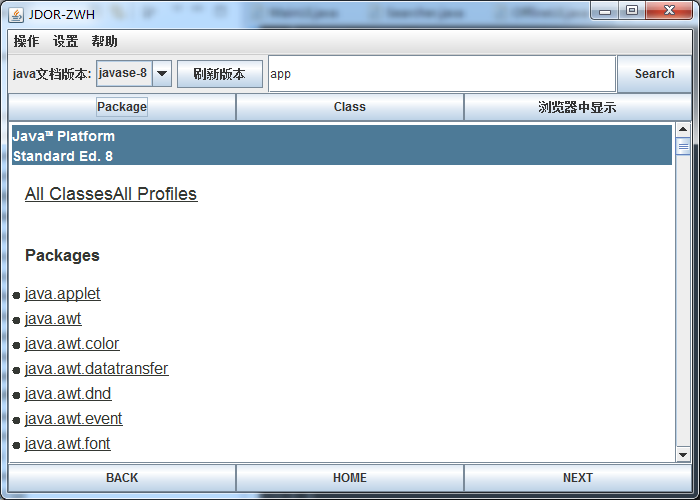
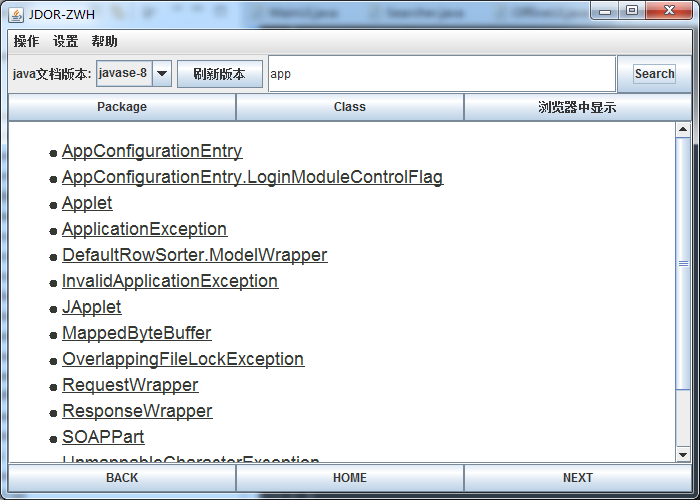
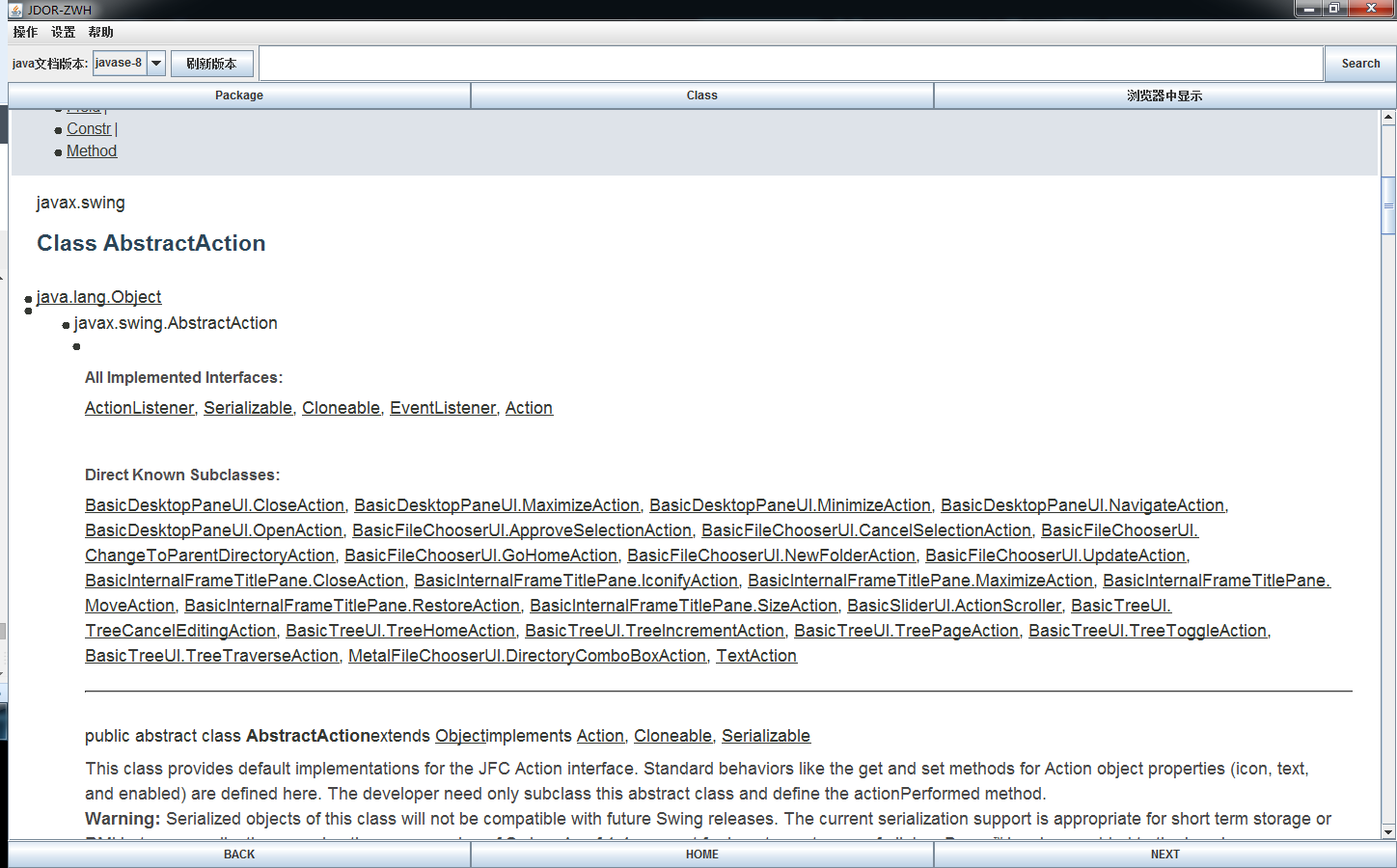
写java程序的时候,经常要到官网(http://docs.oracle.com/javase/8/docs/api/index.html)查文档,用着用着感觉有时有些不方便:
1.java官网有时登不上去
2.没有搜索查询功能
所以针对这两个,就想到做一个文档离线查询器,把文档离线下来,然后可以进行搜索查找。(代码依然写得乱。。。)
项目介绍:
项目名称:java文档离线下载器(JDOR)
exe文件下载:
本地电脑具有jdk 1.8版本的(需要配置好java系统环境):
下载地址:http://download.csdn.net/download/name_z/9459596
本地环境没有配好的,可以下载jdk1.8的jre包,放到该exe所在文件夹便可使用(jdk1.8的jre包有180多兆,太大,传不上来)
使用环境:windows
程序分析:
下载组件、流程分析:
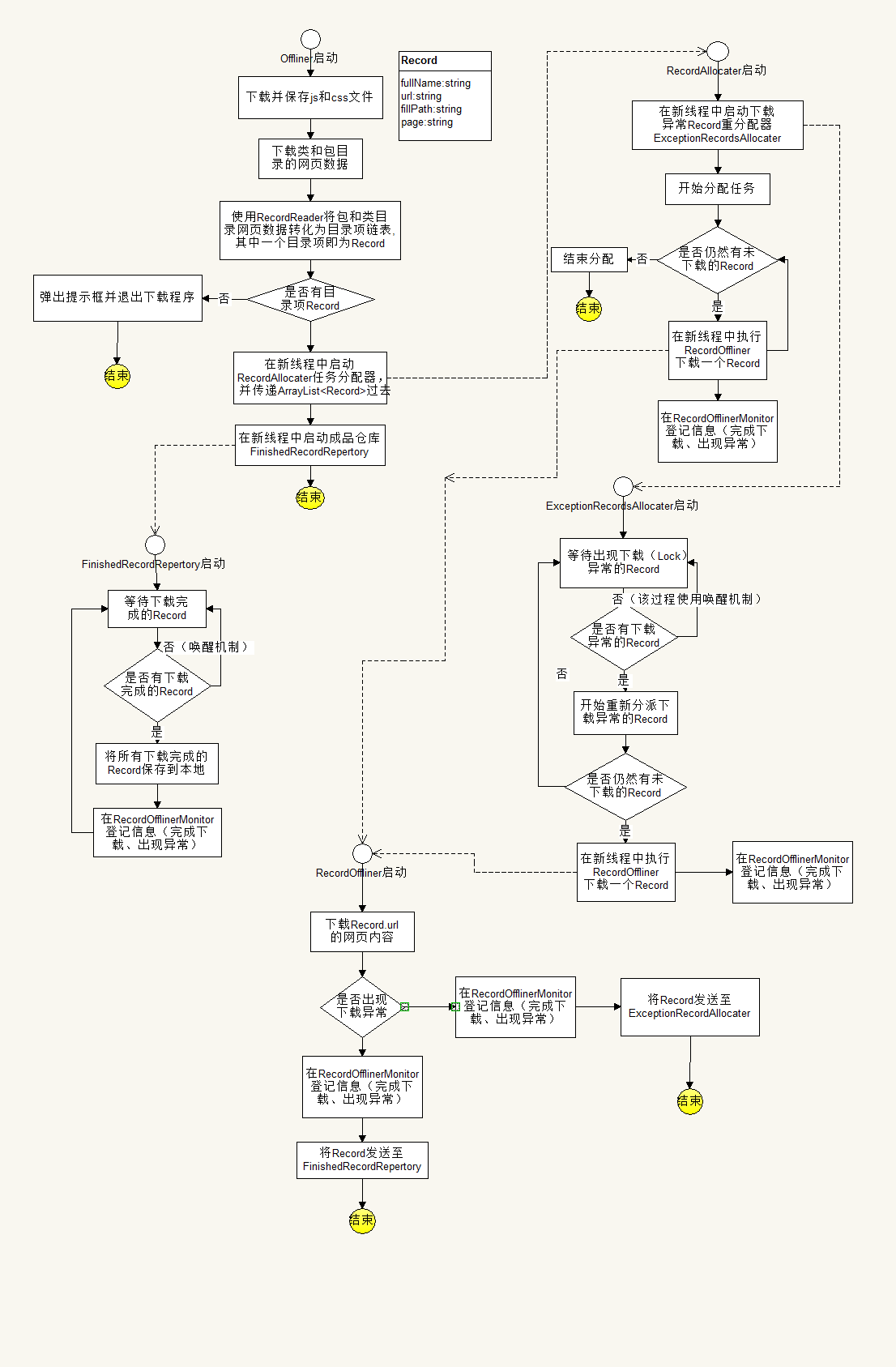
Record:
Record作为数据的集合,用于在各组件之间传递
/**
*
* 保存一条数据记录(一个包或一个类)的类
*
* url:string 网址(离线时是在线网址,查询时是本地网址)
* filePath:string 本地文件保存地址
* papge:string 网页数据(html源码)
* fullname:string 包名或类名
