由二叉树结点的性质可以确定的是,二叉树结构相比普通的链表结点而复杂,需要通过其左/右指针访问其左/右子树结点。而在熟悉了二叉树的结构后,需要注意的是二叉树的建立以及遍历操作。而建立与遍历两种操作,需要利用的是递归的思想,即保持每一个子集函数操作与其父函数相同。
首先明确三个概念,前序,中序,后序。这三种概念主要是访问结点及其子树的方式区别,在二叉树的构造以及遍历操作之中均有应用。
前序:又称先序,输出 /输入顺序是先输出根结点的数据,再访问该结点的左子树以及右子树。
中序:输出 /输入顺序是左子树->根结点->右子树
后序:输出 /输入顺序是左子树->右子树->根结点
1. 二叉树的构造操作
二叉树的构造操作应用主要有两种,其一是通过读取数据,以空格表示数据域为空的二叉结点(空树),在确定是哪一种顺序读入的情况下,对于二叉树进行构造。其二是根据任意两种顺序的输出情况确定二叉树的构造,进而可以进行第三种顺序的输出。
先开始二叉树构造的第一种操作,即通过读取字符进行构造。通过读取字符进行构造的基本思路如下:1)新建二叉树结点,命名为结点t 2)进行条件判断,当某个字符是空字符时,使得结点为NULL 3)按照读入的顺序进行判断,这里假设先序读入(即输入字符时结点对应的顺序是根结点->左子树->右子树) 4)若读入是字符不为空字符时,新建结点,将结点的数据域赋值为字符,此时完成的步骤相当于输入根结点的字符 5)按先序的概念,开始输入左子树对应的字符,即将该结点的左结点作为左子树的根结点,继续进行构造二叉树操作,在每一棵左子树内进行的也是先序输入 6)输入右子树对应的字符,将结点的右子树结点作为其右子树的根结点 具体代码如下:
BiTree* Creat(BiTree *t)
{
char a;
cin>>a;
if(a=='#')
{
(*t)=NULL;
}
else
{
if(!((*t)=(BiTree)malloc(sizeof(BiTnode))))
{
exit(-1);
}
(*t)->data=a;
Creat(&((*t)->left));
Creat(&((*t)->right));
}
return t;
}在主程序中的使用方式如下:
int main()
{
BiTree root=NULL;
Creat(&root);
return 0;
}继续二叉树的第二种构造方式:即通过两种顺序的读入来确定二叉树的构成,这里以前序和中序顺序来确定二叉树结构为例,主要使用的思想便是递归,即在函数中反复地调用自身函数达到最终的目的。
首先来看案例:
假设有一棵二叉树t,其前序序列为1,3,4,5,2,6,其中序序列为4,3,5,1,6,2,求二叉树的结构。
首先观察两个序列的结构,如果没有使用程序语言,则完成的基本思路如下 1)由先序序列入手,第一个结点为1,也就是二叉树的根结点,再进入中序序列进行比较,得出此处二叉树的在根结点的左侧结点为4,3,5,右侧结点为6,2。可以较容易地判断出,结点435构成二叉树的左子树,而62构成二叉树的右子树。 2)由递归的思路,先进行左子树的操作,左子树的先序序列为345,中序序列为435,则可以判断出,3是该左子树根结点的左子树,5是该左子树根结点的右子树 3)再度进行右子树的操作,得出2为根结点,6为右子树根结点2的左子树,根结点2的右子树为NULL 3)继续进行最后一步骤,进行条件的判断,若某一棵二叉树的前序序列与其中序序列判断得左右子树均为空时,则一定是仅仅只剩下一个结点的情形,而该结点便作为二叉树的叶子结点。
按照递归的流程会有如下的示意图:
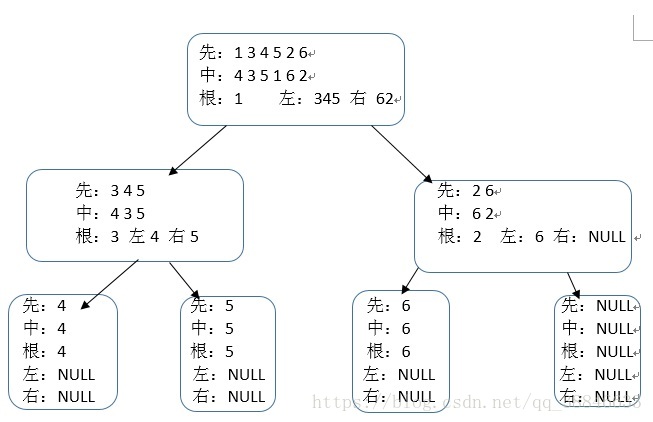
根据示意图得出的递归代码基本思路如下:1)将先序序列与中序序列按照字符串数组的形式存储,记作pre[]与mid[]并且用指针来指出字符串数组的首位 2)建立一个根结点为root,将root的数据域赋值为先序序列的首位(即为一整棵树的根结点) 3)利用for循环,按照示意图的思路,将中序序列中所有在根结点对应字符左侧的字符赋值给根结点左子树的中序序列lmid[],将所有在根结点对应字符右侧的字符赋值给根结点右子树的中序序列rmid[],并同时得出左子树的长度n1,右子树的长度n2 4)先序序列首字符往后的n1位字符赋值给结点root左子树的先序序列lpre[],剩余的位数赋值给root右子树的先序序列rpre[] 5)将root的左子树结点赋值作为新子树的根结点,右子树结点也进行一样的操作。采用递归的思路,而此时左子树的先序序列为lpre[],中序序列为lmid[],序列的长度为n1.右子树的先序序列为rpre[],中序序列为rmid[],序列的长度为n2. 代码如下:
