越努力越幸运!
一.数据库的基础知识
人工管理系统->文件管理系统—>数据库系统阶段
数据库系统组成:数据库,数据库管理系统,数据库管理人员,用户,支持数据库系统的硬件及软件
数据模型:(数据结构+数据操作+完整性约束) 实体完整性约束,参照完整性约束 用户定义的完整性约束。
常见的数据模型:层次模型,网状模型,关系模型
关系数据库的规范化
五个范式等级(一般情况下达到第三范式就可以满足要求了)
第一范式:要求每一列中都是不可分割的数据项(即同一列中不能含有多个值(比如班级:计算机系3班就不行,得变成:系别:计算机系 班级3班),每个字段都是最小的逻辑存储字段。
第一范式(1NF)无重复的列
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。简而言之,第一范式就是无重复的列。
说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。第二范式:要求实体的属性完全依赖于主关键字,即不能存在着只依赖于关键字一部分的属性。
第二范式(2NF)属性完全依赖于主键[消除部分子函数依赖]
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。例如员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是惟一的,因此每个员工可以被惟一区分。这个惟一属性列被称为主关键字或主键、主码。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。简而言之,第二范式就是属性完全依赖于主键。第三范式:要求关系表中不存在着非关键字列对任意候选关键字列的传递函数依赖。如(关键字A决定非关键字段B,而非关键字段B决定非关键字段C)
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在的员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属性。
目的是为了消除数据冗余,更新异常,插入异常和删除异常。
二.sql语句
1、插入语句
insert into [table] ([column],[column],[column])
values(?,?,?)2、删除语句
delete
from [table]
where column = ?3、修改语句
update [table]
set column = ?
where column = ?4、查询语句
1)查询单条记录的所有字段
select *
from [table]
where [column] = ?2)查询所有记录的所有字段
select *
from [table]
order by [column] asc注意:
1.order by column asc代表:以column字段,升序排列。desc为降序
3)查询给定偏移量的记录的所有字段
select *
from [table]
limit [offset], [limit]注意:
1.offset指定从哪个索引开始,默认从0开始
2.limit指定查询几条记录
4)查询指定记录的指定字段
select [column], [column]
form [table]
where [column] = ?sql连接查询(inner join、full join、left join、 right join)
一、内连接(inner join)
首先我这有两张表
1、顾客信息表customer
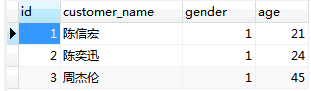
2、消费订单表orders

注意:顾客与订单之间是一对多关系
需求:查询哪个顾客(customer_name)在哪一天(create_time)消费了多少钱(money)
sql语句:
select c.customer_name, o.create_time, o.money
from customer c, orders o
where c.id = o.customer_idsql语句也可以这样写:
select c.customer_name, o.create_time, o.money
from customer c inner join orders o
on c.id = o.customer_id结果:
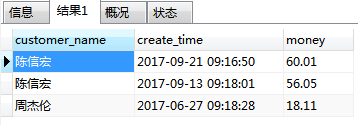
内连接的过程:
将符合条件的记录组合起来,放在一张新表里面
二、左连接(left join)
需求:查询哪个顾客(customer_name)在哪一天(create_time)消费了多少钱(money)
sql语句:
select c.customer_name, o.create_time, o.money
from customer c
left join orders o
on c.id = o.customer_id结果:

从结果可以很清楚的明白左连接的含义:
将左边表的所有记录拿出来,不管右边表有没有对应的记录
三、右连接(right join)
需求:查询哪个顾客(customer_name)在哪一天(create_time)消费了多少钱(money)
