最近在看python数据结构,对字典有了新的认识,mark一下。
python的数据类型,以列表和字典的使用最为广泛,其中列表以其强大的增删改查,备受人们的青睐,我个人也特别喜欢列表。但当列表数据过多时,需要查询第n个数据,其性能则为O(n),此时字典就登场了,以其强大的底层结构,可以做到查询为O(1),即常量查询,那原因是什么呢?
字典的底层结构
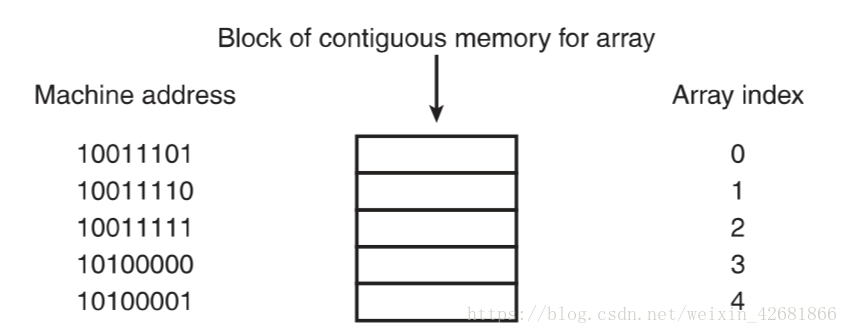
说到字典的底层结构,实际上是个散列表,那什么是散列表?实际上就是个稀疏数组(总是有空白元素的数组)。这里普及下数组的概念,数组最大的特点是 不管数组有多大,他访问第1项和访问最后一项所需的时间是相同的,原因是数组中的每个元素都有其对应的内存地址,每次存入时,会存入连续的内存地址(如图所示),一般默认第一项为基本地址,则 其他项都能通过基本地址+偏移量来读取,因此读第n项速度也为O(1)。但缺点是数组在定义时就规定了大小,所以后续的增加元素一旦达到了规定的阈值,则需要进行空间的扩容,而这个阈值一般是数组仅剩1/3空白占位时。【表1-1】
回到字典,散列表的底层是稀疏数组,其内部元素单元称为表元,而表元则分为value和key,value可以是任意值,但key必须是散列值(相当于数组中元素的内存地址),那散列值的存在需要满足两个条件,其一是必须有__hash__魔法方法,该方法的作用是将每个存入的键值对的key转为hash值,也称为散列值,其二是必须有__eq__魔法方法,其作用是保证每个key都不能相同(表2-1/2-2是我截取的字符串关于这两个魔法方法的描述)。而有这两个方法的基本就是不可变对象:如str/int等等,为什么说基本呢?因为不可变对象中元组不一定满足,当元组内嵌套列表时,此时则不是一个散列值,如果当作key,则会报警unhashable type(如表3-1)
