版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/ssmixi/article/details/78026040
深度学习简史
一.发展历程
- 1958年,提出感知机模型(只能解决线性可分问题,无法解决异或问题);
- 20世纪80年代末,研究分布式知识表达和神经网络反向传播算法提出(分布式知识表达加强了模型的表达能力,让神经网络从宽度的方向走向了深度的方向);反向传播算法大大的降低了网络的训练时间;
- 如今的深度卷积神经网络,循环卷积网络等;
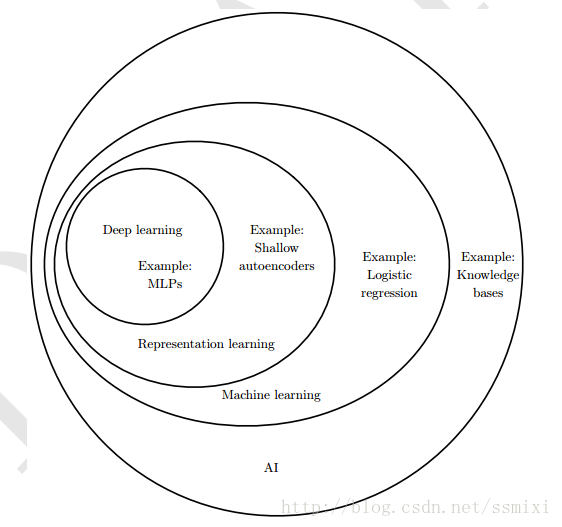
—— 深度学习是AI的途径之一。具体说,它是机器学习的一种,一种允许计算机系统从经验和数据中得到提高的技术。
——研究重点:新的无监督学习技术和从小数据集进行泛化的能力,但目前更多的注意点是在更古老的监督学习算法和深度模型充分利用大型标注数据集的能力(截至 2016 年,一个粗略的经验法则是,监督深度学习算法一般在每类给定约 5000标注样本情况下可以实现可接受的性能,当至少有 1000 万标注样本的数据集用于训练时将达到或超过人类表现。在更小的数据集上成功是一个重要的研究领域,为此我们应特别侧重于如何通过无监督或半监督学习充分利用大量的未标注样本)。
(配图来自《深度学习》)
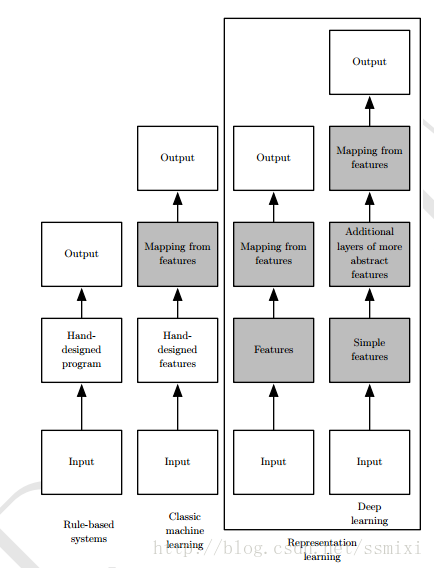
二.基本概念
- 处理结构化数据:将结构化的数据序列化,并从序列化后的数据流中还原出原来的结构化数据;
- 分布式表示:
这一想法是系统每个的输入应该由许多特征表示的,并且每个特征应参与许多可能输入的表示。例如,假设我们有一个能够识别红色、绿色、或蓝色的汽车、卡车和鸟
类的视觉系统。 表示这些输入的其中一个方法是将九个可能的组合:红卡车,红汽车,红鸟,绿卡车等等使用单独的神经元或隐藏单元激活。这需要九个不同的神经元,并且每个神经必须独立地学习颜色和对象身份的概念。改善这种情况的方法之一是使用分布式表示,即用三个神经元描述颜色,三个神经元描述对象身份。这仅仅需要 6 个神经元而不是 9 个,并且描述红色的神经元能够从汽车、卡车和鸟类的图像中学习红色,而不仅仅是从一个特定类别的图像中学习。
【参考】
参考: