《第一二 章 MySQL体系结构与InnoDB存储引擎》
mysql体系结构
MySQL是一个单进程多线程架构的数据库,区别于其他数据库最重要的特点就是其插件式的表存储引擎,需要注意的是存储引擎是基于表的,而不是数据库。MySQL由以下几部分组成:连接池组件、管理服务和工具组件、SQL接口组件、查询分析器组件、优化器组件、缓冲(Cache)组件、插件式存储引擎、物理文件。
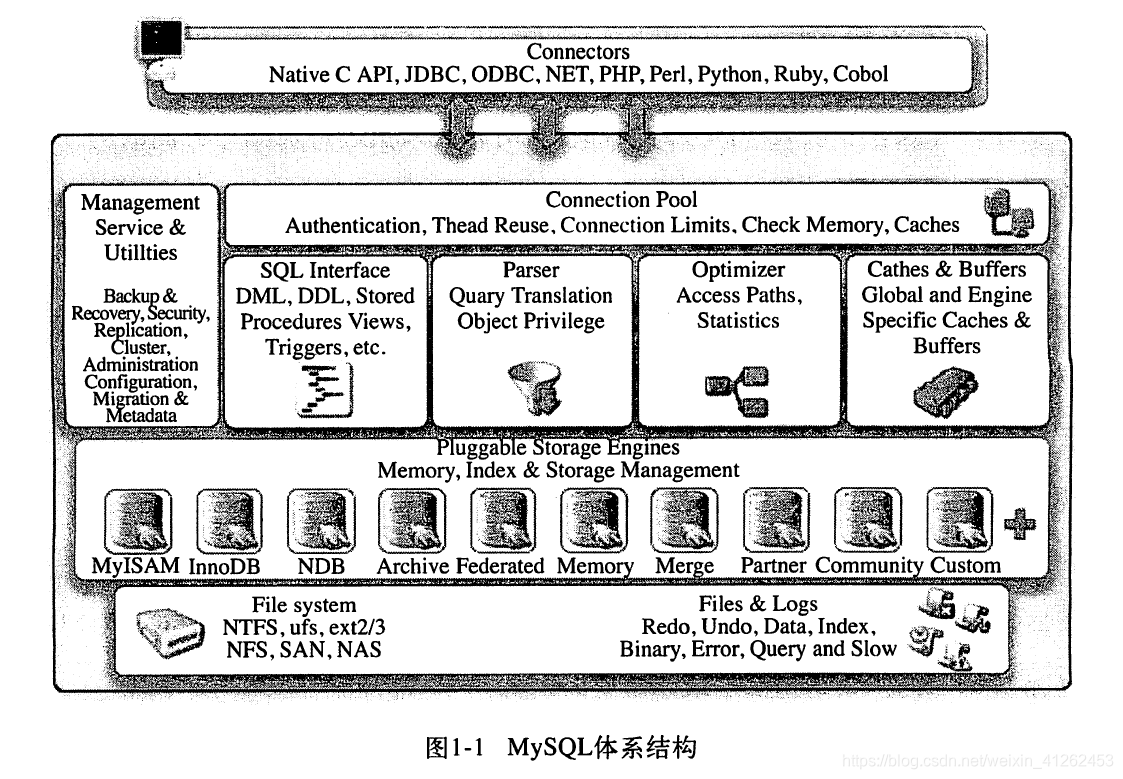
注意:插件式体系结构是MySQL独有的,并且存储引擎是MySQL区别于其他数据库的一个最重要特性。存储引擎是基于表的,而不是数据库。
当启动MySQL时,MySQL会先去读取配置文件,根据配置文件的参数来启动数据库实例,查找配置文件。你可在mysql安装路径下输入以下指令,你会发现mysql是按照/etc/my.cnf /etc/mysql/my.cnf /usr/local/mysql/etc/my.cnf ~/.my.cnf 顺序来读取配置文件,并且会以最后一个配置文件为准。因此,在linux环境下,一般配置文件都放在/etc/my.cnf下。

我的配置文件在/etc/my.cnf下,查看该文件,你可以看到配置文件中有参数datadir,该参数指定了数据库所在的路径。
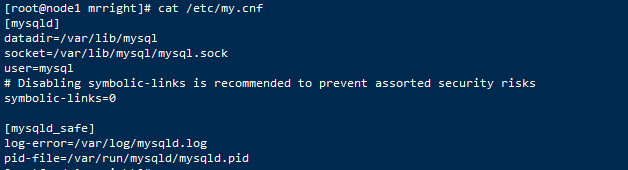
当然,你也可以在mysql中查看该datadir参数值
MySQL存储引擎比较
| 存储引擎类型 | 特点 |
|---|---|
| InnoDB存储引擎 | 支持事务,主要面向在线事务处理(OLTP)方面的应用,支持行锁设计、外键以及类似于Oracle的非锁定读,提供插入缓冲、二次写、自适应哈希索引、预读等高性能与高可用功能 |
| MyISAM存储引擎 | 不支持事务、表锁和全文索引,MyISAM存储引擎表由MYD和MYI组成,MYD用来存放数据文件,MYI用来存储索引文件,MyISAM默认支持的表为4G |
| NDB存储引擎 | 与Oracle的 RAC share everything结构不同,采用 share nothing的集群结构,数据全部放在内存中,因此主键查找速度极快。通过添加NDB数据存储节点,可以线性的提高数据库性能 |