* isclass:boolean 是否为类
*
* @author zwh
* @version 1.0
*/
public class Record
{
public String url = "";
public String filePath = "";
public String page = "";
public String fullName = "";
public boolean isClass = false;
}Offliner下载器:
流程图:
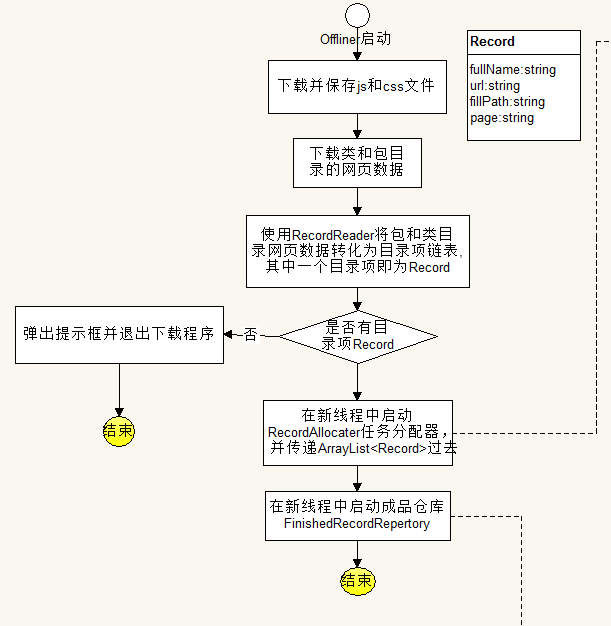
解析:
功能:
Offliner下载器是下载总组件,主要任务是为外部提供调用接口,内部启动、调用其它的组件完成下载任务。
//开始下载
public void offline(String version);
//获取总共需要下载的Record的数量
public int getTotalRecords();
//设置下载速度
public void setOfflineSpeed(SPEED speed);RecordAllocater任务分配器:
流程图:
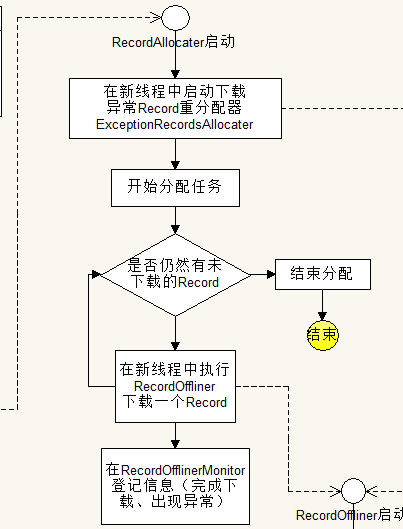
解析:
功能:
将传递进来的未下载的Record分派给RecordOffliner执行任务下载(多线程),以及启动异常Record重分派器。
分析:
由于采用循环列表创建线程执行任务,因此采用线程池可以更方便的进行管理:
public class RecordAllocater extends Thread
......
//该线程池会动态的增加、删除线程
private ExecutorService threadPool = Executors.newCachedThreadPool();
......
public void allocate()
{
for (Record record : this.nonOfflineRecords)
{
//offliner继承了Thread
RecordOffliner offliner = new RecordOffliner(record);
//直接调用线程池的execute方法启动新线程
this.threadPool.execute(offliner);
//登记信息:创建了一个新的下载线程
RecordOfflinerMonitor.createARecordOffliner();
/*
*用于控制下载速度,如果time==0,就会在短时间内创建了大量线程,对目标网站进行访问,
*容易造成目标网站封禁IP不能登录
*/
try
{
sleep(time);
} catch (InterruptedException e)
{
e.printStackTrace();
}
}
//在UI处显示信息
OfflineUI.appendOfflineExceptionMessage("RecordAllocater分派任务完成");
}
......ExceptionRecordAllocater任务分配器:
流程图:
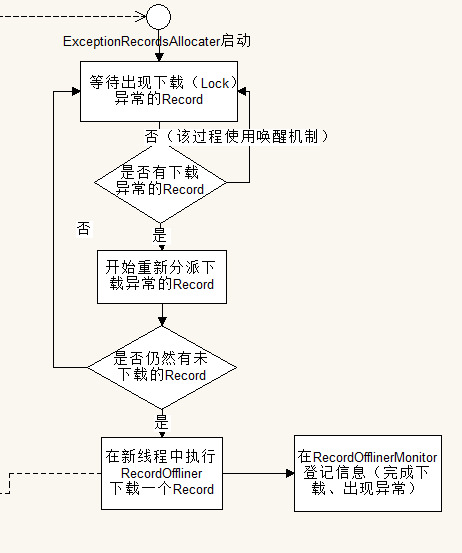
解析:
功能:
ExceptionRecordAllocater实际上是RecordAllocater的内部私有类,由RecordAllocater负责启动,当RecordOffliner下载过程中出现异常(由于短时间内大量线程对目标网站的访问导致的IP暂时被封禁)的时候,Record将被发送到RecordAllocater的静态变量exceptionRecords队列中,这时将唤醒ExceptionRecordAllocater对这些下载异常的Record重新分派。
//由于是并发访问,因此要使用线程安全的ConcurrentLinkedQueue<Record>
private static ConcurrentLinkedQueue<Record> exceptionRecords = new ConcurrentLinkedQueue<Record>();
......
/**
*
* RecordOffliner调用该方法发送异常Record
*
* @param record:下载异常的Record
*/
public static void exceptionRecord(Record record)
{
RecordAllocater.exceptionRecords.add(record);
synchronized (lockNewRecord)
{
//唤醒沉睡的ExceptionRecordAllocater
lockNewRecord.notifyAll();
}
}
......
private class ExceptionRecordsAllocater extends Thread
{
@Override
public void run()
{
while (true)
{
//当没有异常Record加入时,会一直陷入沉睡状态
synchronized (lockNewRecord)
{
try
{
lockNewRecord.wait();
} catch (InterruptedException e)
{
e.printStackTrace();
}
}
//UI处显示信息
OfflineUI.appendOfflineExceptionMessage("ExceptionRecordsAllocater唤醒,开始将发生下载错误的Record重新分派");
/*
*这时线程已被唤醒(一定存在异常Record),而且可能存在多个异常Record(其它线程在执行的时候也出现了异常)
*因此需要遍历exceptionRecords
*/
while (!exceptionRecords.isEmpty())
{
Record record = exceptionRecords.poll();
if (record != null)
{
//启动线程执行,依然使用RecordAllocater的线程池
RecordOffliner offliner = new RecordOffliner(record);
threadPool.execute(offliner);
RecordOfflinerMonitor.createARecordOffliner();
//由于这些是异常Record,增大分派时间间隔,确保这次成功的几率
try
{
sleep(500);
} catch (InterruptedException e)
{
e.printStackTrace();
}
}
}
OfflineUI.appendOfflineExceptionMessage("发生下载错误的Record分派完成,ExceptionRecordsAllocater陷入沉睡");
}
}
}RecordOffliner任务下载器:
流程图:
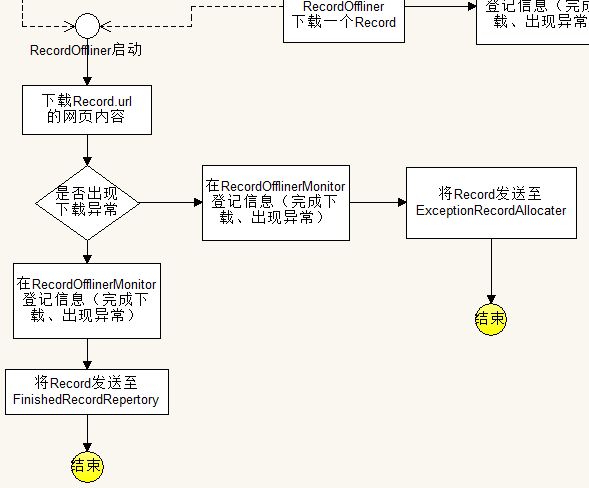
解析:
作为下载任务的最终执行者,每个RecordOffliner负责下载一个Record指定的页面。
/**
* 下载过程出现异常(爬取过程出现的异常),
* 将在OfflineUI中显示异常信息,并将Record重新交给RecordAllocater重新分配,最后将在
* RecordOfflinerMonitor登记信息;如果正常下载完,将发送给FinishedRecordRepertory,并
* 在RecordOfflinerMonitor登记信息
*/
@Override
public void run()
{
try {
//爬取指定url的页面
this.record.page = Crawler.crawl(this.record.url);
} catch (Exception e) {
OfflineUI.appendOfflineExceptionMessage(record.fullName + ":离线过程中出现网络异常,被送入ExceptionRecordsAllocater");
//出现异常,将Record发送给RecordAllocater(ExceptionRecordAllocater)重新分派
RecordAllocater.exceptionRecord(record);
//在RecordOfflinerMonitor处登记信息