sql语句:
select c.customer_name, o.create_time, o.money
from customer c
right join orders o
on c.id = o.customer_id结果:
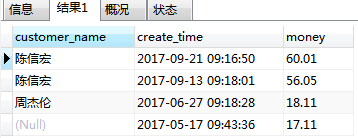 、
、
从结果可以很清楚的明白右连接的含义:
将右边表的所有记录拿出来,不管右边表有没有对应的记录
四、全连接(full join)
这里要注意的是mysql本身并不支持全连接查询,但是我们可以使用UNION关键字实现
sql语句:
select c.customer_name, o.create_time, o.money
from customer c
left join orders o
on c.id = o.customer_id
UNION
select c.customer_name, o.create_time, o.money
from customer c
right join orders o
on c.id = o.customer_id结果:
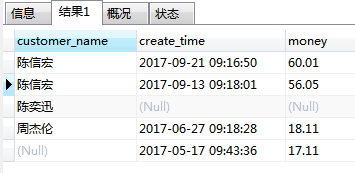
从sql语句中可以清楚的看到:
使用UNION关键字将左连接和右连接,联合起来
常见的sql语句面试题
常见的数据库面试题
1.面试官:drop,delete与truncate的区别
drop直接删掉表 truncate删除表中数据,再插入时自增长id又从1开始 delete删除表中数据,可以加where字句。
(1) DELETE语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存以便进行进行回滚操作。TRUNCATE TABLE 则一次性地从表中删除所有的数据并不把单独的删除操作记录记入日志保存,删除行是不能恢复的。并且在删除的过程中不会激活与表有关的删除触发器。执行速度快。
(2) 表和索引所占空间。当表被TRUNCATE 后,这个表和索引所占用的空间会恢复到初始大小,而DELETE操作不会减少表或索引所占用的空间。drop语句将表所占用的空间全释放掉。
(3) 一般而言,drop > truncate > delete
(4) 应用范围。TRUNCATE 只能对TABLE;DELETE可以是table和view
(5) TRUNCATE 和DELETE只删除数据,而DROP则删除整个表(结构和数据)。
(6) truncate与不带where的delete :只删除数据,而不删除表的结构(定义)drop语句将删除表的结构被依赖的约束(constrain),触发器(trigger)索引(index);依赖于该表的存储过程/函数将被保留,但其状态会变为:invalid。
(7) delete语句为DML(data maintain Language),这个操作会被放到 rollback segment中,事务提交后才生效。如果有相应的 tigger,执行的时候将被触发。
(8) truncate、drop是DLL(data define language),操作立即生效,原数据不放到 rollback segment中,不能回滚
(9) 在没有备份情况下,谨慎使用 drop 与 truncate。要删除部分数据行采用delete且注意结合where来约束影响范围。回滚段要足够大。要删除表用drop;若想保留表而将表中数据删除,如果于事务无关,用truncate即可实现。如果和事务有关,或老师想触发trigger,还是用delete。
(10) Truncate table 表名 速度快,而且效率高,因为:
truncate table 在功能上与不带 WHERE 子句的 DELETE 语句相同:二者均删除表中的全部行。但 TRUNCATE TABLE 比 DELETE 速度快,且使用的系统和事务日志资源少。DELETE 语句每次删除一行,并在事务日志中为所删除的每行记录一项。TRUNCATE TABLE 通过释放存储表数据所用的数据页来删除数据,并且只在事务日志中记录页的释放。(11) TRUNCATE TABLE 删除表中的所有行,但表结构及其列、约束、索引等保持不变。新行标识所用的计数值重置为该列的种子。如果想保留标识计数值,请改用 DELETE。如果要删除表定义及其数据,请使用 DROP TABLE 语句。
(12) 对于由 FOREIGN KEY 约束引用的表,不能使用 TRUNCATE TABLE,而应使用不带 WHERE 子句的 DELETE 语句。由于 TRUNCATE TABLE 不记录在日志中,所以它不能激活触发器。
2.面试官:主键 超键 候选键 外键
主 键:
数据库表中对储存数据对象予以唯一和完整标识的数据列或属性的组合。一个数据列只能有一个主键,且主键的取值不能缺失,即不能为空值(Null)。
超 键:
在关系中能唯一标识元组的属性集称为关系模式的超键。一个属性可以为作为一个超键,多个属性组合在一起也可以作为一个超键。超键包含候选键和主键。
候选键:
是最小超键,即没有冗余元素的超键。
外 键:
在一个表中存在的另一个表的主键称此表的外键。
3.面试官:视图的作用,视图可以更改么?