| Memory存储引擎 | 即HEAP存储引擎,将表中的数据放在内存中,适用于存储临时数据的临时表和数据仓库中的纬度表。默认使用哈希索引,而不是B+树索引能 |
| Maria存储引擎 | 缓存数据和索引文件,行锁设计,提供MVCC功能,支持事务和非事务安全的选项支持,以及更好的BLOB字符类型的处理性能。 |
| Archieve存储引擎 | 只支持INSERT和SELECT操作,5.1版本开始支持索引。使用zlib算法将数据行进行压缩后存储,适用于存储归档数据,如日志信息。使用行锁来实现高并发的插入操作,本身非事务安全,设计目标为提供高速的插入和压缩功能。 |
以下表格可以看出各个引擎存储容量的限制、事务支持、锁的粒度、MVCC支持、支持的索引、备份和复制等区别。
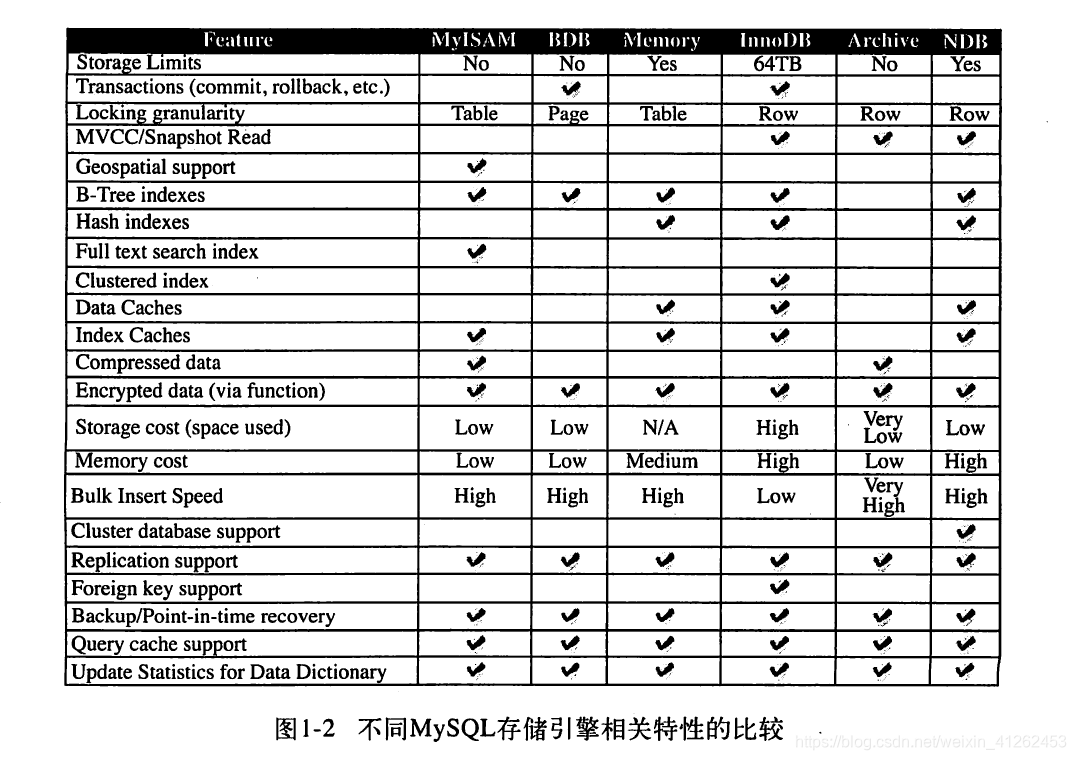
各种存储引擎的特点都不相同,不同的存储引擎直观上的表现就是,同一张表设置成不同类型的存储引擎的大小都是不同的,很多数据库原理的书中,会提到数据库与传统的文件系统最大区别在于数据库是否支持事务,而MySQL设计数据库引擎时却认为并不是所有的应用都需要事务。通过show engines语句可以查看当前的mysql所支持的存储引擎。

InnoDB体系架构
InnoDB体系架构包括:后台线程、内存池。
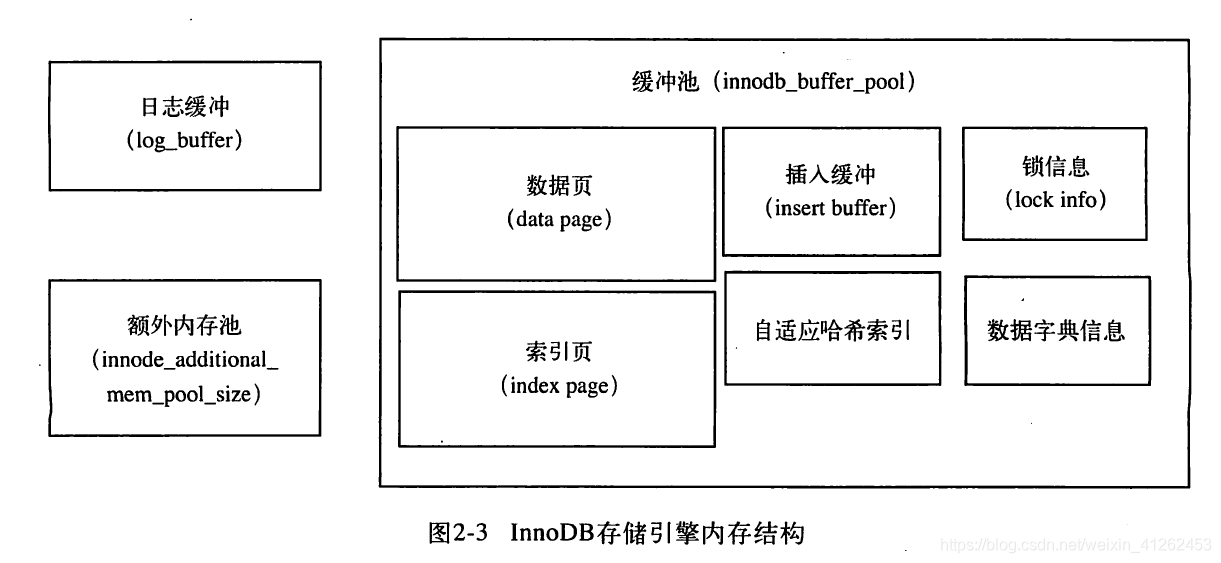
- 内存池:维护所有进程/线程需要访问多个数据结构,缓存磁盘上数据,脏页checkpoint磁盘前数据缓存,重做日志redo log缓冲
后台线程:
- Master Thread : 核心的后台线程,主要将缓冲池中的数据换新到磁盘中,保证数据一致性。脏页刷新,合并插入缓冲,UNDO页(数据修改之前备份的数据用于rollback)
- IO Thread :Async IO (write,read,insert buffer,log) InnoDB 1.0.X后read write 分别增大4个。可以通过Innodb_read_io_threads和innodb_write_io_threads 。命令: show
