写在前面
中途丢失过一次近2000的文字,写得心痛。
kafka权威指南很久前已经看完了。今天打算根据所学到的知识进行一些基准测试和调优。本篇文章侧重实践+少量源码分析+部分原理分析,更多的原理分析、理解放在下篇文章中
【实战过程中,脑海中冒出了太多的疑惑和想解决的问题,我认为消息中间件 比之前学习的大数据生态的一些组件要复杂些,等校招拿了offer,我会把下方所有未解决的问题,逐个深入击破】。
另外,由于无人指导,文章中的测试或者结论,皆为个人见解,不妥之处,大家多指出。
背景
需要将第三方接口的数据全部导出,为避免数据丢失,故考虑使用kafka,暂时没有结合Flume(数据维度有些复杂)。
数据量:近8000万条论文等知识产权数据,预计600G。
我所理解的kafka的使用场景
考虑数据丢失。比如我们从某个数据源接受数据,但是数据从数据源流出的速度大于我们接受数据组件的处理速度,那么这种情况,就很有可能出现数据丢失;还有就是网络阻塞,机器宕机,也可能会造成数据丢失。而kafka处理数据的策略可以很好的解决这个问题
多订阅数据分发,kafka的消费者组,kafka的某个主题,可以让多个组件去订阅。比如我们某个系统出来的数据,可能多个子系统都会使用这些数据,那么使用kafka是个很不错的选择【比如对于同一份数据,我们需要有不同的动作,比如对该数据进行数据清洗挖掘信息,或者将该数据发往别的界面进行展示,等等。】(Kafka支持多个消费者从一个消息流上读取数据,而且消费者之间直不影响)
实时处理:收集处理流式数据(我们可以把数据库的更新发布到 Kafka 上,应用程序通过监控事件流来接收数据库的实时更新。)
日志收集: kafka可将多个日志服务器的数据聚合到一起,比如说文件服务器,hdfs。之后再对这些日志数据进行离线分析,或者放入全文检索系统中进行数据挖掘
应用程序指标,跟踪 CPU 使用率和应用性能等指标
行为跟踪:跟踪用户浏览页面、搜索及其他行为,以发布-订阅的模式实时记录到对应的topic里。那么这些结果被订阅者拿到后,就可以做进一步的实时处理,或实时监控,或放到hadoop/离线数据仓库里处理。(在领英,Kafka 最初的使用场景是跟踪用户的活动。这样一来就可以生成报告,为机器学习系统提供数据,更新搜索结果等)
优化需要考虑的问题
使用kafka前,有些我们需要考虑的地方,想象我们自己设计中间件,需要考虑些什么?
- 生产与消费,异步还是同步?
- 如何确定生产者正确接受到数据,当前场景,是否每个消息都很重要?是否允许丢失一小部分消
息?偶尔出现重复消息是否可以接受? - 发送失败的重试次数
- 是否有严格的延迟和吞吐量要求?
- 缓冲区大小
- 因为是消息中间件嘛,所以消息不会持久化,只是作为一个通道,所以需要根据实际业务,考虑消息删除策略,是基于时间还是基于空间
- 由于组的概念,以为消费者往往需要进行数据分析、处理,所以我们还需要考虑消费者处理数据的速度,需要多少消费者,还有确定消费者分别处理哪些分区的数据。
- 还有消费者数量变化、分区数量变化导致的数据再均衡
- 消费者读取信息的偏移量,如何保证消费者成功消费到所有数据
- 如何保证消费者不重复消费数据
- 如何正确退出生产和消费
- 等等
注
以下代码会有不少注释,很多注释是初学时或者第一次实践时注释的,考虑到好记性不如烂笔头,就没有去掉。但是在企业真实生产环境中,过于普通,大家都懂的注释,还是少写点吧?