RecordOfflinerMonitor.ARecordOfflinerException();
}
//成功下载完,因此将Record发送给FinishedRecordRepertory完成最后保存到本地的任务
FinishedRecordRepertory.add(this.record);
//登记信息
RecordOfflinerMonitor.finishARecordOffliner();
}FinishedRecordRepertory成品仓库:
流程图:
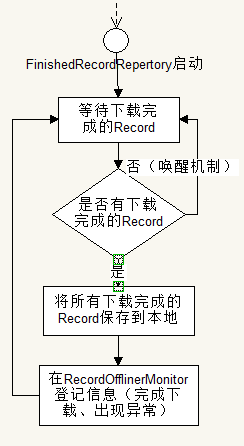
解析:
负责将成功下载的Record保存到本地。
是一个“静态类”,只需要用到它的静态方法,它运作与ExceptionRecordAllocater的运作相似,先是等待,被唤醒后,运行把所有Record保存到相应的地址。
/**
* 当没有Record需要保存时,陷入睡眠状态,每当有Record加入,将被唤醒
* 然后执行保存工作,若保存工作出现异常,将Record重新加入到保存列表中
*/
@Override
public void run()
{
while (true)
{
//等待新Record加入
if (FinishedRecordRepertory.records.isEmpty())
{
try
{
synchronized (FinishedRecordRepertory.lockNewRecord)
{
FinishedRecordRepertory.lockNewRecord.wait();
}
} catch (InterruptedException e)
{
e.printStackTrace();
}
}
//被唤醒,开始执行任务
while (!FinishedRecordRepertory.records.isEmpty())
{
Record record = FinishedRecordRepertory.records.poll();
//启动新线程执行
FinishedRecordRepertory.threadPool.execute(new Thread(new Runnable()
{
@Override
public void run()
{
//实际的执行方法
writeToFile(record);
}
}));
}
}
}在保存过程中依然可能会出现异常:
1.创建文件失败
2.写入数据失败
为此依然要做好准备工作
private static void writeToFile(Record record)
{
synchronized (lock)
{
FinishedRecordRepertory.nonFinishedRecordNumber--;
}
//文件创建失败,将Record重新加入队列中等待
if (!FileManager.isExit(record.filePath))
if (!FileManager.createFile(record.filePath))
{
records.add(record);
OfflineUI.appendOfflineExceptionMessage(record.fullName + "文件创建失败,加入队列等待");
}
//文件写入失败
if (FileManager.cover(record.filePath, record.page))
{
OfflineUI.appendOfflineSuccessMessage(record.fullName + ":离线成功");
return;
}
//将Record重新加入队列
records.add(record);
OfflineUI.appendOfflineExceptionMessage(record.fullName + "文件写入失败,加入队列等待");
}查询组件分析:
前面说过了下载组件,而我们的程序下载完后就是查询、显示。
现在来说的查询组件比较简单,因为下载的时候,我们已经把目录文件也下载了下来,因此直接读取目录文件使用RecordReader(下面数据分析中介绍)转化为Record格式保存,便可以很方便进行查询。
然后为了可以进行模糊查询,因此没有使用二分搜索,而是直接循环查询,查询也是很快,因为数据最大也就是4、5千,而耗时较多的是读取目录并进行解析转化的过程。
//在类目录中查找
public ArrayList<Record> searchClass(String target)
{
return this.search(target, true);
}
//在包目录中查找
public ArrayList<Record> searchPackage(String target)
{
return this.search(target, false);
}
private ArrayList<Record> search(String target, boolean isClass)
{
//确定后需要查询的目录
ArrayList<Record> temp = this.packageRecords;
if (isClass)
temp = this.classRecords;
ArrayList<Record> result = new ArrayList<Record>();
//因为不是精准查询,所以需要循环所有目录项
for (Record record : temp)
{
//模糊查询,只要包含目的字符串,变加入到结果中返回
if (record.fullName.toLowerCase().contains(target.toLowerCase()))
result.add(record);
}
return result;
}浏览组件分析:
网页内容在程序内的显示:
JEditorPane是swing组件,使用方便,但是效果不好(最后面有程序使用的截图),因此程序中特地提供了在浏览器打开网页的按钮,方便观看
private JEditorPane edpDisplayHtml = new JEditorPane();
private JScrollPane scrollHtmlDisplay = new JScrollPane(this.edpDisplayHtml);
......
private void setHtmlDisplay()
{
this.edpDisplayHtml.setContentType("text/html");
this.edpDisplayHtml.setEditable(false);
//让网页中的超链接可使用
this.edpDisplayHtml.addHyperlinkListener(this);
}
......