variables like ‘INNODB_%IO_THREADS’\G; - Purge Thread:清除线程,当事务被提交时候undo log就是不在需要,因此需要回收,故设立单独线程,减缓master thread 压力,提高存储性能。数据库配置文件添加独立命令启动purge thread:[mysqld] innodb_purge_threads=1 innodb 1.2 后可以设置4个purge threads
- Page Cleaner Thread :InnoDB1.2后面 脏页刷入磁盘单独放到一个线程完成减轻master thread 压力,有利于查询阻塞线程和提高存储引擎的性能。
后台线程作用:负责刷新内存池中的数据,保证缓存中是最近的数据,修改后的数据文件刷新到磁盘,保证数据库发生异常的情况下Innodb恢复到正常运行状态。
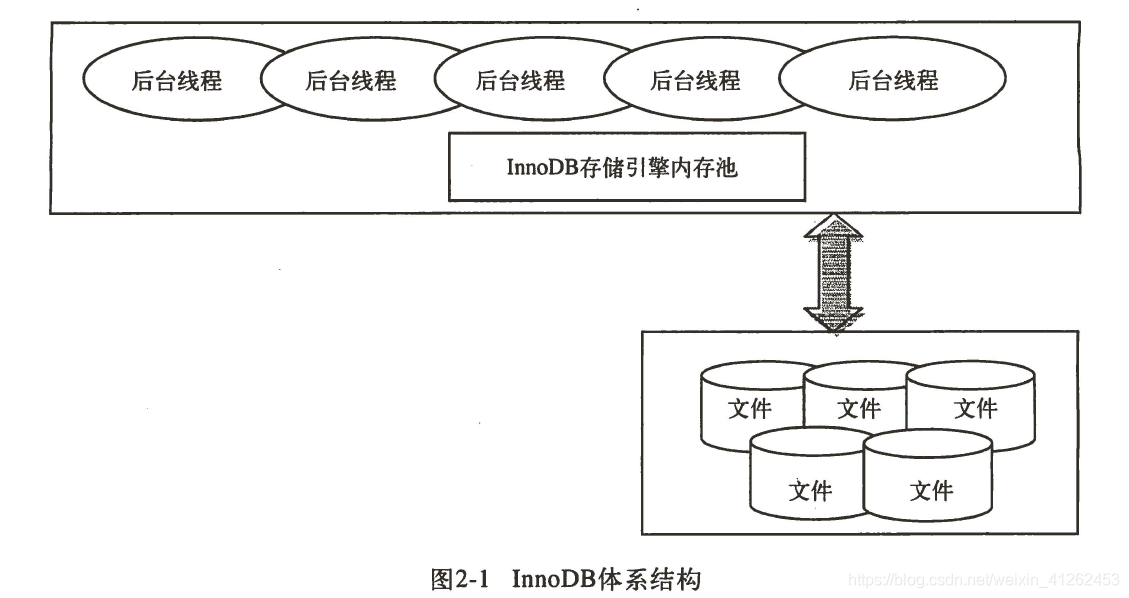
通过输入show engine innodb status;可以查看出InnoDB存储引擎后台线程有7个,4个 IO thread,1个master thread ,1个lock 监控线程,1个错误监控线程。在Linux平台下,IO Thread数量不能进行调整,但是windows下可以通过参数innodb_file_io_threads增大IO Thread。
InnoDB存储引擎中的内存
InnoDB存储引擎内存由缓冲池、重做日志缓冲池、额外的内存池组成,分别由配置文件中的参数innodb_buffer_pool_size和innodb_log_buffer_size大小决定。具体来看,缓冲池中缓存的数据页类型有:索引页、数据页、undo页、插入缓冲、自适应哈希索引、InnoDB存储的锁信息、数据字典信息等。不能简单的认为,缓冲池只是缓存索引页和数据页,当然这两种占据了很大一部分。
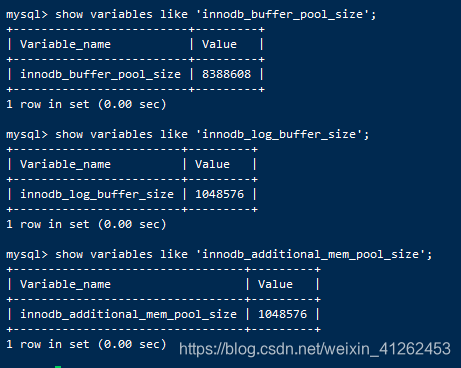
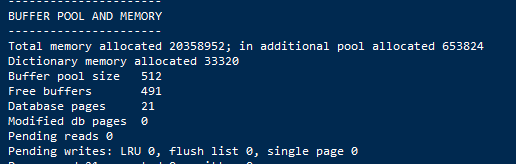
可以看出我的缓冲池大小为8M,日志缓冲池为1M,额外的内存池为1M。value的大小是字节。
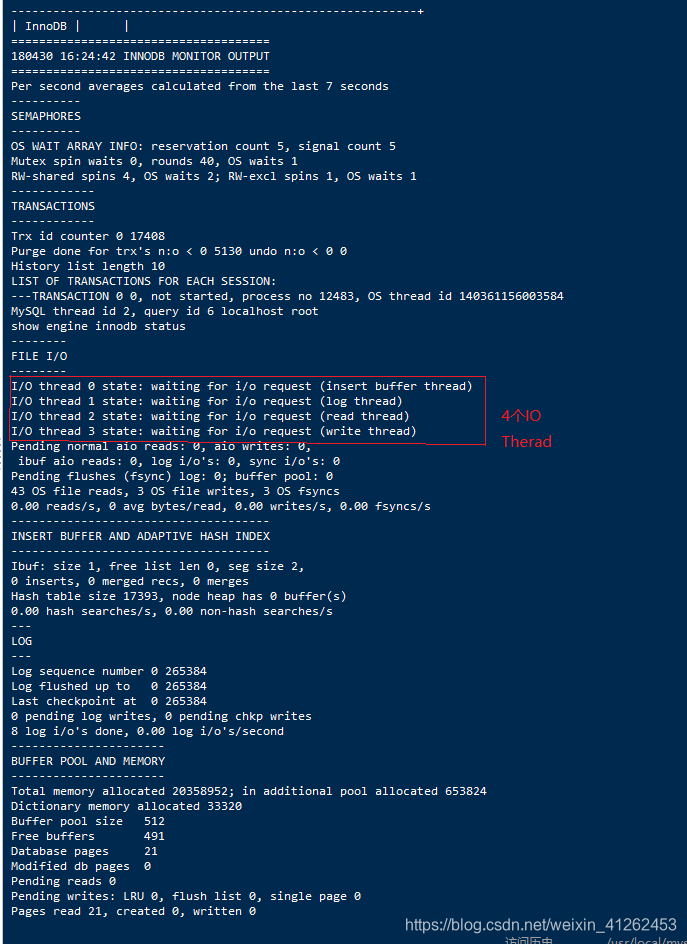
通过之前的show engine innodb status;指令可以看出内存中的各个缓冲池占用情况,此处单位表示有多少个缓冲帧,一个缓冲帧是16K,所以,缓冲池是51216K/1024K = 8M,还剩49116/1024 = 7.67M大小。
InnoDB Master Thread
Master Thread完成了Innodb存储引擎的主要工作,Master Thread内部由主循环loop,后台循环background loop,刷新循环flush loop,暂停循环suspend loop。每一个循环都会在执行不同的事情,例如loop主循环:从伪代码中可以看出,在每10秒中,可能会刷新100个脏页到磁盘,总是会合并至少5个插入缓冲,总是将日志缓冲刷新至磁盘。(脏页:就是内存中的数据对应硬盘的数据有所改变.改变后的数据页就叫做脏页)

分析InnoDB架构体系中的后台线程的Master Thread中的绝大多数loop,你可以看出InnoDB存储引擎最多只会刷新100个脏页到磁盘,合并20个插入缓冲,这可以解释为什么大多数的数据库写性能存在瓶颈原因,因此当在密集写的应用程序中,每秒可能会产生超过100个脏页,此时master换忙不过来。Google工程师mark进行了修正,在此之后,innodb plugin提供了一个innodb_io_capacity参数,用于表示磁盘IO的吞吐量,默认值为200.因此Master Thread合并插入缓冲或者从缓冲区刷新脏页时,会按照innodb_io_capacity的百分比来刷新。规则为:在合并插入缓冲,合并插入缓冲的数量为innodb_io_capacity数值的5%,从缓冲区刷新脏页的数量为innodb_io_capacity。
另外还有几个关键参数会影响innoDB的性能。
- innodb_max_dirty_pages_pct的值,该值表示脏页占缓冲池的百分比,google测试推荐采用80,可以保证刷新脏页的频率同时能保证磁盘的负载。
