practice11: excel读写(xlsx文件)
1、 excel读
excel内容

import xlrd
#不可以使用~来代替/home/openlab
book = xlrd.open_workbook('/home/openlab/Desktop/test.xls')
#一个book含有两张sheet,可以看到返回了两个sheet object
print(book.sheets())
#取到book里的第一张sheet
sheet0 = book.sheet_by_index(0)
#查看sheet的行
print(sheet0.nrows)
#查看sheet的列
print(sheet0.ncols)
#访问cell,即一个小格
#返回类型+value
print(sheet0.cell(0,0))
#返回类型 1代表文本 2代表数字
print(sheet0.cell(0,0).ctype)
print(sheet0.cell(1,1).ctype)
#返回value
print(sheet0.cell(0,0).value)
#访sheet的行,行号从0开始
print(sheet0.row(1))
#访sheet的行,并对选中的行按列切片 row_values(行号,起始列号,终止列号=None) 注意:左闭右开
print(sheet0.row_values(1,1,None))
print(sheet0.col(0))
print(sheet0.col_values(0,1,None))
#增加或修改一个cell
print(sheet0.cell(1,1))
sheet0.put_cell(1,1,2,100,None)
print(sheet0.cell(1,1))结果:

2、 Excel 写
import xlwt
#构造book
wbook = xlwt.Workbook()
sheet1 = wbook.add_sheet('sheet1')
#write(行,列,值)
sheet1.write(0,0,'kesjsjjs')
#保存
wbook.save('/home/openlab/Desktop/111.xls')
3、 小结
- xlrd仅能把xls文件读取为book对象,进行操作;xlwt仅能创建book对象,写入值后,将其写入为一个xls文件;二者都围绕book对象进行操作
- xlwt构造的sheet不包含put_cell方法!!只有读出来的sheet才有
- 一般处理过程:用xlrd读excel,用put-cell修改sheet,再把修改过的sheet赋值给xlwt的sheet,最后保存
4、 实例:求和
import xlrd,xlwt
#读取excel文件
rbook = xlrd.open_workbook('grades.xls')
#读取sheet表
rsheet = rbook.sheet_by_index(0)
cols = rsheet.ncols
#修改sheet表
rsheet.put_cell(0,cols,1,'总分',None)
for row in range(1,rsheet.nrows):
grade = sum(rsheet.row_values(row,1))
rsheet.put_cell(row,cols,2,grade,None)
wbook = xlwt.Workbook()
#创建一张临时表,暂时为空
wsheet = wbook.add_sheet('sheet1')
#将修改过得rsheet赋值给临时表
for r in range(rsheet.nrows):
for c in range(rsheet.ncols):
wsheet.write(r,c,rsheet.cell(r,c).value)
wbook.save('grades1.xls')
5、 实例,比较两张表的差异!
import xlrd
class Compare_sheets():
def __init__(self,sheet1,sheet2):
self.sheet1 = sheet1
self.sheet2 = sheet2
def __sheet_to_set(self,sheet):
tmpset = set()
for row in range(1,sheet.nrows):
info_tuple = tuple(sheet.row_values(row))
tmpset.add(info_tuple)
return tmpset
def __compare_sets(self,set1,set2):
print("sheet1中不同与sheet2的元素有:",set1-set2)
print("sheet2中不同与sheet1的元素有:",set2-set1)
def go(self):
set1 = self.__sheet_to_set(self.sheet1)
set2 = self.__sheet_to_set(self.sheet2)
self.__compare_sets(set1,set2)