@Override
public void hyperlinkUpdate(HyperlinkEvent e)
{
if (e.getEventType() == HyperlinkEvent.EventType.ACTIVATED)
{
this.displayHtmlPage(e.getURL().toString());
//historyManager是用来管理浏览历史,用于前进后退,下面会介绍
this.historyManager.add(e.getURL().toString());
}
}ExploreHistoryManager浏览记录的前进、后退:
本程序支持在持续中显示内容,因此就会存在一个浏览记录的问题,而本程序也提供了一个类似于浏览器的前进、后退功能。
历史记录的数据结构为:
//ExploreHistoryManager私有类
private class HistoryRecord
{
public String record = "";
public int no = 0;
public HistoryRecord(String record,int no)
{
this.no = no;
this.record = record;
}
}算法解析:
浏览的网页按照先后顺序递增编号,
当后退时,从链表的最后(也就是当前网页)开始往前走,当遇到的第一个编号小于当前网页的,即为前一个网页,这时把该网页(编号不变,且原来位置的而依然保留)直接加入到链表尾端成为新的当前网页。
当前进时,和后退差不多,唯一不同就是判断的标准,这时不是小于,而是应该第一个大于当前网页编号的为前一个网页,这时把该网页**原
封不动地复制**到链表尾端成为新的当前网页。
最后,为了防止保存的网页过多,设定最多保存20个网页,当超过20个网页时,把链表顶端的网页删除掉。
下面为示例:
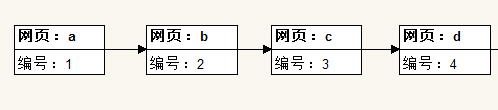
上图为浏览历史记录1,解析为按先后顺序分别浏览了网页a,b,c,d,其中它们的编码为递增。
这时用户按下返回键,

用户按下返回键的时候的当前网页为d,编号4,开始往前搜索,遇到的第一个小于其编号的网页c即为d的前一个网页,这时把c加到尾端成为新的当前网页。
这时用户又按下返回键,

用户按下返回键的时候的当前网页为c,编号3,开始往前搜索,遇到的第一个小于其编号的网页b即为c的前一个网页,这时把b加到尾端成为新的当前网页。
这时用于按下前进键,

用户按下返回键的时候的当前网页为b,编号2,开始往前搜索,遇到的第一个大于其编号的网页c即为b的前一个网页,这时把c加到尾端成为新的当前网页。
//传入的Comparator<HistoryRecord>用于前进或后退的判断依据
private String move(Comparator<HistoryRecord> comparator)
{
int len = this.history.size();
if(len == 0)
return "";
HistoryRecord currentRecord = this.history.get(len - 1);
for(int i = len - 1;i > 0; i --)
{
//当前进时,当前网页编号需要小于对比的网页编号
//当后退时,当前网页编号需要大于对比的网页编号
if(comparator.compare(currentRecord, this.history.get(i - 1)) == 1)
{
HistoryRecord temp = history.get(i - 1);
//将得到的结果加入到链表尾端作为新的当前网页
this.add(temp);
return temp.record;
}
}
//如果没有找到结果,表明该当前网页是第一个访问的网页(后退时)
//或者当前网页是最后一个访问的网页(前进时)
//因此直接返回当前网页。
return currentRecord.record;
}上面算法中的网页保存的是什么:
保存的肯定不会是整个网页内容,这样占用很大内存,因此,里面保存的是网址,这时又有一个疑问,那么搜索结果怎么保存?这时也不是直接保存整个搜索结果,而是保存搜索的目标字符串,这样,下次显示时,只需重新把字符串拿去搜索获取结果便可以了。
SearchResultDisplayFormator显示的内容格式转化:
从上面的Searcher组件可知,搜查结果返回的是Record格式的数据,但是显示的是以网页格式显示,不能仅仅以简单的txt文本格式显示,其中有个很重要的原因是要利用网页的超链接,不然会更麻烦。
对的,因此我们需要将Record格式转变为网页格式,因此我们这里将其转变成html中的列表形式:
<html>
<body>
<ul>
......
<li><a href=...>...</li>
......
</ul>
</body>
</html>这样就简单的完成了显示
public static String format(Collection<Record> records)
{
String result = "<html><body><ul>";
String formator = "<li><a href=\"URL\">NAME</a></li>";
for(Record record:records)
{
String temp = formator.replace("URL", record.url);
temp = temp.replace("NAME", record.fullName);
result += temp;
}
result += "</ul></body></html>";
return result;
}工具组件分析:
StringSpliter字符串分割组件:
听说用java自带的String.split效率不好。。。哈哈,这个就写写吧。。。不用管它就好。。。
FileManager文件操作:
把java原来的文件操作封装下,让它在创建、读写文件/文件夹的时候更方便。
//创建文件夹,当中间缺失一层或多层文件的时候,会补全缺失的文件夹,直至目标文件夹创建,返回创建结果
//例子:目标:c:\\a\\b\\c,但是中间的a、b都不存在,该函数会自动创建文件夹a、b,使可以创建到目标文件夹
public static boolean createDir(String path);
//创建文件,与上面的创建文件夹类似,会自动补全中间缺失的文件夹,返回创建结果
public static boolean createFile(String path);
//读取字符串
public static String readString(String path);
//覆盖数据到目标文件,如果文件不存在,不会创建文件,并且返回false
public static boolean cover(String path, String content);
//添加数据到目标文件,如果文件不存在,不会创建文件,并且返回false
public static boolean append(String path, String content);
//判断文件夹或文件是否存在
public static boolean isExit(String path);
//获取文件或文件夹长度
public static long getLength(String path);数据组件分析:
配置项数据:
解析:
程序中的部分参数可能有改动,例如java版本提高,就需要加入新的java api网址,这时可以通过修改配置文件来加入新网址之类等等。
配置文件存储地址:C:\jdor\configure.txt
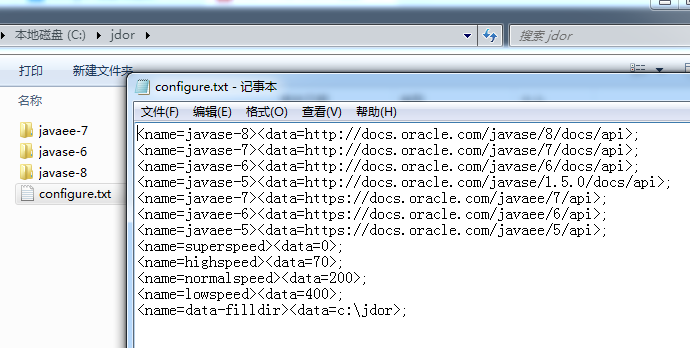
配置项介绍及修改注意:
1.java api网址:
<name=javaVersionName-versionNumber><data=url>;
例子:
<name=javase-8><data=http://docs.oracle.com/javase/8/docs/api>;
javaVersionName:javase
versionNumber:8
url:http://docs.oracle.com/javase/8/docs/api
其中url和名字的关系必须满足:*javaVersionName/versionNumber*
*javase/8*2.下载速度:
<name=*speed><data=分配一个任务以及分配下一个任务之间的间隔时间>;
可根据情况进行调整:
我试验是在超高速情况下(间隔时间为0),会出现大量的下载异常(连接超时),虽说程序会把异常Record重分派,但到最后发现会**少了一个到两个左右的文件**
高速情况下,正常完成任务,所需时间也就是5、6分钟左右。3.数据保存的文件夹:
<name=data-filldir><data=文件夹路径>;配置项相关类:
Configure:
/**
* 配置项类
* name:配置项名
* data:配置项数据
*
* @author zwh
* @version 1.0
*/
public class Configure
{
public String name = "";
public String data = "";
public Configure()
{
}
public Configure(String name, String data)
{
this.name = name;
this.data = data;
}
}
DefaultConfigureKeeper默认配置项数据保存器:
由于程序第一次打开的时候,没有配置文件,而程序很多地方都需要配置的数据,因此该类使用硬编码方式保存了基本的配置项数据。
//该类不能被修改
public final class DefaultConfigureKeeper
{
//由于仅使用该类的静态方法,其所有方法、变量均为静态
private static ArrayList<Configure> configures = new ArrayList<Configure>();
static
{
configures.add(new Configure("javase-8", "http://docs.oracle.com/javase/8/docs/api"));
configures.add(new Configure("javase-7", "http://docs.oracle.com/javase/7/docs/api"));
configures.add(new Configure("javase-6", "http://docs.oracle.com/javase/6/docs/api"));
configures.add(new Configure("javase-5", "http://docs.oracle.com/javase/1.5.0/docs/api"));
configures.add(new Configure("javaee-7", "https://docs.oracle.com/javaee/7/api"));
configures.add(new Configure("javaee-6", "https://docs.oracle.com/javaee/6/api"));
configures.add(new Configure("javaee-5", "https://docs.oracle.com/javaee/5/api"));
configures.add(new Configure("superspeed", "0"));
configures.add(new Configure("highspeed", "70"));
configures.add(new Configure("normalspeed", "200"));
configures.add(new Configure("lowspeed", "400"));
configures.add(new Configure("data-filldir", "c:\\jdor"));
}
//获取所有配置项
public static ArrayList<Configure> getConfigures()
{......;}
//根据名字返回数据项
public static String getData(String name)
{......;}
}ConfigureWriter配置项数据文件写入器:
由于在组件之间交互配置项数据的形式都是以Configure的形式交互,而保存到本地文件是以上面介绍的形式保存,因此该类的作用是将Configure的数据重新组装成所需形式并写入文件。
//必须传入一个或多个Configure给构造函数作为参数
public ConfigureWriter(Collection<Configure> coll)
{
this.configureData = coll;
}
public ConfigureWriter(Configure con)
{
this.configureData.add(con);
}数据组装并写入:
//isCover:以覆盖还是添加的方法
//该函数不是直接供外部使用
private boolean write(String path, boolean isCover)
{
if (!FileManager.isExit(path))
if (!FileManager.createFile(path))
return false;
String data = "";
//数据的重新组装
for (Configure configure : this.configureData)
{
String temp = String.format("<name=%s><data=%s>;\r\n", configure.name, configure.data);
data += temp;
}
//数据的写入
if (isCover && FileManager.cover(path, data))
return true;
if (!isCover && FileManager.append(path, data))
return true;
return false;
}
//为外部调用,提供更方便方法
public boolean cover(String path)
{
return this.write(path, true);
}
public boolean append(String path)
{
return this.write(path, false);
}ConfigureReader配置项数据阅读器:
该类与上面的写入器功能可以说正好相反,负责从配置文件读出配置项数据,但由于读出的数据为字符创格式,为了方便数据传递,需要将其重组装为Configure格式。
而且其它组件、类获取配置项数据均是通过调用该类获取,因此在第一次启动程序的时候(没有配置文件),需要该类初始化配置文件,该类也是仅使用其中的静态方法、变量。
public static ArrayList<Configure> configureData = new ArrayList<Configure>();
......
static
{
ConfigureReader.initialize();
}
......
//初始化该类的数据或者配置项文件
private static void initialize()
{
//由于该方法代码繁杂。。。因此用伪代码代替
if(配置文件不存在)
{
创建配置文件;
if(配置文件创建失败)
{
弹出提示框;
return ;
}
写入配置文件;
//从DefaultConfigureKeeper获取配置项数据
if(配置文件写入失败)
{
弹出提示框;
return ;
}
}
从配置文件读取配置项数据;
if(数据出现异常为空)
{
弹出提示框;
return;
}
重组配置数据;
}目录项数据相关类:
RecordReader:
与ConfigureReader相似,不过也有很多不同,该类需要创建对象使用,而且必须传入字符串作为参数,该类将字符串的数组重组装为Record格式,方便数据传递使用。
而实际上调用该类传入的数据通常为网页数据:
<ul title="Packages">
<li><a href="java/applet/package-frame.html" target="packageFrame">java.applet</a></li>
<li><a href="java/awt/package-frame.html" target="packageFrame">java.awt</a></li>
<li><a href="java/awt/color/package-frame.html" target="packageFrame">java.awt.color</a></li>从上可以看出其url不是完整的URL,因此还需加上URL的前部分,所以还需要传递另外两个参数来完整Record存储的数据:url(前缀),fillDir(数据存储的文件夹)
public RecordReader(String str, String url, String fileDir)
{
this.analize(str, url, fileDir);
}
//数据重组
private void analize(String str, String url, String fileDir)
{
//先把部分截取下来
//<a href="java/awt/color/package-frame.html" target="packageFrame">java.awt.color</a>
Pattern pa = Pattern.compile("(<a.*?</a>)");
//再逐个提取数据
while (ma.find())
{
String temp = ma.group(1);
Record re = new Record();
re.isClass = temp.contains("title");
re.url = this.getStr(Pattern.compile("href=\"(.*?)\""), temp);
re.fullName = this.getStr(Pattern.compile(">(.*?)<"), temp);
re.filePath = re.url.replaceAll("/", "\\\\");
re.url = url + "/" + re.url;
re.filePath = fileDir + "\\" + re.filePath;
this.records.add(re);
}
}数据交互分析:
解析:
这次数据交互,也就是类之间数据的传递,感觉难处在于涉及到多线程,而且我这次组件涉及还是要求每个线程最后把数据传递到同一个组件,然后再在这个组件里面处理信息。
想来想去,感觉就是用static静态方法来实现最好,所以这次我把所有负责处理多线程产生的数据信息的类,都弄成了不需要创建对象使用,而是直接调用它们的静态方法。
负责处理线程产生信息的类组件:
RecordAllocater(ExceptionRecordAllocater)任务分派器:
//保存异常Record
private static ConcurrentLinkedQueue<Record> exceptionRecords = new ConcurrentLinkedQueue<Record>();
......