BiTnode* Creat(char *pre,char *mid,int n)
{
BiTnode*root=NULL;
int i;
int n1=0;
int n2=0;
int m1=0;
int m2=0;
char lpre[max],rpre[max];
char lmid[max],rmid[max];
if(n==0)
{
return NULL;
}
root =(BiTnode*)malloc(sizeof(BiTnode));
if(root==NULL)
{
return NULL;
}
memset(root,0,sizeof(BiTnode));
root->data=pre[0];
for(i=0;i<n;i++)
{
if((i<=n1)&& (mid[i]!=pre[0]))
{
lmid[n1++]=mid[i];
}
else if(mid[i]!=pre[0])
{
rmid[n2++]=mid[i];
}
}
for(int i=1;i<n;i++)
{
if(i<n1+1)
{
lpre[m1++]=pre[i];
}
else
{
rpre[m2++]=pre[i];
}
}
root->left=Creat(lpre,lmid,n1);
root->right=Creat(rpre,rmid,n2);
return root;
}在主程序中的使用方式如下:
int main()
{
char pre[max];
char mid[max];
int n=0;
char ch;
BiTnode *root =NULL;
while((ch = getchar())&&ch!='\n')
{
pre[n++]=ch;
}
n=0;
while((ch=getchar())&&ch!='\n')
{
mid[n++]=ch;
}
root=Creat(pre,mid,n);
return 0;
}2.二叉树的遍历操作
(1)先序递归遍历
按照先序的概念,在构造完成二叉树后,先输出其根结点的数据域,再按照左子树,右子树的顺序来进行。按照递归的思路而言,先行设置先序输出的函数名为preorder(),根结点输出后,将二叉树根结点的左孩子结点定义为左子树的根结点,再将左子树内部进行先序遍历。在左子树内部为空后,返回至遍历右子树的函数,即将根结点的右孩子结点定义为右子树的根结点。具体代码如下:
void preorder(BiTnode* root)
{
if(root!=NULL)
{
cout<<root->data;
preorder(root->left);
preorder(root->right);
}
}(2)中序递归遍历
按照中序的概念以及先序遍历的思路,先中序输出根结点的左子树,再输出其根结点的数据,最后才是其右子树,代码如下:
void midorder(BiTnode* root)
{
if(root!=NULL)
{
midorder(root->left);
cout<<root->data;
midorder(root->right);
}
}(3)后序递归遍历
与先序遍历相反,先后序遍历其左子树,再遍历右子树,最后输出其根结点,代码如下:
void lastorder(BiTnode*root)
{
if(root!=NULL)
{
lastorder(root->left);
lastorder(root->right);
cout<<root->data;
}
}(4)后序非递归遍历
不同于二叉树的递归遍历算法,非递归算法要求忠实地记录下每一个经过的结点,之后继续按照一定的输出顺序将它们重新输出。而如何输出则是最大的难点,按照二叉树构造的学习思路,先手动建立一棵二叉树再将其改写成程序语言,二叉树示意图如下:
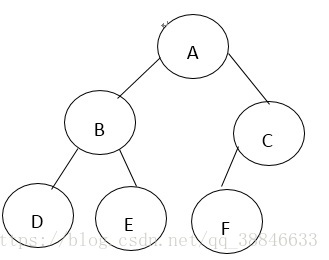