- innodb_adaptive_flushing自适应刷新参数,该值影响每一秒刷新脏页的数量。
InnoDB关键特性
插入缓冲(insert buffer)
知识补充:聚集索引和非聚集索引的根本区别是表记录的排列顺序和与索引的排列顺序是否一致
- 聚集索引:聚集索引表记录的排列顺序和索引的排列顺序一致,所以查询效率快,只要找到第一个索引值记录,其余就连续性的记录在物理也一样连续存放。聚集索引对应的缺点就是修改慢,因为为了保证表中记录的物理和索引顺序一致,在记录插入的时候,会对数据页重新排序。
- 非聚集索引:制定了表中记录的逻辑顺序,但是记录的物理和索引不一定一致,两种索引都采用B+树结构,非聚集索引的叶子层并不和实际数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针方式。非聚集索引层次多,不会造成数据重排。
InnoDB存储引擎开创性设计了插入缓冲,对于非聚集索引的插入或者更新操作,不是每一次直接插入索引页,而是先判断插入的非聚集索引页是否在缓冲池中,如果在,则直接插入。如果不在,则先放入一个插入缓冲区,想骗一下数据库这个非聚集的索引已经插入到叶子节点了,然后再以一定的频率执行插入缓冲和非聚集索引页子节点的合并操作,这时通常能将多个插入合并到一个操作中(因为在一个索引页中),这就大大提高了对非聚集索引执行插入和修改操作的性能。
当插入缓冲满足两个条件:索引是辅助索引,索引不是唯一的时,InnoDB使用插入缓冲能提高性能。
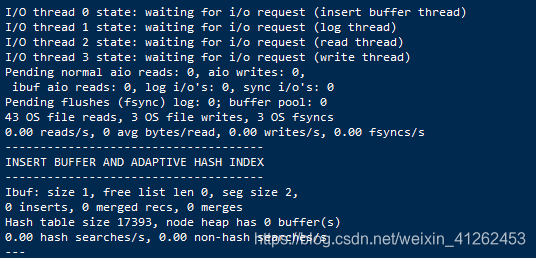
同是指令show engine innodb status; seg size显示了当前插入缓冲的大小为2*16KB,即32KB。下一行,Inserts代表插入的记录数,merged recs代表合并的页的数量,merges 表示合并的次数。
两次写(Double write)
插入缓冲给InnoDB存储引擎的是性能,那么两次写是给InnoDB存储引擎带来数据可靠性保证。当数据库戎机时,可能发生数据库正在写一个页面,而这个页只能写一部分(比如16K的页,只写前4K的页)的情况,我们称之为部分写失效(partial page write);
