索仅能满足“=”,“IN”,“<=>” 查询,不能使用范围查询,因为 Hash 索引比较的是进行 Hash 运算之后的 Hash 值,所以只能等值的过滤。
2,Hash 不可以排序
3,Hash 索引在任何时候都不能避免表扫描
4,Hash 索引遇到大量Hash值相等的情况后性能并不一定就会比B-Tree索引高
关于B,B+,Hash几种数据结构http://blog.csdn.net/wl044090432/article/details/53423333
MyISM引擎实现图解:
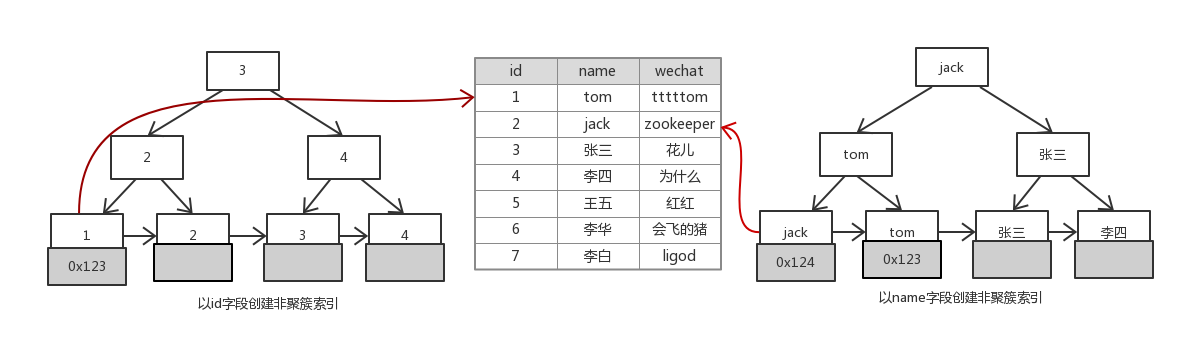
MyISM使用非聚簇索引,索引存在.MYI文件里,数据存在.MYD文件里;
在B+Tree中只有叶结点存储数据地址,其他结点只存索引列的数据;
上图创建的一个degree(度,结点拥有的子树个数)为2的索引中(即指针域的个数是2),如果B+Tree有10行,那么在使用索引的情况下,最多会只查询10次,但是如果没有使用索引,最多会查询2∧(10-1)次。
select id from user where id = ? 可以直接从索引里取数据;
select * from user where name = ?通过name索引获取数据行的地址进而获取数据
InnoDB引擎实现图解:
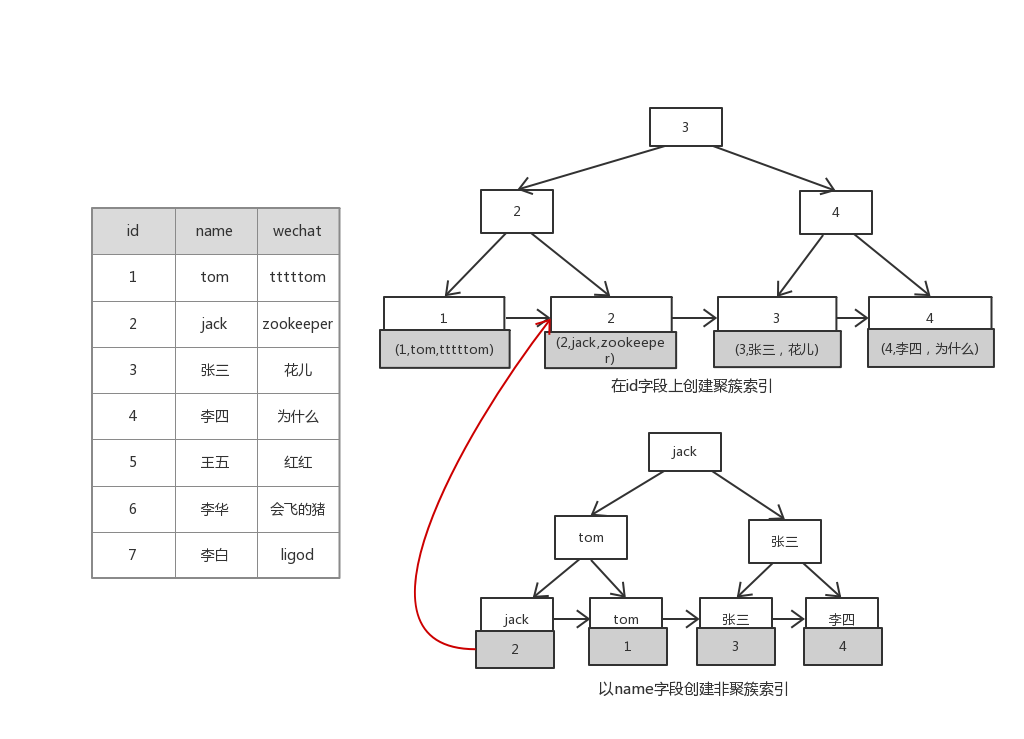
InnoDB使用聚簇索引组织数据,聚簇索引保存主键和其他字段的值,非聚簇索引保存索引列的值及聚簇索引列的值;
select id,name,wechat from user where name = ?
先检查有没有name这个索引,再从name索引获取聚簇索引的key,最后从聚簇索引获取其他字段;
索引可以提高检索速度,降低磁盘的IO,且索引是有序的无需再排序,可以降低CPU的负荷;
但是索引存储需要空间,索引实际上就是一张表,字段更新(insert,update,delete)需要维护索引,所以会有性能损耗;
InnoDB的主键一般设置为自增长的且不宜太长,因为自增长的主键插入b+tree时是不需要打乱树的顺序,不仅速度快,还能减少碎片的产生,
而且非聚簇索引里都会存储主键的值,如果主键字段太长(例如使用uuid这样的主键策略)会导致容量增大;
适合建索引的情况:
1,频繁作为where条件的字段
2,关联字段需要建索引,例如外键
2,order by 的字段可以建索引(group by也可以,因为group by之前都会按照这个字段先排序)
但是:频繁更新,where条件里用不到,或者分布均匀(例如男,女)的字段不适合建索引
在以上例子里索引生效和失效的情况:
select * from user order by name name索引生效
创建如下复合索引:
index_name_wechat(name,wechat)
select * from user order by wechat 索引失效
select * from user where wechat = ‘23’ and name = ‘alili’ 索引失效
select * from user where name = ‘alili’ and wechat = ‘23’ 索引生效
select * from user where name > ‘alili’ and wechat = ‘23’ 索引一半生效,只会用到name的索引,因为name索引已经排序了。