rbook = xlrd.open_workbook('id.xls')
sheet1 = rbook.sheet_by_index(0)
sheet2 = rbook.sheet_by_index(1)
compare = Compare_sheets(sheet1,sheet2)
compare.go()
#practice12:csv文件处理
csv文件格式
- 基本单位为一行,行与行之间以\n分割
- 每一行由多个基本元素组成,元素与元素之间以逗号分割
csv文件的读写:调用模块csv(reader和writer)
import csv
#python3中urlretrieve位置改变了
from urllib.request import urlretrieve
import chardet
#使用csv模块读取csv文件
#第一步打开文件
def convert(file_name,new_file_name):
with open(file_name,'rt',encoding='GB2312') as f:
reader = csv.reader(f)
header = next(reader)
print(header)
with open(new_file_name,'wt',encoding='utf-8') as wf:
writer = csv.writer(wf)
writer.writerow(header)
for row in reader:
if row[0] > '2016-01-01' and int(row[11]) > 500000:
writer.writerow(row)
print("*************end")
#从网上下载csv文件
url = 'http://quotes.money.163.com/service/chddata.html?code=1000001&start=20150104&end=20160108'
urlretrieve(url,'pingan.csv')
convert('pingan.csv','pingan_result.csv')
#practice13:文本文件读写
1、 文本文件与二进制文件区别
- 定义
计算机的存储在物理上是二进制的,所以文本文件与二进制文件的区别并不是物理上的,而是逻辑上的。这两者只是在编码层次上有差异。
简单来说,文本文件是基于字符编码的文件,常见的编码有ASCII编码,UNICODE编码等等。二进制文件是基于值编码的文件,如音频文件,冠字号文件,你可以根据具体应用,指定某个值(可以看作是自定义编码)。
从上面可以看出文本文件基本上是定长编码的(也有非定长的编码如UTF-8),基于字符,每个字符在具体编码中是固定的,ASCII码是8个比特的编码,UNICODE一般占16个比特。而二进制文件可看成是变长编码的,因为是值编码,多少个比特代表一个值,完全由自己决定。
+ 存取
文本工具打开一个文件,首先读取文件物理上所对应的二进制比特流,然后按照所选择的解码方式来解释这个流,然后将解释结果显示出来。一般来说,你选取的解码方式会是ASCII码形式(ASCII码的一个字符是8个比特),接下来,它8个比特8个比特地来解释这个文件流。记事本无论打开什么文件都按既定的字符编码工作(如ASCII码),所以当他打开二进制文件时,出现乱码也是很必然的一件事情了,解码和译码不对应。
文本文件的存储与其读取基本上是个逆过程。而二进制文件的存取与文本文件的存取差不多,只是编/解码方式不同而已。
+ 优缺点
因为文本文件与二进制文件的区别仅仅是编码上不同,所以他们的优缺点就是编码的优缺点。一般认为,文本文件编码基于字符定长,译码容易;二进制文件编码是变长的,所以它灵活,存储利用率要高些,译码难一些(不同的二进制文件格式,有不同的译码方式)。
在windows下,文本文件不一定是ASCII来存贮的,因为ASCII码只能表示128的标识,打开一个txt文档,然后另存为,有个选项是编码,可以选择存贮格式,一般来说UTF-8编码格式兼容性要好一些。而二进制用的计算机原始语言,不存贮兼容性
+ 注意
如果一个文件内存储了一堆随机二进制数字,可以视作二进制文件,但由于未对其编解码进行定义,该二进制文件是没有意义的
2、文本文件操作
2.1 读文本文件
#以文本方式打开文件,t默认;但如果要指明编解码方式,必须用关键字来指明参数,而不是位置参数
#rf为可迭代对象。每次迭代返回一行,返回值为字符串
with open('pingan.csv','rt',encoding='GB2312') as rf:
text = rf.read()
#文本模式下,读到的内容为str
print(type(text))
#看下只读+文本模式下,文件对象有哪些方法
print(dir(rf))
#查看文件对象有无写权限
print(rf.writable())
#返回当前文件指针的位置,单位byte;35689正好代表文件的大小
print(rf.tell())