有人或许会想,如果发送写失效,可以通过重做日志进行恢复,这确实是一个办法。但是需要注意的是重做日志中记录的是对物理操作,如偏移量800,写’aaa’记录。如果这个页本身已经损坏了,再对其进行重做是没有意义的。这就是说,在应用(apply)重做日志之前,我们需要一个页的副本,当写入失效发生时,先通过页的副本来还原该页,再进行重做,这就是doublewrite.innodb存储引擎doublewerite;
doublewrite由两部分组成:一部分是内存中的doublewrite buffer,大小为2MB;另一部分是物理磁盘上共享表空间中连续的128个页,即两个区(extent),大小同样为2MB;当缓冲池的脏页刷新时,并不直接写磁盘,而是会通过memcpy函数将脏页先拷贝到内存中的doublewrite buffer,之后通过doublewrite再分两次,每次写入1MB到共享表空间的物理磁盘上,然后马上调用fsync函数 ,同步磁盘,避免缓冲写带来的问题。在这个过程中,因为doublewrite页是连续的,因此这个过程是顺序写的开销并不是很大。在完成doublewrite页的写入后,再将doublewrite buffer中的页写入各个表空间文件中,此时的写入则是离散的。
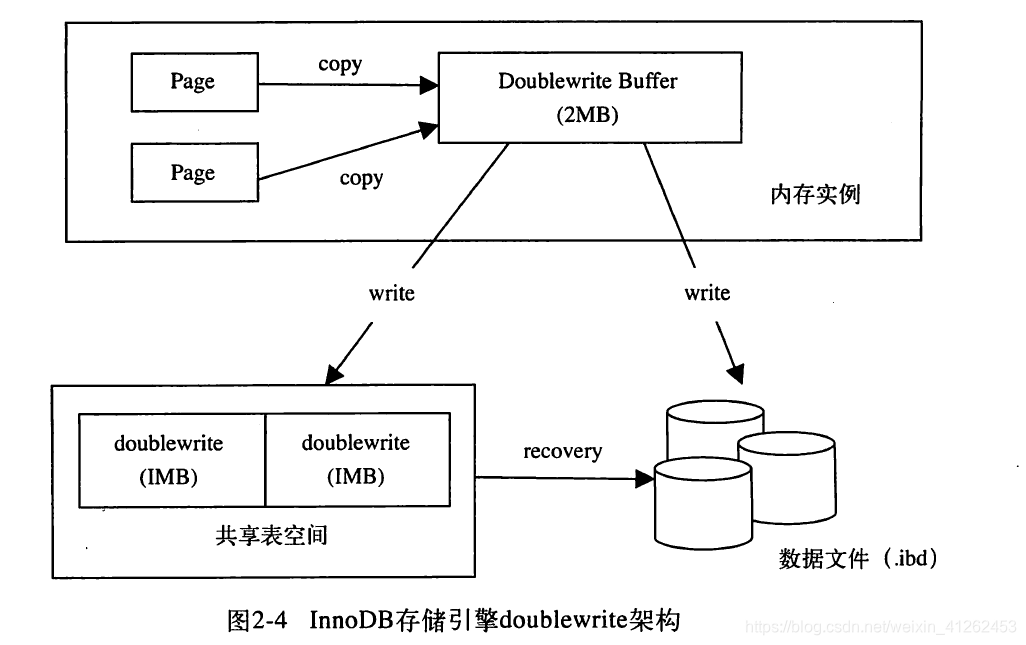
如果操作系统在将页写入磁盘的过程中崩溃了,在恢复过程中,Innodb存储引擎可以从共享表中的doublewrite找到改页的一个副本,将其拷贝到表空间文件,再应用重做日志。参数skip_innodb_doublewrite可以禁止使用两次写功能,这时可能会发生前面提及的写失效问题。注意:有些文件系统本身就提供了部分写失效的防范机制,如ZFS文件系统。在这种情况下,我们就不要启用doublewrite了。
可以通过以下命令观察double write运行状况: 可以看到,doublewrite 一共写了10005304个页,但实际的写入次数为3272391,如果你发现你的系统在高峰时Innodb_dblwr_pages_written:Innodb_dblwr_writes远小于64:1,那么说明你的系统写入压力并不是很高.