生产者优化
对于server的配置优化,留到最后,不然反复重启Kafka集群,还是比较不划算。
配置1-同步生产数据
在这里, producer.send()先返回一个 Future 对象,然后调用 Future 对象的 get()方法等待 Kafka 响应。如果服务器返回错误, get 方法会抛出异常。如果没有发生错误,我们会得到一个 RecordMetadata 对象,进一步,可以用它获取消息的偏移量。
kafkaProducer.send(new ProducerRecord<>(topic, Integer.toString(keyCount), Arrays.toString(keywords))).get();props.put("bootstrap.servers", "172.21.201.144:9092,172.21.201.143:9092,172.21.201.142:9092,172.21.201.141:9092");
// acks:生产者需要server端在接收到消息后,进行反馈确认的尺度,主要用于消息的可靠性传输;
// acks=0表示生产者不需要来自server的确认;
// acks=1表示server端将消息保存后即可发送ack,而不必等到其他follower角色的都收到了该消息;
// acks=all(or acks=-1)意味着server端将等待所有的副本都被接收后才发送确认。
props.put("acks", "1");
// retries:生产者发送失败后,重试的次数
props.put("retries", 1);
// 当多条消息发送到同一个partition时,该值控制生产者批量发送消息的大小
props.put("batch.size", 100);
// linger.ms:默认情况下缓冲区的消息会被立即发送到服务端,即使缓冲区的空间并没有被用完。
// 可以将该值设置为大于0的值,这样发送者将等待一段时间后,再向服务端发送请求,以实现每次请求可以尽可能多的发送批量消息
props.put("linger.ms", 1);
// 生产者缓冲区的大小(320MB),保存的是还未来得及发送到server端的消息,如果生产者的发送速度大于消息被提交到server端的速度,该缓冲区会被耗尽。
props.put("buffer.memory", 335544320);测试数据21338万条,耗时616.37s【如此慢,与我请求的接口有挺大联系】
由于需要多次修改配置,还是将配置写入properties文件更加“专业”些,另外,获取consumer和producer,封装到KafkaUtils中。暂未考虑写consumer和producer抽象类
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.common.PartitionInfo;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.io.InputStream;
import java.util.Collections;
import java.util.List;
import java.util.Properties;
import java.util.Set;
/**
* <p>package: ipl.restapi.util</p>
* <p>
* descirption:
*
* @author 王海
* @version V1.0
* @since <pre>2018/9/4 13:24</pre>
*/
public class kafkaUtils {
private static final Logger LOGGER = LoggerFactory.getLogger("kafka");
public static KafkaProducer<String, String> getProducer() {
// 加载配置文件(Properties extends Hashtable<Object,Object>)
Properties props = new Properties();
InputStream input;
try {
input = kafkaUtils.class.getResourceAsStream("/kafka_producer.properties");
props.load(input);
} catch (IOException e) {
LOGGER.error(e.getMessage());
System.exit(-1);
}
return new KafkaProducer<>(props);
}
public static KafkaConsumer<String, String> getConsumer() {
Properties props = new Properties();
InputStream input;
try {
input = kafkaUtils.class.getResourceAsStream("/kafka_consumer.properties");
props.load(input);
} catch (IOException e) {
LOGGER.error(e.getMessage());
System.exit(-1);
}
return new KafkaConsumer<>(props);
}
}配置2-异步生产数据
我们调用 send () 方怯,并指定一个回调函数, 服务器在返回响应时调用该函数。
- 假设消息到broker的一个来回需要50ms,那么发送10000条数据就需要500秒,如果采用异步方式来生产消息,则大概会节约一般的时间。
- 考虑到这可能会导致数据丢失,我们可以onCompletion回调函数,这样,遇到消息发送失败的情况,我们可以记录信息到文件以备后续处理。
查看源码可知,get() 方法 throws InterruptedException, ExecutionException可能抛出这两个异常。
static class KeyWordProducerCallBack implements Callback {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
LOGGER.error("offset: {}", String.valueOf(recordMetadata.offset()));
LOGGER.error(e.getMessage());
}
}
}
kafkaProducer.send(new ProducerRecord<>(topic, Integer.toString(keyCount), Arrays.toString(keywords)), new KeyWordProducerCallBack());测试数据21338万条,耗时265.863s【有一倍多的提升】
配置3-发送并忘记
我们把消息发送给服务器,但井不关心它是否正常到达。因为失败后生产者会自动尝试重发,所以大多数情况下,消息会正常到达,不过,使用这种方式有时候仍可能丢失一些消息。这里测试意义不大。
配置4-butch.size与接口速度测试
- butch.size=200,接口每次读取200:大概160s【说大概,是因为CSDN服务器老是吞我文字,成天服务器错误。。。转个头,又没了】
- butch.size=700,接口每次读取350:【汲取教训,还是截图妥当,测了下,350就是接口吞吐量上线了,再多,就不返回数据了。】
- 考虑到缓存中的数据提交到broker的速度较快,预测提高butch.size后不会再有提升,因为吞吐量肯定是受慢的一方的限制
butch.size=1000,接口每次读取350:【搞不懂了,为什么还有提升?貌似这次,从打印来看,我感觉网速也变快了?】
- 设置为2000再看看:【这下对了,没变化了】


kafka删除数据的几种方式:
超时(默认七天,server.properties),考虑到当前场景,我改为了24小时
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
除此以外, log. retention.minutes和log. retention.ms也是同样的作用。除,如果指定了不止一个参数, Kafka 会优先使用具有最小值的那个参数。(这个时间是最后那条消息写入segment的时间戳)超空间
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
log.retention.bytes=1073741824
要注意,这个参数是针对分区的,也就是说,如果有一个包含 5 个分区的主题,井且 log.retention.bytes 被设为 1GB ,那么这个主题最多可以保留 5GB 的数据。所以,当主题的分区个数增加时,整个主题可以保留的数据也随之增加。- 手动删除
kafka-topics --zookeeper ip10:2181 --topic papper_topic --delete
还需要注意一个配置:
Topic papper_topic is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
如果你也要做很多的性能测试,建议设置delete.topic.enable为true,方便测试删除topic,否则只是标记为删除,并没有真正删除,标记为删除之后会有什么操作,暂时没学习 - 删除之后查看topic list
只要上方任意一个条件得到满足,消息就会被删除
kafka-topics --zookeeper localhost:2181 --list
关于分区
要注意,由于一个主题一般包含几个分区,因此无法在整个主题范围内保证消息的顺序,但可以保证消息在单个分区内的顺序。
在没有设置任何分区参数时:

按道理在我们没有手动设置分区的时候,分区由kafka计算,但是我这里测试的20万条数据的partition数都是0 ,应该不是巧合。所以我深入学习了下kafka的分区机制,详见这这篇文章{TODO}
如下文,这里的分区都是0,也是由于key都是1,故全都散列映射到了一个partition。
key有什么用?