#调整指针位置函数seek(offset,from_what=0)
#定位到文件开始
rf.seek(0)
#查看当前指针位置
print(rf.tell())
#指针定位到文件尾
rf.seek(0,2)
#在文本文件中做如下随意定位指针的做法非常危险!不推荐
rf.seek(10)
print(rf.tell())
#按行读取(\n),返回结果为字符串
rf.seek(0)
print(rf.readline())
#读取文件为列表,列表每个元素为文本中的一行,列表每个元素为字符串
mylist = rf.readlines()
print(mylist)
文本模式下,read/readline/readlines都没有参数
2.2 写文本文件
with open('write.txt','wt',encoding='utf8')as wf:
#write参数是str,返回值为写入的byte数
print(wf.write('wakaka服装店'))
#查看方法
print(dir(wf))
#tell、seek可以使用,不推荐
print(wf.tell())
wf.seek(0)
print(wf.tell())
3、 编解码格式解读
3.1 概念
- 一般有:ascll GB2312 gbk utf-8(unicode的一种)
- GB2312 gbk用于汉字,兼容ascll
- utf-8是一种通用编码,适用于多种语言,同样兼容ascll码
- python中有str和byte两种字符串,用print输出byte字符串时,操作系统或者IDE会自动将byte中的字母、数字、控制符通过ascll解码出来(因为所有编码方式对于字母、数字、控制符的编码都是相同的,即兼容ascll码)
- str本质是文本;bytes本质是o和1组成的串
3.2 实践str、byte与编解码
#str转bytes:仅含有ascll码的字符
a = r'123abc\n'
print(a)
print(type(a))
b = b'123abc\n'
print(b)
print(type(b))
#str转bytes:含有非ascll码,此时要借助类bytes
#bytes中表示数字、字母、控制符(ascll字符)的比特会被IDE自动解码
a = '123abc呵呵'
print(bytes(a,encoding='utf-8'))
print(bytes(a,encoding='gbk'))
#gbk向下兼容GB2312
print(bytes(a,encoding='GB2312'))
#str转bytes:含有非ascll码,此时要借助str的encode方法
print(a.encode(encoding='utf-8'))
print(a.encode(encoding='GBK'))
#bytes转str
b = b'123abc\xe5\x91\xb5\xe5\x91\xb5'
print(b.decode('utf-8'))
#对于ascll码字符集组成的字符串,直接字符表示即可,不必要写其十六进制值
b = b'\x33\x30'
print(b.decode('utf-8'))
b = b'30'
print(b.decode('utf-8'))
4、 集中文件打开模式总结:a w+ a+ r+
#文本附加模式:在源文件末添加文本
#说明write.txt初始文本为:xxxxxxxxxx
with open('write.txt','at',encoding='utf-8') as f:
print(f.readable())
print(f.writable())
f.write('cacacac')
with open('write.txt','r',encoding='utf-8') as rf:
print(rf.read())
#文本读写w+t:该模式下写会将源文件内容擦掉并写入新内容
with open('write.txt','w+t',encoding='utf-8') as f:
#指针位于文件首
print(f.tell())
#原始内容被擦掉,所以内容为空
print(f.read())
f.write('xxxxxxxxxx')
f.seek(0)
print(f.read())
#文本读写a+t:该模式下初始指针位于文件尾,读写均要注意指针位置
with open('write.txt','a+t',encoding='utf-8') as f:
f.write('aaa')
#指针位于文件尾,读取为空
print(f.read())
f.seek(0)
print(f.read())
#文本读写r+t:初始指针位于文件头,源文件内容未擦除,进行覆盖写;读的话严格按照指针位置进行读
with open('write.txt','r+t',encoding='utf-8') as f:
f.write('AAAAAAAA')
print(f.tell())
print(f.read())
#practice14:二进制文件读写
1、 对于byte字符串的认识以及误区

注意:byte字符串每次iteration,返回值为一个二进制数,IDE会自动将数字进行ascll解码
2、 二进制结构化数据的读取与写入:方法一
import struct
#二进制结构化数据的写入与读取
#写入方法一:
bytes1 = struct.pack('<5shhc','ab我'.encode('utf-8'),10,15,b'q')
#注意:5s表示5byte的字符串;h:short;i:int;c:char;这些都是c语言的概念,字符串与字符char必须是bytes类型
#对应打包关系:‘ab我’:ab\xe6\x88\x91,字符'我'z占后三个byte
#10:\n\x00,因为short占两个byte,且存储方式默认为little ending(小头),所以真实比特流为\x00\n -> \x00\x0A -> ob0000000000001010 -> 10
print(bytes1)
#读取方法一:
text = struct.unpack('<5shhc',bytes1)
print(text)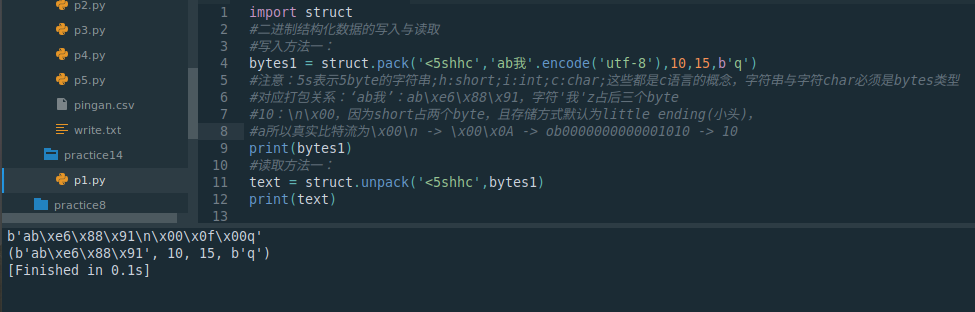
struct模块作用:This module performs conversions between Python values and C structs represented as Python bytes objects.
3、 二进制结构化数据的读取与写入:方法二
from struct import Struct
mystruct = Struct('<5shhc')
bytes1 = mystruct.pack('ab我'.encode('utf-8'),10,15,b'q')
print(bytes1)
tuple1 = mystruct.unpack(bytes1)
print(tuple1)
struct.pack操作不同于encode操作:前者针对python内的所有value,包括字符串(pack处理时以字符为基本单位)、int、float等;encode仅仅针对文本,即字符串;相同点:最终转换值为bytes对象
4、 注意点
- linux与windowas系统下都默认byte order为little ending,即字节存储顺序为倒序:如占4个byte的int类型\x00\x00\x00\xff,在计算机中存储时,4个byte顺序正好倒过来:\xff\x00\x00\x00
- 字符串处理时,以每个字符为基本单位,一个字符占一个字节,不存在字节顺序的问题!(中文字符待考证)
- <表示little ending,如果不标,默认为@,会造成数据大小随平台而变的情况,容易出大坑!
- 最好写fmt(格式字符串)时,开头标注’<’

5、 二进制wav文件读写实例
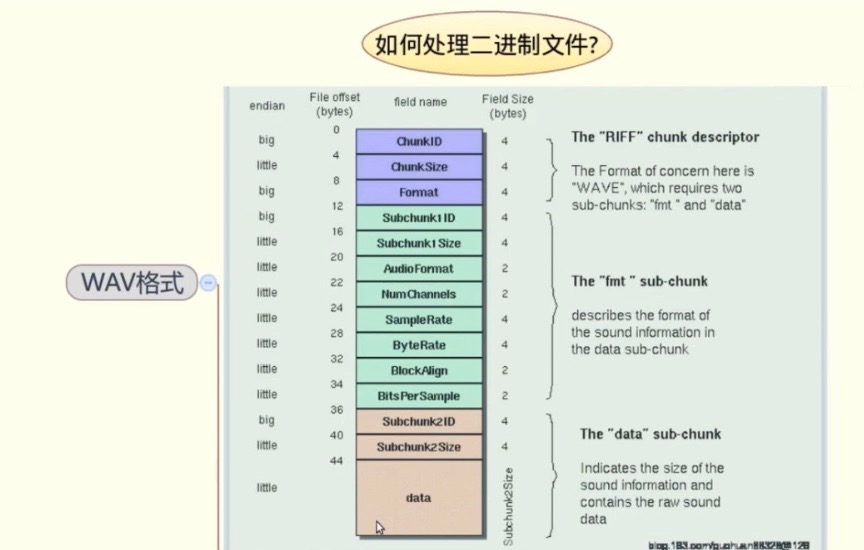
5.1 文件格式
import struct
from collections import namedtuple
import array
class Wav():
def __init__(self,filename,filename_tosave):
#虽然在类的其他方法里创建self.avariable也会生成实例属性,但最好把多个方法公用的实例属性放在__init__里定义
self.filename = filename
self.filename_tosave = filename_tosave
#由于python弱类型,这里用数字0初始化也没问题,但最好还是用空bytes比较规整
self.head_bytes = b''
self.myarray = array.array('h')
self.myarray_length = 0
def __parse(self):
'''二进制数据读取为结构化bytes'''
with open(self.filename,'rb') as rf:
self.head_bytes = rf.read(44)
rf.seek(0,2)
self.myarray_length = int((rf.tell()-44)/2)
self.myarray = array.array('h',(0 for _ in range(self.myarray_length)))
rf.seek(44,0)
rf.readinto(self.myarray)
def __print_header(self):
'''把header由bytes转化为Python数据类型并输出'''
Header = namedtuple('Header','NumChanels SampleRate BitsPerSample')
numchanels = struct.unpack('<h',self.head_bytes[22:24])
samplerate = struct.unpack('<i',self.head_bytes[24:28])
bitespersample = struct.unpack('<h',self.head_bytes[34:36])
header = Header(numchanels,samplerate,bitespersample)
#打印具名元组
print(header)
def __modify_wav(self):
'''将wav文件音量调低'''
for i in range(self.myarray_length):
self.myarray[i] = int(self.myarray[i]/10)
def __save(self):
'''将修改的文件保存'''
with open(self.filename_tosave,'wb') as wf:
wf.write(self.head_bytes)
self.myarray.tofile(wf)
def go(self):
#启动程序
self.__parse()
self.__print_header()
self.__modify_wav()
self.__save()
wav = Wav('1969.wav','demo1.wav')
wav.go()
#practice15:json模块学习
1、 json.dumps与json.loads(针对json字符串与python对象的转换,s表示string)
import json
json_string = '[1,2,"abc",{"hello":3,"world":2}]'
python_obj = json.loads(json_string)
print(python_obj)
print(type(python_obj))
python_obj = {'hello':[1,2,3],'works':18}
json_string = json.dumps(python_obj)
print(json_string)
print(type(json_string))
2、 json.dump与json.load(针对json文件与python对象的转换)
import json
python_obj = {'hello':[1,2,3],'works':18}
#将python数据结构转化为json文件
with open('demo.json','w') as wf:
json.dump(python_obj,wf)
#从json文件中读取json字符串
with open('demo.json','r') as rf:
#对于文本模式读取,返回值定为字符串,这里返回json字符串
text = rf.read()
print(type(text))
print(text)
#json字符串反序列化为python数据结构
python1 = json.loads(text)
print(type(python1))
print(python1)
with open('demo.json','r') as rf:
#省略中间过程,json文件直接转换为python数据结构
python2 = json.load(rf)
print(type(python2))
print(python2)

