http://blog.csdn.net/pipisorry/article/details/51822775
numpy排序、搜索和计数函数和方法。(重新整合过的)
排序Sorting
| sort(a[, axis, kind, order]) | Return a sorted copy of an array. |
| lexsort(keys[, axis]) | Perform an indirect sort using a sequence of keys. |
| argsort(a[, axis, kind, order]) | Returns the indices that would sort an array. |
| ndarray.sort([axis, kind, order]) | Sort an array, in-place. |
| msort(a) | Return a copy of an array sorted along the first axis. |
| sort_complex(a) | Sort a complex array using the real part first, then the imaginary part. |
| partition(a, kth[, axis, kind, order]) | Return a partitioned copy of an array. |
| argpartition(a, kth[, axis, kind, order]) | Perform an indirect partition along the given axis using the algorithm specified by the kind keyword. |
numpy多维数组排序
python列表排序
list.sort()一般用法:list.sort(axis = None, key=lambdax:x[1],reverse = True)
或者使用内置函数sorted():
sorted(data.tolist(), key=lambda x: x[split])
用ndarray.sort内建函数排序
数组的sort()方法用于对数组进行排序,它将改变数组的内容。
ndarray.sort()没有key参数,那怎么编写比较函数comparator?
示例
list1 = [[1, 3, 2], [3, 5, 4]] array = numpy.array(list1) array.sort(axis=1) print(array) [[1 2 3] [3 4 5]]
sort内建函数是就地排序,会改变原有数组,不同于python中自带的sorted函数和numpy.sort通用函数,参数也不一样。
sort内建函数返回值为None,所以不能有这样的语法:array.sort(axis=1)[:5],这相当于是对None类型进行切片操作
矩阵按其第一列元素大小顺序来对整个矩阵进行行排序
mat1=mat1[mat1[:,0].argsort()]
用numpy.sort通用函数排序
np.sort()函数则返回一个新数组,不改变原始数组(类似于python中自带的sorted函数,但numpy中没有sorted函数,参数也不一样)。
它们的axis参数默认值都为-1,即沿着数组的最后一个轴进行排序。 np.sort()函数的axis参数可以设置为None,此时它将得到平坦化之后进行排序的新数组。
>>> np.sort(a) #对每行的数据进行排序array([[1, 3, 6, 7, 9],
[1, 2, 3,5, 8],
[0, 4, 8, 9, 9],
[0, 1, 5, 7, 9]])
>>> np.sort(a, axis=0) #对每列的数据进行排序 array([[5,1,1, 4, 0],
[7, 1, 3, 6, 0],
[9, 5, 9, 7, 2],
[9, 8, 9'8, 3]])
升序排序的实现:
list1 = [[1,3,2], [3,5,4]] array = numpy.array(list1)
array = sort(array, axis=1) #对第1维升序排序
#array = sort(array, axis=0) #对第0维 print(array) [[1 2 3][3 4 5]]
降序排序的实现:
#array = -sort(-array, axis=1) #降序
[[3 2 1] [5 4 3]]
lexsort: 使用一列键来执行间接排序
这样就可以对两个列表一同进行排序。
示例:Sort two columns of numbers:
>>> a = [1,5,1,4,3,4,4] # First column
>>> b = [9,4,0,4,0,2,1] # Second column
>>> ind = np.lexsort((b,a)) # 先对a排序,再对b排序
>>> print(ind)
[2 0 4 6 5 3 1]
>>> [(a[i],b[i]) for i in ind]
[(1, 0), (1, 9), (3, 0), (4, 1), (4, 2), (4, 4), (5, 4)]
用numpy.argsort通用函数排序
argsort函数用法(numpy-ref-1.8.1P1240)
argsort()返冋数组的排序下标,axis参数的默认值为-1。
argsort(a, axis=-1, kind='quicksort', order=None)
Returns the indices that would sort an array.
argsort函数返回的是数组值从小到大的索引值
Examples --------
One dimensional array:一维数组
>>> x = np.array([3, 1, 2])
>>> np.argsort(x)
array([1, 2, 0])
Two-dimensional array:二维数组
>>> x = np.array([[0, 3], [2, 2]])
>>> x
array([[0, 3],
[2, 2]])
>>> np.argsort(x, axis=0) #按列排序
array([[0, 1],
[1, 0]])
>>> np.argsort(x, axis=1) #按行排序
array([[0, 1],
[0, 1]])
>>> x = np.array([3, 1, 2])
>>> np.argsort(x) #按升序排列
array([1, 2, 0])
>>> np.argsort(-x) #按降序排列
array([0, 2, 1])
Note: 当然也可以升序排序,在处理的时候处理成降序也行,如np.argsort(index[c])[:-MAX_K:-1]
另一种方式实现按降序排序(不能用于多维数组)
>>> a
array([1, 2, 3])
>>> a[::-1]
array([3, 2, 1])
>>> x[np.argsort(x)] #通过索引值排序后的数组
array([1, 2, 3])
>>> x[np.argsort(-x)] #不能用于二维存取!!
array([3, 2, 1])
多维数组的降序排序
list1 = [[1, 3, 2], [3, 1, 4]] a = numpy.array(list1) a = numpy.array([a[line_id,i] for line_id, i in enumerate(argsort(-a, axis=1))]) print(a) [[3 2 1] [4 3 1]]
list1 = [[1, 3, 2], [3, 1, 4]] a = numpy.array(list1) sindx = argsort(-a, axis=1) indx = numpy.meshgrid(*[numpy.arange(x) for x in a.shape], sparse=True, indexing='ij') indx[1] = sindx a = a[indx] print(a) [[3 2 1] [4 3 1]]
list1 = [[1, 3, 2], [3, 1, 4]] a = numpy.array(list1) a = -sort(-a, axis=1) print(a) [[3 2 1] [4 3 1]]
搜索Searching
一般numpy数组搜索到某些值后都要进行另外一些操作(如赋值、替换)。
比如替换numpy数组中值为0的元素为1, a[a == 0] = 1
更复杂的筛选可以通过np.minimum(arr, 255)或者result = np.clip(arr, 0, 255)实现。
| argmax(a[, axis, out]) | Returns the indices of the maximum values along an axis. |
| nanargmax(a[, axis]) | Return the indices of the maximum values in the specified axis ignoring NaNs. |
| argmin(a[, axis, out]) | Returns the indices of the minimum values along an axis. |
| nanargmin(a[, axis]) | Return the indices of the minimum values in the specified axis ignoring NaNs. |
| argwhere(a) | Find the indices of array elements that are non-zero, grouped by element. |
| nonzero(a) | Return the indices of the elements that are non-zero. |
| flatnonzero(a) | Return indices that are non-zero in the flattened version of a. |
| where(condition, [x, y]) | Return elements, either from x or y, depending on condition. |
| searchsorted(a, v[, side, sorter]) | Find indices where elements should be inserted to maintain order. |
| extract(condition, arr) | Return the elements of an array that satisfy some condition. |
最值
用min()和max()可以计算数组的最大值和最小值,而ptp()计算最大值和最小值之间的差。
它们都有axis和out两个参数。
用argmax()和argmin()可以求最大值和最小值的下标。如果不指定axis参数,就返回平坦化之后的数组下标。
>>> np.argmax(a) #找到数组a中最大值的下标,有多个最值时得到第一个最值的下标
2
>>> a.ravel()[2] #求平坦化之后的数组中的第二个元素
9
可以通过unravel_index()将一维下标转换为多维数组中的下标,它的第一个参数为一维下标值,第二个参数是多维数组的形状。
>>> idx = np.unravel_index(2, a.shape)
>>> idx
(0, 2)
>>> a[idx]
9
当使用axis参数时,可以沿着指定的轴计算最大值的下标。
例如下面的结果表示,在数组 a中,第0行中最大值的下标为2,第1行中最大值的下标为3:
>>> idx = np.argmax(a, axis=1)
>>> idx
array([2, 3, 0, 0])
使用idx选择出每行的最大值:
>>> a[xrange(a.shape[0]),idx]
array([9, 8, 9, 9])
nonzero(a)
返回非0元素的下标位置
其实不就是a != 0吗?
元素查找where
查找某个元素的位置
given a Numpy array, array, and a value, item, to search for.
itemindex = numpy.where(array==item)
The result is a tuple with first all the row indices, then all the column indices.
只查找一维array的第一个位置
array.tolist().index(1)
itemindex = np.argwhere(array==item)[0]; array[tuple(itemindex)]
Note:np.argwhere(a) is the same as np.transpose(np.nonzero(a)).The output of argwhere is not suitable for indexing arrays.For this purpose use where(a) instead.index = numpy.nonzero(first_array == item)[0][0]
[Is there a Numpy function to return the first index of something in an array?]
分段函数
{像python中的x = y if condition else z 或者 C语言里面的 condition?a:b,判断条件是否正确,正确则执行a,否则b}
where函数
where(condition, [x, y])
例1:计算两个矩阵的差,然后将残差进行平方
def f_norm_1(data, estimate):
residule = 0
for row_index in range(data.shape[0]):
for column_index in range(data.shape[1]):
if data[row_index][column_index] != 0:
residule += (data[row_index][column_index] - estimate[row_index][column_index]) ** 2
return residule
def f_norm_2(data, estimate)
return sum(where(data != 0, (data-estimate) **2, 0))
因为我需要的是考虑矩阵稀疏性,所以不能用内置的norm,函数1是用普通的python写的,不太复杂,对于规模10*10的矩阵,计算200次耗时0.15s,函数2使用了where函数和sum函数,这两个函数都是为向量计算优化过的,不仅简洁,而且耗时仅0.03s, 快了有五倍,不仅如此,有人将NumPy和matlab做过比较,NumPy稍快一些,这已经是很让人兴奋的结果。
例2:
>>> x=np.arange(10)
>>> np.where(x<5,9-x,x)
array([9, 8, 7, 6, 5, 5, 6, 7, 8, 9]) 表示的是产生一个数组0~9,然后得到另一个数组,这个数组满足:当x<5的时候它的值变为9-x,否则保持为x)。
select函数
out = select(condlist, choicelist, default=0)
其中,condlist是一个长度为N的布尔数组列表,choicelist是一个长度为N的储存候选值 的数组列表,所有数组的长度都为M.如果列表元素不是数组而是单个数值,那么它相当于元素值都相同且长度为M的数组。对于从0到M-1的数组下标i,从布尔数组列表中找出满足条件“condlist[j][i]=True”的 j的最小值,则“out[i]=choicelist[j][i]”,其中out是select()的返回数组。choicelist的最后一个元素为True,表示前面所有条件都不满足时,将使用choicelist的最后一个数组中的值。也可以用default参数指定条件都不满足时的候选值数组。
>>> np.select([x<2,x>6,True],[7-x,x,2*x])
array([ 7, 6, 4, 6, 8, 10, 12, 7, 8, 9]) 表示的是当x满足第一个条件时,执行7-x,当x满足第二个条件事执行x,当二者都不满足的时候执行2*x。
piecewise()
piecewise(x, condlist, funclist)
前面两个函数都比较耗内存,所以引入piecewise(),因为它只有在满足条件的时候才计算。也就是where()和select()的所有参数都需要在调用它们之前完成计算,因此下面的实例中NumPy会计算下面4个数组:x>=c, x<c0, x/c0*hc, (c-x)/(c-c0)*hc。在计算时还会产生许多保存中间结果的数组,因此如果输入的数组x很大,将会发生大量的内存分配和释放。为了解决这个问题,可以使用piecewise()专门用于计算分段函数。
参数x是一个保存自变量值的数组.condlist是一个长度为M的布尔数组列表,其中的每个布尔数组的长度都和数组x相同。funclist是一个长度为M或M+1的函数列表,这些函数的 输入和输出都是数组。它们计算分段函数中的每个片段。如果不是函数而是数值,就相当于返回此数值的函数。每个函数与condlist中下标相同的布尔数组对应,如果funclist的长度为M+l, 那么最后一个函数对应于所有条件都为False时。
np.piecewise(x, [x < 0, x >= 0], [-1, 1])
x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.piecewise(x, [x<2,x>6], [lambda x:7-x,lambda x:x,lambda x:2*x])
array([7, 6, 0, 2, 4, 6, 8, 0, 1, 2])
Note: piecewise中funclist如果不是数值而是函数时要使用lambda表达式,不能使用简单表达式7-x,否则会出错,如ValueError: NumPy boolean array indexing assignment cannot assign 10 input values to the 2 output values where the mask is true。
实例
用一个分段函数描述三角波,三角波的样子如下
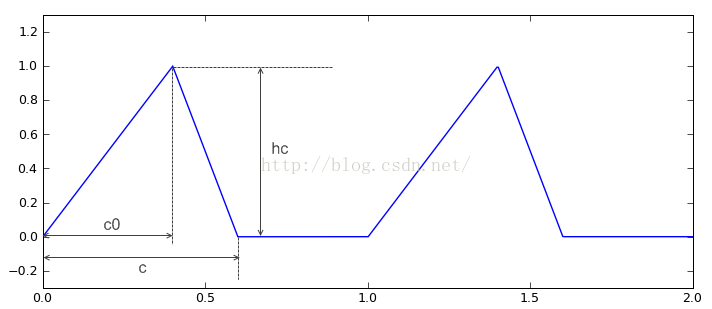
def triangle_wave(x, c, c0, hc):
x = x - x.astype(np.int) #三角波的周期为1,因此只取x坐标的小数部分进行计算
return np.where(x>=c,0,np.where(x<c0, x/c0*hc, (c-x)/(c-c0)*hc))
由于三角波形分为三段,因此需要两个嵌套的where()进行计算.由于所有的运算和循环 都在C语言级别完成,因此它的计算效率比frompyfunc()高。
随着分段函数的分段数量的增加,需要嵌套更多层where(),但这样做不便于程序的编写 和阅读。可以用select()解决这个问题。
def triangle._wave2(x, c, c0, hc):
x = x - x.astype(np.int)
return np.select([x>=c, x<c0, True], [0, x/c0*hc, (c-x)/(c-c0)*hc])
也可以使用default:return np.select([x>=c, x<c0], [0, x/c0*hc], default=(c-x)/(c-c0)*hc)
使用piecewise()计算三角波形
def triangle_wave3(x, c, c0, hc):
x = x - x.astype(np.int)
return np.piecewise(x,
[x>=c, x<c0],
[0, # x>=c
lambda x: x/c0*hc, # x<c0
lambda x: (c-x)/(c-c0)*hc]) # else
使用piecewise()的好处在于它只计算需要计算的值.因此在上面的例子中,表达式 “x/c0*hc”和“(c-x)/(c-c0)*hc”只对输入数组x中满足条件的部分进行计算。
调用
x = np.linspace(0, 2, 1000)
y4= triangle_wave3(x,0.6, 0.4, 1.0)
计数Counting
| count_nonzero(a) | Counts the number of non-zero values in the array a. |
统计numpy数组中非0元素的个数。
0-1array统计1个数
统计0-1array有多少个1, 两种方式
np.count_nonzero(fs_predict_array) fs_predict_array.sum()count_nonzero速度更快,大概1.6倍快。
统计多维数组所有元素出现次数
使用pandas顶级函数pd.value_counts,value_counts是一个顶级pandas方法,可用于任何数组或序列:
>>> pd.value_counts(obj.values, sort=False)
from: http://blog.csdn.net/pipisorry/article/details/51822775
ref: [Sorting, searching, and counting]