我注意到截图中的key都是1,(当然,是我代码写错了),于是考虑,既然消费者通过offset来获取数据,那么这个key,有什么用呢?
疑惑解决:
键是用于分区的,比如说对这个键值进行一致性哈希【解决分布式场景下,保证分区变化后,依然能够正确的访问到值,换句话说,解决数据均衡的问题】,哈希值再对分区数取模求得分区数。为什么不直接对value进行hash呢?我觉得(个人见解),一方面考虑到key可以自定义增序(需要转为字符串),减少hash冲突;另一方面,比如安照JDK中的实现,value的length可能比key更长,那么计算key的hash值的代价就更小。
关于是否重复生产
这个,没找到相关资料,实验也没有验证出多次运行是否会重复生产,不知道偏移量对于生产者有用不。
如何查看某个分区目前的数据量(不使用命令行)
提出该问题的原因:
1. 多次测试,数据是否重复生产到broker?也就是说,是数据覆盖,还是追加?
2. 每次测试,我想清空topic的所有数据
花费2h+时间,资料+官网+源码,无果。
获得所有主题的名称
consumer.listTopics().keySet()
获得某个主题的详细分区信息
很明显
consumer.listTopics().get(topic-name)
然后,查看源码克可知:调用toString()方法即可。
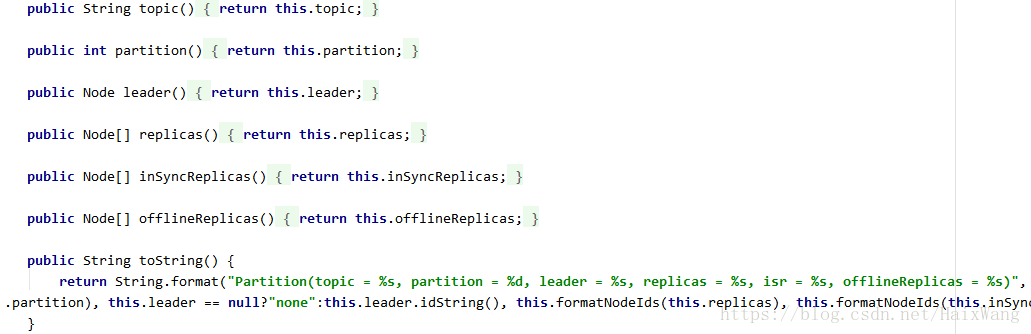
对下方打印结果的进一步理解,161是什么鬼?返回结果类似于命令
kafka-topics --zookeeper ip10:2181 --topic papper_topic --describe
[Partition(topic = papper_topic, partition = 0, leader = 161, replicas = [161], isr = [161], offlineReplicas = [])]
推测161是broker的id,遂去查看配置文件。话说,一直想吐槽CDH的文件目录组织形式,太麻烦了,与原生保持一致不好吗?
路径:/opt/cloudera/parcels/KAFKA-3.1.0-1.3.1.0.p0.35/etc/kafka/conf.dist

每台机器都只有server.properties,没有别人所说的produceer.properties
broker.id默认值是 0。这个值在整个 Kafka 集群里必须是唯一的(好奇为什么之前broker值重复了,依然成功启动了所有broker)。
不建议分区数量设置过大。因为越多的分区数量,完成首领选举需要的时间也越长。
清空主题数据
删除好说,清空没找到相应方法和也没有思路,TOTO
硬件级别优化
更好的磁盘,做磁盘阵列,文件系统的选择,网络——更大的带宽
虚拟机优化
Kafka 对堆内存的使用率非常高,容易产生垃圾对象(井没有启用 G l 回收器,默认时使用了 Parallel New 和 CMS回收器)
我们可以改为更为高效率的G1回收器:
-server-XX: +UseG1GC,所以可以把这些值设得小一些。如
根据实际情况,可设置垃圾回收器相关参数使得更早一些进行垃圾回收。
消费者
深入理解偏移量
消费者通过检查消息的偏移量来区分已经读取过的消息。 偏移量是不断递增的整数值,在创建消息
时, Kafka 会把它添加到消息里。
消费者把每个分区最后读取的悄息偏移量保存在 kafka上(新版本不再保存在 Zookeeper上)。
偏移量关系到消费者是否重复消费或者漏掉消费,比较重要的概念,待深入学习后补充。
从头消费
auto.offset.reset=earliest
zookeeper启动报错
zookeeper Error: JMX connector server communication error: service:jmx:rmi:
端口占用:netstat -apn | grep 2181
nodemanager报错
IO error: lock /var/lib/hadoop-yarn/yarn-nm-recovery/yarn-nm-state/LOCK: Resource temporarily unavailable