//RecordOffliner调用该方法,将异常Record添加到exceptionRecords
public static void exceptionRecord(Record record)
{......}FinishedRecordRepertory成品仓库:
//保存完成了下载的Record
public static ConcurrentLinkedQueue<Record> records = new ConcurrentLinkedQueue<Record>();
//管理多线程
private static ExecutorService threadPool = Executors.newCachedThreadPool();
//用于唤醒线程执行任务
private static Lock lockNewRecord = new ReentrantLock();
//添加Reocrd到records
public static void add(Record record)
{......}
//获取已完成保存的Record数量
public static synchronized int getNonFinishedRecordNumber()
{......}RecordOfflinerMonitor下载线程监控器:
private static Lock lockAliveNumber = new ReentrantLock();
private static Lock lockFinishedNumber = new ReentrantLock();
private static Lock lockExceptionNumber = new ReentrantLock();
//存活的下载线程数量
private static int aliveNumber = 0;
//完成离线(下载+保存到本地)的线程数量
private static int finishedNumber = 0;
//下载出现异常的线程数量
private static int exceptionNumber = 0;
public static int getAliveNumber()
{......}
public static int getFinishedNumber()
{......}
public static int getExceptionNumber()
{......}
//创建了新线程
public static void createARecordOffliner()
{......}
//完成了一个新线程的离线(下载+保存到本地)
public static void finishARecordOffliner()
{......}
//一个Record下载过程中出现了异常
public static void ARecordOfflinerException()
{......}OfflineUI下载UI界面:
//防止数据竞争