视图是虚拟的表,与包含数据的表不一样,视图只包含使用时动态检索数据的查询;不包含任何列或数据。使用视图可以简化复杂的sql操作,隐藏具体的细节,保护数据;视图创建后,可以使用与表相同的方式利用它们。
视图不能被索引,也不能有关联的触发器或默认值,如果视图本身内有order by 则对视图再次order by将被覆盖。
创建视图:create view XXX as XXXXXXXXXXXXXX;
对于某些视图比如未使用联结子查询分组聚集函数Distinct Union等,是可以对其更新的,对视图的更新将对基表进行更新;但是视图主要用于简化检索,保护数据,并不用于更新,而且大部分视图都不可以更新。
4.面试官:数据库范式
1 第一范式(1NF)
在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。
所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。简而言之,第一范式就是无重复的列。2 第二范式(2NF)
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主关键字或主键、主码。
第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。简而言之,第二范式就是非主属性非部分依赖于主关键字。3 第三范式(3NF)
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属性。(我的理解是消除冗余)
5.面试官:了解数据库连接吗?
一、外连接
1.概念:包括左向外联接、右向外联接或完整外部联接
2.左连接:left join 或 left outer join
(1)左向外联接的结果集包括 LEFT OUTER 子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值(null)。
(2)sql 语句
select * from table1 left join table2 on table1.id=table2.id
-------------结果-------------
idnameidscore
------------------------------
1lee190
2zhang2100
4wangNULLNULL
------------------------------
注释:包含table1的所有子句,根据指定条件返回table2相应的字段,不符合的以null显示
3.右连接:right join 或 right outer join
(1)右向外联接是左向外联接的反向联接。将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。
(2)sql 语句
select * from table1 right join table2 on table1.id=table2.id
-------------结果-------------
idnameidscore
------------------------------
1lee190
2zhang2100
NULLNULL370
------------------------------
注释:包含table2的所有子句,根据指定条件返回table1相应的字段,不符合的以null显示
4.完整外部联接:full join 或 full outer join
(1)完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。
(2)sql 语句
select * from table1 full join table2 on table1.id=table2.id
-------------结果-------------
idnameidscore
------------------------------
1lee190
2zhang2100
4wangNULLNULL
NULLNULL370
------------------------------
注释:返回左右连接的和(见上左、右连接)
二、内连接
1.概念:内联接是用比较运算符比较要联接列的值的联接
2.内连接:join 或 inner join
3.sql 语句
select * from table1 join table2 on table1.id=table2.id
-------------结果-------------
idnameidscore
------------------------------
1lee190
2zhang2100
------------------------------
注释:只返回符合条件的table1和table2的列
4.等价(与下列执行效果相同)
A:select a.*,b.* from table1 a,table2 b where a.id=b.id
B:select * from table1 cross join table2 where table1.id=table2.id (注:cross join后加条件只能用where,不能用on)
三、交叉连接(完全)
1.概念:没有 WHERE 子句的交叉联接将产生联接所涉及的表的笛卡尔积。第一个表的行数乘以第二个表的行数等于笛卡尔积结果集的大小。(table1和table2交叉连接产生3*3=9条记录)
2.交叉连接:cross join (不带条件where...)
3.sql语句
select * from table1 cross join table2
-------------结果-------------
idnameidscore
------------------------------
1lee190
2zhang190
4wang190
1lee2100
2zhang2100
4wang2100
1lee370
2zhang370
4wang370
------------------------------
注释:返回3*3=9条记录,即笛卡尔积
4.等价(与下列执行效果相同)
A:select * from table1,table2
6.面试官:什么是存储过程?有哪些优缺点?
存储过程Procedure是一组为了完成特定功能的SQL语句集合,经编译后存储在数据库中,用户通过指定存储过程的名称并给出参数来执行。
存储过程中可以包含逻辑控制语句和数据操纵语句,它可以接受参数、输出参数、返回单个或多个结果集以及返回值。
由于存储过程在创建时即在数据库服务器上进行了编译并存储在数据库中,所以存储过程运行要比单个的SQL语句块要快。同时由于在调用时只需用提供存储过程名和必要的参数信息,所以在一定程度上也可以减少网络流量、简单网络负担。