按照树的结构,不难得出其后序遍历输出的顺序为DEBFCA。根据记录结点的要求,先行假设有两个BitNode类型的指针p与q,p用于指示当前的结点,而与之对应的,q指示的是前驱结点。按后序遍历的要求,首先应该输出的是D的值,显而易见地,p指针由根结点出发,只能直接地一路访问左孩子结点到达结点D,而同时地q指针指向的结点为结点B.在此之后,指针p应该返回的是指针q所指的结点,再访问至结点E并将其输出。之后的一步,指针q应退回至结点A,指针p则退回至q原有指示的结点。
由这样一种,前经历后输出的过程,有没有什么相似的数据结构可以用来表达呢?按照目前已有的知识,只能是栈这种结构,将先经历的结点存放入栈内,再将某些满足条件的点一步步输出。将各个点压入栈以及输出栈顺序的示意图如下:

由此可见,压栈的顺序为由根结点开始,由一个指针p指向根结点。先将根结点以及其左孩子结点压入,再压入左孩子结点的左孩子结点,直到结点的左孩子结点为空为止。当结点为空时,输出栈顶结点的数据域,同时将栈顶的结点出栈操作(指针p指示的是栈顶的结点)。结点出栈后,将指针p指向的结点定为栈顶结点下一位结点的右孩子结点(栈顶结点下一位结点是已出栈的结点的根结点,这里用指针q指向的结点来表示)。 具体代码如下:
void Lastorder(BiTnode *root)
{
BiTnode *p=root;
BiTnode *q=NULL;
stack<BiTnode*>s;
while(p!=NULL||!s.empty())
{
while(p!=NULL)
{
s.push(p);
p=p->left;
}
p=s.top();
cout<<p->data;
s.pop();
if(!s.empty())
{
q=s.top();
}
if(p==q->left)
{
p=q->right;
}
else
{
p=NULL;
}
}
}(5)先序非递归遍历
先序非递归遍历的过程相对于后序简单,基本的处理思路便是建立一个返回类型为BiTnode指针的栈命名为s,建立栈后,将根结点root推入栈中。基本思路如下:1)新建一个返回类型为BiTnode类型的指针p,将p初始化指向根结点root 2)由于输出的缘故,先行压入的根结点需要被输出,所以输出语句在前 3)由于栈的结构,决定了先被压入的后输出,根据先序遍历的特性,先输出左孩子结点后输出右孩子结点,所以必须先压入根结点的右子树后压入左子树 4)将问题的规模扩大,压入了root结点为根结点的子树后,需要压入的是根结点的左子树,而将指针p指向左孩子结点的方法便是访问位于栈顶的左孩子结点作为新的根结点 ,对根结点进行同样的操作,即先压入右孩子后压入左孩子 5)在左孩子结点被输出后便可以访问位于左孩子结点下的右孩子。 基本代码如下:
void Preorder(BiTnode*root)
{
BiTnode *p=root;
stack<BiTnode*>s;
s.push(root);
while(!s.empty())
{
p=s.top();//p为空时相当于栈空
s.pop();
if(p!=NULL)
{
cout<<p->data;
s.push(p->right);//先压右孩子结点,再压左孩子结点
s.push(p->left);
}
}
}(6)中序非递归遍历
基本思路与先序非递归遍历相同,即建立一个元素返回类型为BiTnode的栈s,定义一个指针p用于指示当前的结点,初始化为根结点root,基本思路为先将结点以及其左孩子结点一直推入栈中,直到没有左孩子结点为止,再将栈顶的值输出,作为左孩子,定位至新的栈顶,将右孩子结点推入栈中。若此时右孩子为空,则继续输出栈顶结点的值。否则,将右孩子结点作为右子树的根结点继续进行将左孩子结点推入栈中的操作。 右孩子结点倘若不存在左孩子,由于推结点的过程中已经将该结点推入栈中,所以该结点仍然会被输出。 代码如下:
void Midorder(BiTnode*root)
{
BiTnode *p=root;
stack<BiTnode*>s;
while(p!=NULL||!s.empty())
{
while(p!=NULL)
{
s.push(p);
p=p->left;
}
if(!s.empty())
{
p=s.top();
cout<<p->data;
s.pop();
p=p->right;
}
}
}