【表2-1】
【表2-2】
【表3-1】
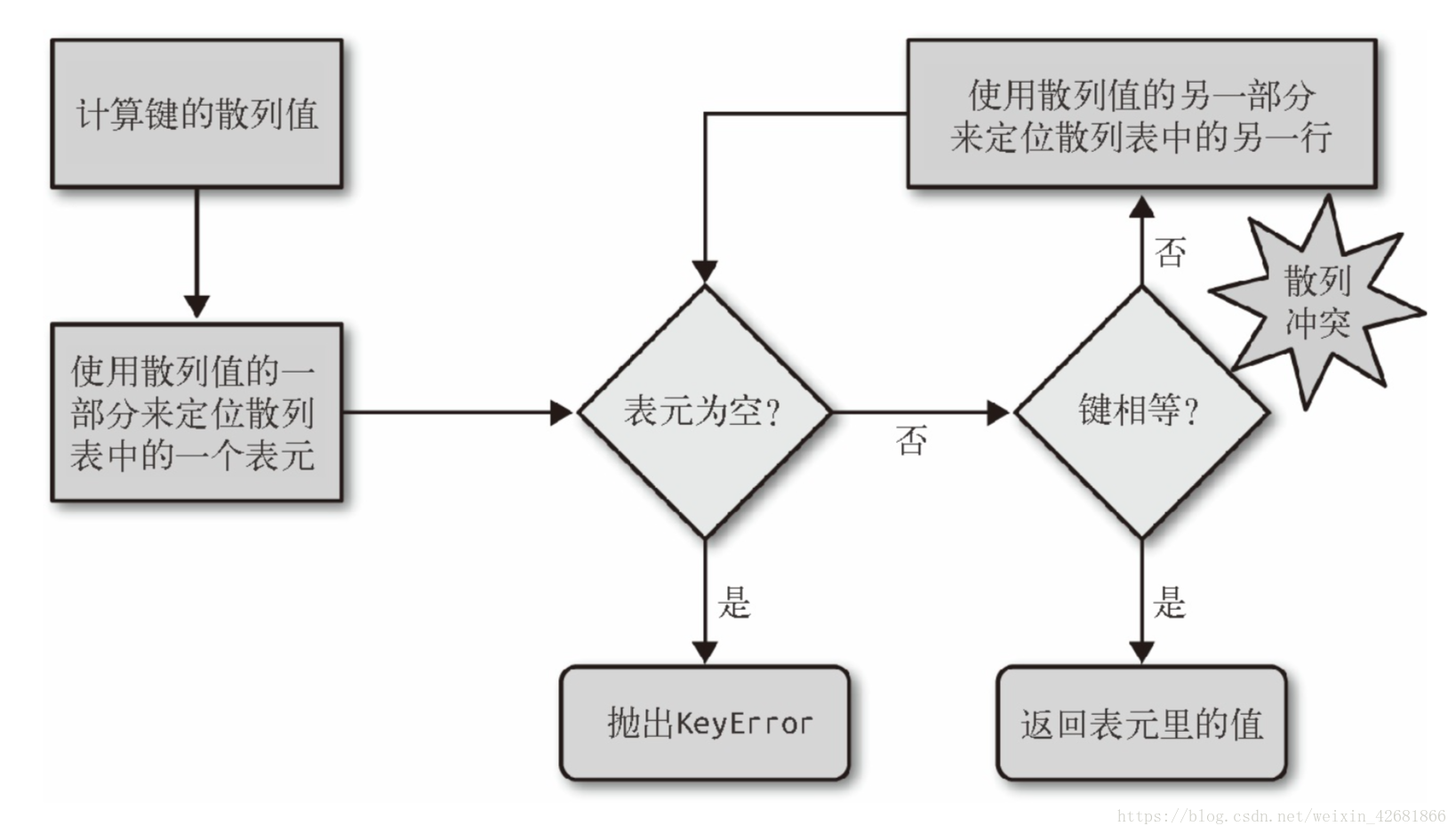
讲解完了散列表的构成,此时来说明下散列表的算法,当我们在查询key时(即dict[key]),此时python会先将key转换为对应的hash值,把这个值最低的几位数字作为偏移量来查找表元,找不到则报KeyError,找到了比较表元中的key和所查找的是否一致,一致则返回对应的value。但有个问题,此时可能会出现表元找到了,但key对不上的情况,这称之为散列冲突。散列冲突的解决方法很简单,就是python将查询的hash值再重新取部分来查找,如果找不到表元,则报错,找到了,再判断key是否相等,相等则返回;或者又发现了散列冲突,则重复以上步骤,相关流程如表4-1。
【表4-1】



无序的字典
经过以上两部分的讲解,对于字典的实现原理有了初步的了解,懂了字典的快实际上就是数组的特性。那为什么会是无序的呢?这实际上是两方面的原因构成,分别是数组的特性和散列冲突的特性。在说明这两个原因之前,先说个概论,字典的快是建立在用空间换时间,切记!还记得之前说的,数组缺点是在创建时规定了大小,当其空白占位达到其大小的1/3时,python会重新引入一个更大的空间,此时会将原有空间的元素一一拷贝,再将新增的元素一一拷贝进去,所以这会造成巨大的空间浪费,同时在产生新空间的同时,会同步规划元素的hash值(hash值会变得更大),此时由于hash值的不同,则可能导致键的次序不同。另一个原因则是散列冲突,当添加新建的时候发现散列冲突,则新键可能会被安排到另一个位置,于是添加的元素可能就会跑到前方去了。以上就是关于无序的字典解释。
参考文献
- 《数据结构—python语言描述》
- 《流畅的python》