private static Lock lockNewOfflineExceptionMessage = new ReentrantLock();
//防止数据竞争
private static Lock lockNewOfflineSuccessMessage = new ReentrantLock();
......
//显示组建启动及错误信息记录,因此基本上需要和所有下载组件进行数据交互
private static JTextArea txtOfflineExceptionMessage = new JTextArea();
//显示成功下载记录,因此需要和FinishedRecordRepertory进行数据交互
private static JTextArea txtOfflineSuccessMessage = new JTextArea();
......
//添加组建启动及错误信息
public static void appendOfflineExceptionMessage(String message)
{......}
//添加成功下载的记录信息
public static void appendOfflineSuccessMessage(String message)
{......}程序项目总结:
用到的东西:
多线程:
1.同步synchronized的使用
2.唤醒机制
3.线程之间使用静态方法、变量进行信息交互(虽然不知道好不好)
4.线程内部的异常在自己内部捕抓、解决掉
数据流:
这次那个RecordReader和ConfigureReader,是模仿了java的io包的那种数据流方法(我自己觉得是。。。),就是获取数据流->数据流过滤器(将原始数据流组装、过滤成新的格式)
swing:
1.JMenuBar,JMenu,JMenuItem,ActionListener
2.JComboxBox,ItemListener
3.JEditorPane,HyperlinkListener
4.JProgressBar
总结:
算是一个较为完整的程序,可用性还是有的。。。只是代码感觉还是一团糟,特别非UI组件和UI组件之间的交互,有待改善。。。
程序使用介绍:
第一次打开和没有离线文档的情况下:
离线数据:
开始进行离线数据:
下载界面:
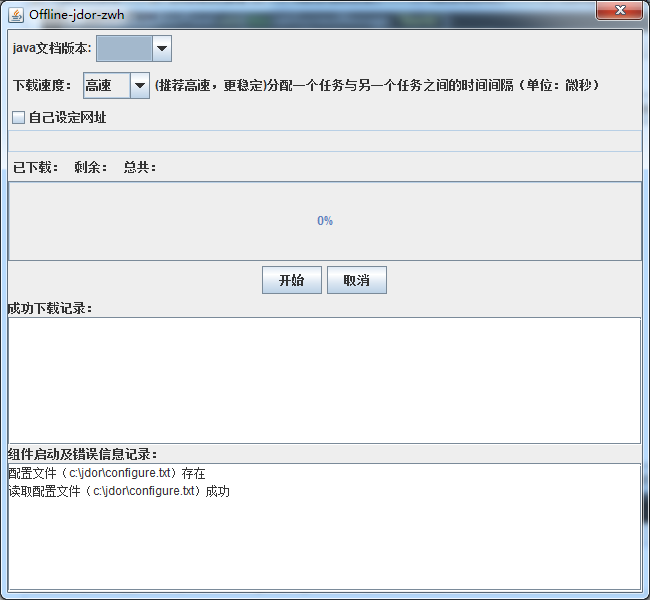
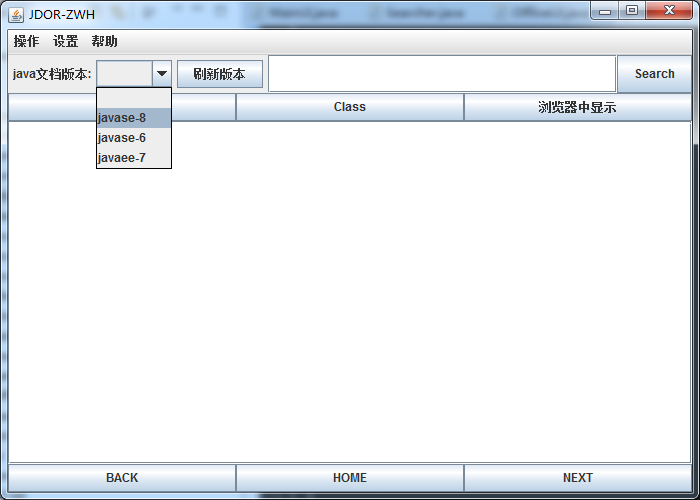
选择版本:
选择下载速度:
开始下载:
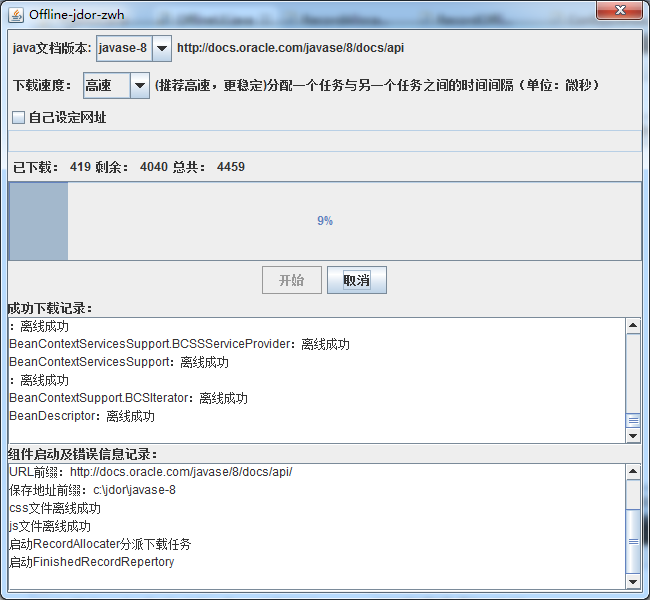
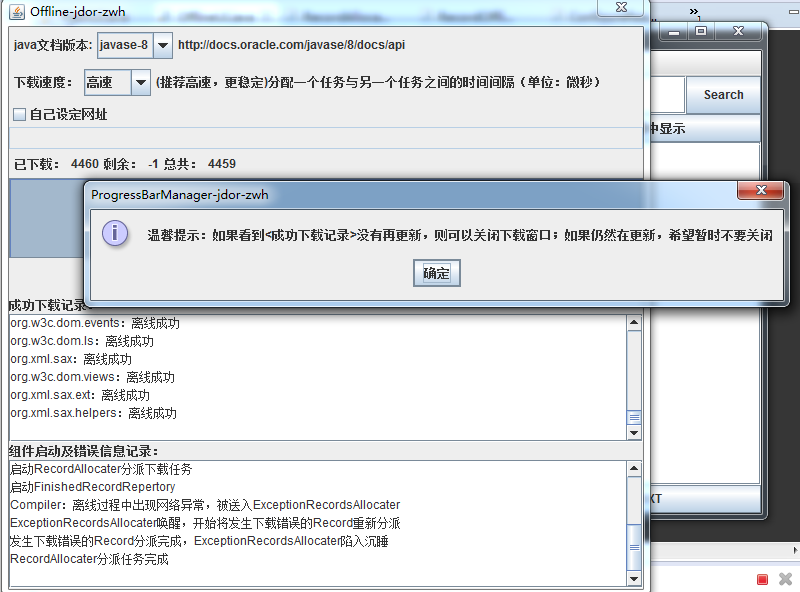
当下载出现异常时:
P.S.图中红框部分就是异常信息以及异常导致组件启动的信息
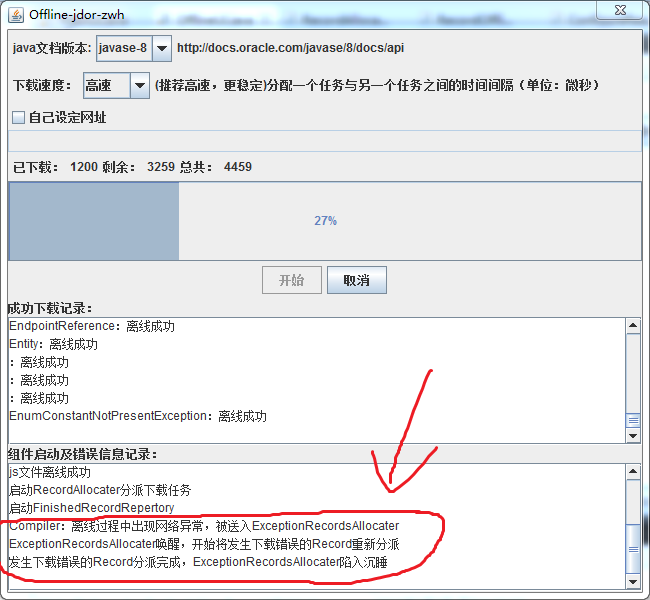
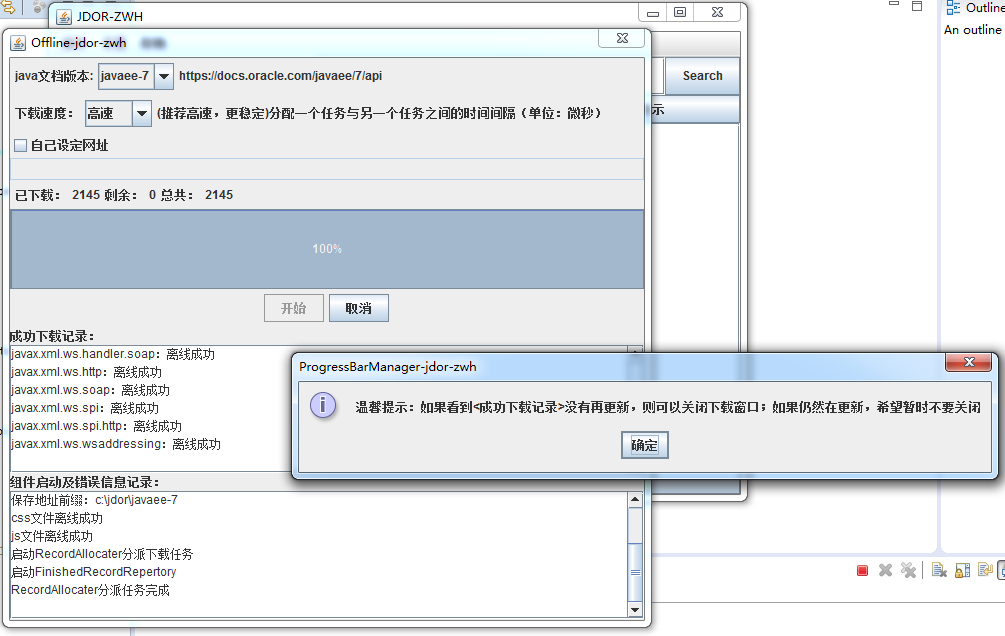
下载完成:
P.S.下载结束的唯一确定标志是<成功下载记录>不再更新