想要搞清这个问题要从mysql和ES的索引数据结构下手,咱们先了解一下mysql的索引结构,然后再了解一下ES的索引结构,然后再进行对比这个问题就会很清楚了。
mysql关系型数据库索引原理:
数据库的索引是B+tree结构
主键索引是聚合索引,其他索引是非聚合索引
聚合索引:
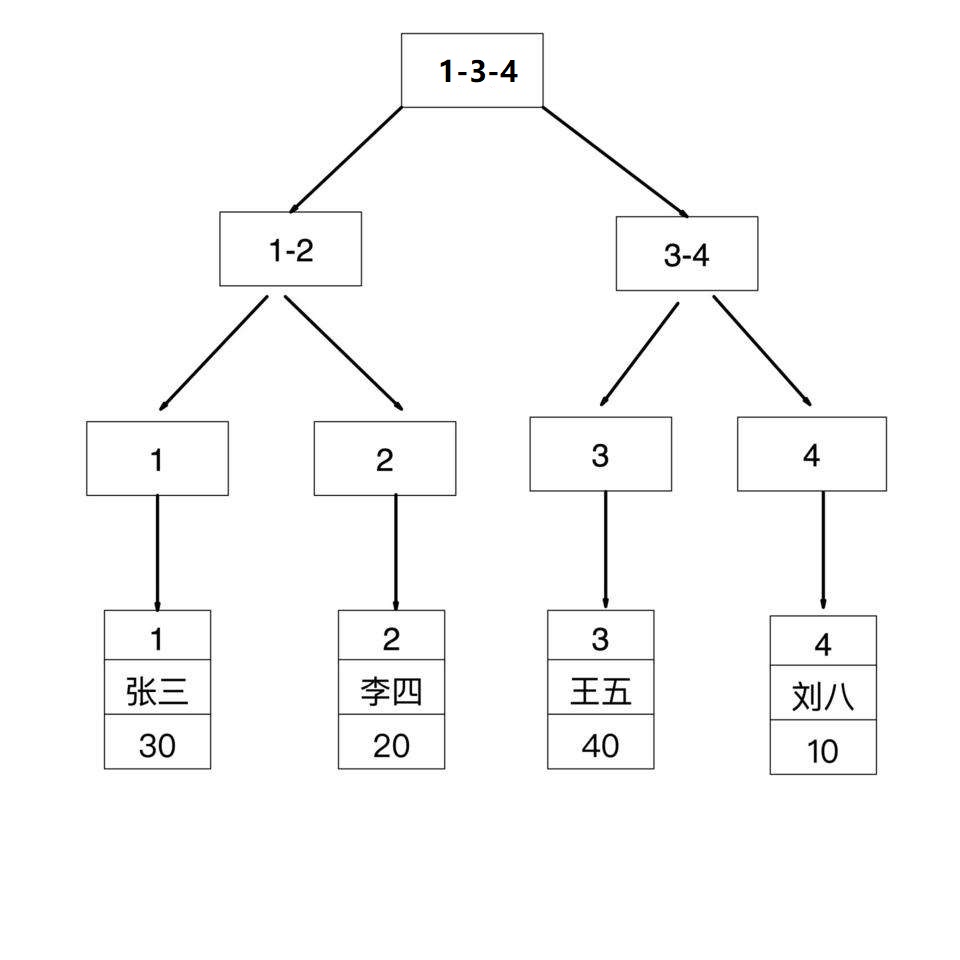
可以通过主键直接找到数据。
非聚合索引:
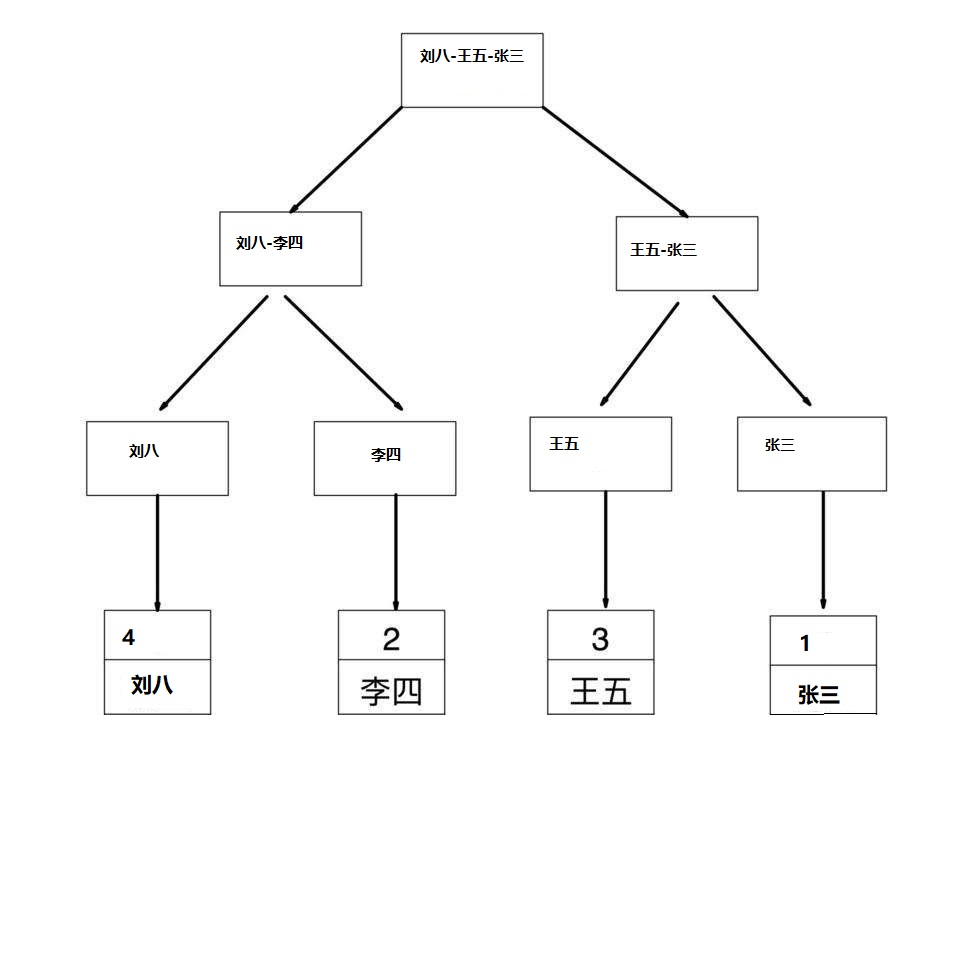
如果mysql根据非聚合索引去查询数据,首先要通过非聚合索引找到对应的主键id,再去根据主键id走聚合索引找到数据

Elasticsearch倒排索引原理:
在将倒排索引之前咱们先说一下正向索引
正向索引的结构就是每个文档和关键字做关联,每个文档都有与之对应的关键字,记录关键字在文档中出现的位置和次数。但是用户查询的时候是根据关键字去查询的。当用户想要查询“iPhone”,这时候会扫描所有文档找出包含iPhone的文档,可想而知当线上数据量非常庞大的情况下,这样的索引结构根本无法满足实时返回排名结果的要求。
倒排索引
倒排索引是根据关键词去查找文档的id,每个关键词都会有与之对应的文档id。倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由三个部分组成:“单词词典”、“排序列表”和”“倒排文件”。
单词词典(Lexicon):搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
两者对比:
第一种情况:
基于分词后的全文检索:例如select * from test where name like '%张三%',对于关系型数据库mysql来说简直是一种灾难,因为会进行全表检索,但是对es而言分词后,每个字都可以利用FST高速找到倒排索引的位置,并迅速获取文档id列表,大大的提升了性能减少了磁盘IO。
第二种情况:
精确检索:进行精确检索,有些时候可能mysql要快一些,当mysql的非聚合索引引用上了覆盖索引,无需回表,则速度上可能更快,但是es还是通过FST找到倒排索引的位置比获取文档id列表,再根据文档id获取文档并根据相关度进行排序。但是es还有个优势,就是es即天然的分布式使得在大量数据搜索时可以通过分片降低检索规模,并且可以通过并行检索提升效率,用filter时更是可以直接跳过检索直接走缓存