什么是Hadoop?
Hadoop是一个由Apache基金会开发的可靠的,可扩展的分布式计算的开源软件。其基于聚合的思想,将资源整合在一起用于海量数据额存储与处理。
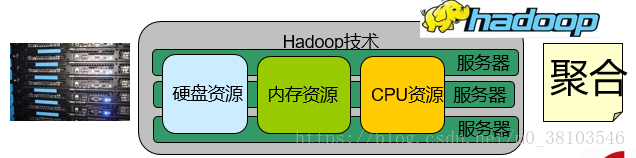
hadoop的核心
- HDFS:Hadoop Distributed File System分布式文件系统,解决海量数据的存储问题;
- MapReduce:分布式计算框架,解决海量数据的分析问题;
- YARN:Yet Another Resource Negotiator 资源管理调度系统,用于资源管理调度,对计算进行管理,不仅仅可以执行MapReduce,还可以执行其他的计算,如Spark on YARN,storm
Hadoop处理海量数据的存储问题方法
如果专有的服务器上的数据过多而不能继续存储,则使用另外的服务器。此时,出现了两个需要解决的问题:一是数据的可靠性,二是查询文件的问题。Hadoop对这两个问题的解决提供的方法,其中,对问题一,使用备份的方法;对问题二,使用统一的文件系统(后面映射到一个集群中),用户不需要关心文件到底是存储到集群中的那一个结点,只要使用hadoop提供的统一文件路径就能找到文件。
hadoop很厉害,基于hadoop有很多的生态软件:
HDFS架构
- 主从结构:主节点,NameNode;从节点,有很多个,DataNode;
- NameNode负责:接受用户操作请求;维护文件系统的目录结构;管理文件与block之间的关系,block与datanode之间的关系;
- DataNode负责:存储文件;文件被分为block存储在磁盘上;为保证数据的安全,文件会有多个副本;
Hadoop的部署方式以及配置:
配置hadoop组件,含四个配置文件在hadoop安装目录下的etc/hadoop子目录中:core-site.xml文件用于配置通用属性(common),hdfs-site.xml文件用于HDFS的属性配置,mapred-site.xml文件用于配置MapReduce属性,yarn-site.xml用于YARN属性
- 本地模式:使用本地的jdk进行执行,不需要任何守护进程(daemon),所有程序都在单个JVM上执行,由于在本机模式下测试和调试MapReduce程序较为方便,因此适用于开发阶段。
- 伪分布式模式(单结点的分布式模式):使用本地的jdk进行执行,Hadoop对应的java进程都运行在一个物理机器上,守护进程运行在本地机器上,模拟一个小规模的集群,换句话说,可以配置一台机器的hadoop集群,仅仅是机器的数量少但是通信机制与运行过程与真正的集群模式是一样的是完全分布式的一个特例。
- 集群模式(完全分布式模式)(HA和非HA):有多台服务器,hadoop守护进程运行在一个集群上。
>HA模式,多个NameNode(如,两个,一个处于active,一个处于standby),多个DataNode
>非HA模式,一个NameNode(主节点),多个DataNode(从节点),如果主节点不能使用,那么整个集群都不能使用,单点失效
所谓分布式要启动守护进程,即使用分布式hadoop时,要启动一些准备进程,如start-dfs.sh,start-yarn.sh,然后才能使用。而本地模式不需要启动这些守护进程。在本地模式下,将使用本地文件系统和本地的MapReduce运行器;在分布式模式下,将启动HDFS和YARN守护进程。
三种必须配置文件之间的区别:
| 组件名称 | 配置文件 | 属性名称 | 本地模式 | 伪分布式 | 完全分布式 |
| Common | core-site.xml | fs.defaultFs | file:///(默认) | hdfs://localhost/ | hdfs://namenode |
| HDFS | hdfs-site.xml | dfs.replication | N/A | 1 | 3(默认) |
| MapReduce | mapred-site.xml | mapreduce.framework.name | local(默认) | yarn | yarn |
| Yarn | yarn-site.xml | yarn.resourcemanager.hostname yarn.nodemanager.auxservice |
N/A N/A |
localhost mapreduce_shuffle |
resourcemanager mapreduce_shuffle |
例如伪分布式配置环境下:
配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
</configuration>
配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/softData/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/softData/hadoop/dfs/data</value>
</property>
</configuration>配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>