从上图可以看出json文件与json字符串的关系:存储json格式数据的文件叫做json文件,json文件内并不存储双引号;json文件被读取后,read方法自动返回字符串(json字符串);所以json格式的数据在程序内表现形式为字符串,在文件内表现为正常的文本文件。
#practice16:XML文件的解析与创建
1、解析xml文档

1.1 预先准备的xml文件
<?xml version="1.0"?>
<data>
<country name="liechtenstein">
<rank updated="yes">5</rank>
<year>2008</year>
<gdp>141100</gdp>
</country>
<country name="china">
<rank updated="yes">2</rank>
<year>2010</year>
<gdp>1422000</gdp>
</country>
<country name="american">
<rank updated="no">1</rank>
<year>2010</year>
<gdp>3122000</gdp>
</country>
</data>1.2 解析xml文档的基本操作
from xml.etree.ElementTree import parse
with open('demo.xml','r') as rf:
#返回ElementTree对象
et = parse(rf)
#获取根节点,返回Element对象
root = et.getroot()
print(root)
#获取某个Element对象的标签、属性以及文本
print(root.tag)
print(root.attrib)
print(root.text)
#获取某个element对象的直接子元素,返回值为element对象
print(root.getchildren())
#element对象自身可迭代
for child in root:
#get函数返回element object 对应的attribute(‘name')的值,get获取元素属性值
print(child.get('name'))
#find与findall一般用法默认查找直接子元素
print(root.find('country'))
print(root.findall('country'))
print(root.iterfind('country'))
for ele in root.iterfind('country'):
print(ele)
#iter方法用来生成某个element下所有子元素的迭代器(包括非直接子元素)
print(list(root.iter()))
#指定元素的tag
print(list(root.iter('rank')))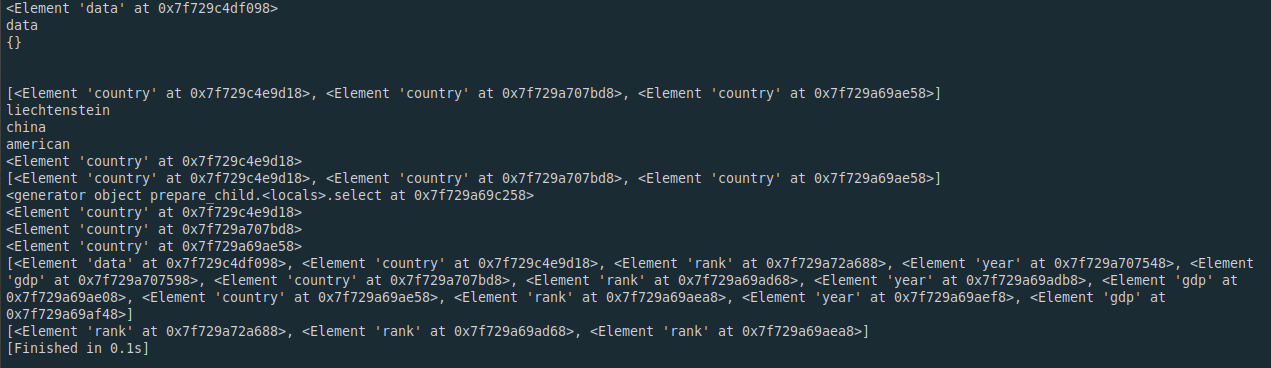
上述方法的标签参数均使用当前位置,借助xpath的语法可以操作任意位置的元素
from xml.etree.ElementTree import parse
with open('demo.xml','r') as rf:
et = parse(rf)
root = et.getroot()
print(root.findall('rank'))
#.代表当前元素,即root节点;//代表当前节点下所有子节点(包括非直接节点)
print(root.findall('.//rank'))
#..表示当前元素的父元素;/类似于Linux
print(root.findall('.//rank/..'))
#*代表所有直接子元素
print(root.findall('*/gdp'))
#带属性的元素
print(root.findall('country[@name]'))
print(root.findall('country[@name="china"]'))
#任然要指明路径
print(root.findall('rank[@updated]'))
print(root.findall('.//rank[@updated]'))
#包含某个直接子元素的元素(不支持非直接元素)
print(root.findall('country[rank]'))
#element[childelement="text"],text即便是数字也要加引号
print(root.findall('country[rank="1"]'))
#findall找到的多个元素可以使用位置参数取出来
print(root.findall('country[rank][1]'))
print(root.findall('country[rank][2]'))
print(root.findall('country[rank][last()]'))
print(root.findall('country[rank][last()-1]'))
#注意:text文本都是string,即便看到是数字,读取后还需要进一步处理转换。
print(type(root.find('.//rank[@updated="no"]').text))
附录:支持的xpath语法

2、使用python数据结构创建xml
2.1 xml创建操作
from xml.etree.ElementTree import Element,ElementTree,tostring
#创建一个元素
e = Element('data',{'name':"wakak"})
#tostring函数以字符串的形式展现整个元素
print(tostring(e))
#修改或增加元素属性,注意属性必须是字符串
e.set('age','18')
e.set('name','wahahah')
print(tostring(e))
#修改或增加元素的text,xml是个文本文件,所以数字也要用字符串的形式写入
e.text = "123.0"
print(tostring(e))
#创建父子关系
e1 = Element('row')
e1.text = "row1"
e2 = Element('hello')
e2.text = 'hello world'
e1.append(e2)
e.append(e1)
print(tostring(e))
#创建elementTree
et = ElementTree(e)
et.write("demo1.xml")
tostring默认为byte字符串
2.2 csv文件转xml文件实例
#csv转xml
import csv
from xml.etree.ElementTree import Element,ElementTree
def csv_to_string(filename):
with open(filename,'rt',encoding='utf-8') as rf:
reader = csv.reader(rf)
header = next(reader)
root = Element('data')
#下面的写法可以避免获取csv文件的行数!!
for row in reader:
#可以看出row可迭代!迭代返回值为list,可迭代:
print(type(row))
e = Element('row')
root.append(e)
#用到了zip函数+元组拆包
#同样避免了计算行长度
for tag,text in zip(header,row):
e1 = Element(tag)
e1.text = text
e.append(e1)
et = ElementTree(root)
return et
et = csv_to_string('pingan.csv')
#此处必须表明编码格式,若省略,默认us-ascll !!!,解析会乱码
et.write('demo2.xml',encoding='utf-8')

#practice17:设置文件缓冲

1、行缓冲(只用于文本模式)
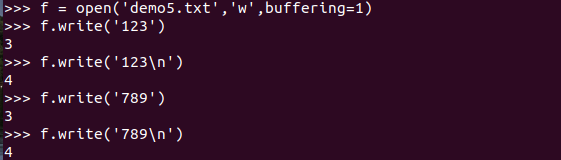

2、 全缓冲
只有二进制模式下,buffering参数才生效;文本模式下buffering采用默认值io.DEFAULT_BUFFER_SIZE,linux下为8192

当凑满2049byte后,前2048byte才被真正写入文件
3、 无缓冲(只用于二进制模式)


#practice18:二进制文件映射到内存

优点:为了随机访问文件的内容,使用 mmap 将文件映射到内存中是一个高效和优雅的方
法。例如,你无需打开一个文件并执行大量的 seek() , read() , write() 调用,只需
要简单的映射文件并使用切片操作访问数据即可。
import mmap
#创建一个24byte的二进制非空文件,b'\x00'并不是空byte字符串
size = 24
with open('demo.bin','wb') as wf:
wf.seek(size-1)
wf.write(b'\x00')
#将二进制文件映射到内存,r+b一般为固定值,二进制可读可写,会产生符合要求的fileno
with open('demo.bin','r+b') as f:
fileno1 = f.fileno()
#下面的代码必须放在with语句内,因为一旦文件关闭,文件描述符fileno1就失效了
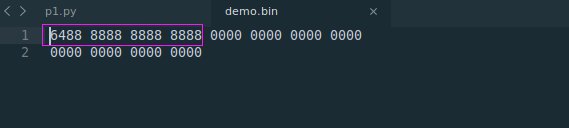
mm = mmap.mmap(fileno1,0,access=mmap.ACCESS_WRITE)
print(mm[0])
print(type(mm[0]))
print(mm[:8])
#切片赋值可以用byte字符串
mm[0:8] = b'\x88'*8
#必须用int来给单个元素赋值
mm[0] = 100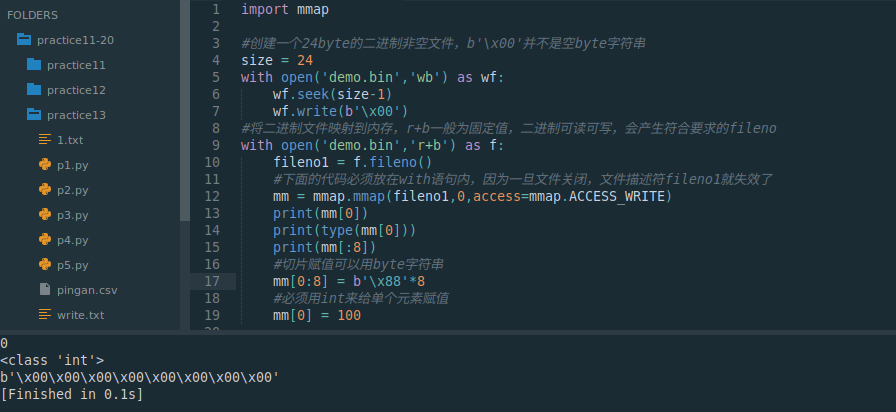
#practice19:访问文件状态

1、 获取文件状态(3种方法)
import os
#调用系统stat函数,对于link文件,针对其源文件调用函数
s = os.stat('demo.txt')
#返回os.stat_result对象
print(s)
print(type(s))
#调用系统lstat函数,对于link文件,针对当前的文件名调用函数
s = os.lstat('demo.txt')
#返回os.stat_result对象
print(s)
print(type(s))
#调用系统fstat函数,该函数的参数必须为打开的文件描述符
with open('demo.txt') as f:
s = os.fstat(f.fileno())
#返回os.stat_result对象
print(s)
print(type(s))
2、 os.stat_result对象的十大属性(常用如下)
- st_mode:文件模式,包括文件类型与权限
- st_uid:user ID
- st_gid:group ID
- st_size:文件大小byte
- st_atime:最后打开时间
- st_ctime:最后修改时间
3、 stat模块的使用(负责翻译os.stat_result对象)
import os
import stat
import time
s = os.stat('demo.txt')
print(s)
#输出文件mode
print(s.st_mode)
#使mode可读
print(stat.filemode(s.st_mode))
#判断文件类型
print(stat.S_ISDIR(s.st_mode))
print(stat.S_ISREG(s.st_mode))
print(stat.S_ISLNK(s.st_mode))
#判断文件权限
#判断文件属主是否有读权限;结果非空->True.结果为0,False;
print(s.st_mode & stat.S_IRUSR)
print(s.st_mode & stat.S_IXUSR)
#文件访问、修改时间
#返回结构化时间对象,细粒度
print(time.localtime(s.st_mtime))
#返回时间字符串!
print(time.asctime(time.localtime(s.st_atime)))
#获取文件大小,byte
print(s.st_size)
4、 用OS.path模块实现stat中的部分功能(不涉及文件权限,推荐用此方法)
import os.path
import time
#os.path内的函数内部调用os.stat 来获取文件状态,所以使用时可省略这一步!
#判断文件类型
print(os.path.isdir('demo.txt'))
print(os.path.islink('demo.txt'))
print(os.path.isfile('demo.txt'))
#判断文件大小
print(os.path.getsize('demo.txt'))
#判断修改,打开时间
print(os.path.getmtime('demo.txt'))
print(time.asctime(time.localtime(os.path.getatime('demo.txt'))))os.path模块不包含处理文件权限的函数

#practice20:使用临时文件存储内存数据

1、 两个类的基本用法
from tempfile import TemporaryFile,NamedTemporaryFile
import tempfile
#临时文件的默认存放地
print(tempfile.gettempdir())
#创造临时文件来存储大的数据,避免数据空耗内存;mode一般选取w+b 或 w+t
#temporary创建的临时文件在/tmp中也找不到
#返回文件对象!
f = TemporaryFile(mode='w+t')
f.write('#'*1000000)
f.close()
#使用namedtemporary创建带名字的临时文件,该文件在/tmp中找得到
#返回类文件对象
f1 = NamedTemporaryFile(mode='w+t')
print(f1.name)
f1.write('%'*10000)
#使用delete后,临时文件关闭后,文件不被立即删除
f2 = NamedTemporaryFile(mode='w+t',delete=False)
print(f2.name)
f2.write('%'*1000)
#这个地方不好验证,最好还是使用python控制台来验证临时文件的创建过程与差别
2、使用python控制台来验证temporaryfile与namedtemporaryfile