mysql> show global status like 'innodb_dblwr%'\G;
*************************** 1. row ***************************
Variable_name: Innodb_dblwr_pages_written
Value: 10005304
*************************** 2. row ***************************
Variable_name: Innodb_dblwr_writes
Value: 3272391
rows in set (0.01 sec)
自适应哈希索引(adaptive hash index)
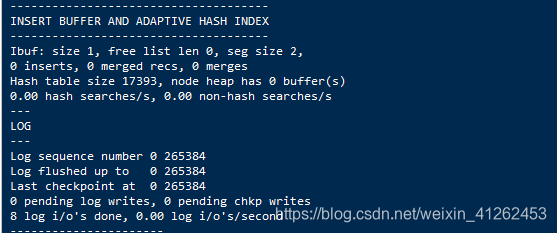
哈希(hash)是一种非常快的查找方法,在一般情况下这种查找的时间复杂度为O(1),即一般仅需要一次查找就能定位数据。而B+树的查找次数,取决于B+树的高度,在生成环境中,B+树的高度一般3-4层,故需要3-4次的查询。Innodb存储引擎会监控对表上索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立hash index,所以称之为自适应(Adaptive Hash Index,AHI )的。自适应哈希索引通过缓冲池的B+tree构造而来,因此建立的速度很快。
同样可以从show engine innodb status; 中查看到INSERT BUFFER AND ADAPTIVE HASH INDEX。
在MySQL 5.1.38版本之前,你需要安装InnoDB Plugin时,必须要下载Plugin文件,解压后在进行一系列安装,但从MySQL 5.1.38开始后,MySQL提供了两个版本的InnoDB的存储引擎,旧版本的引擎称为build-in innodb,另一个是1.0.4版本的InnoDB存储引擎。 InnoDB Plugin = 新版本的InnoDB存储引擎。当你想用新的InnDB Plugin引擎时,只需要在配置文件中进行设置即可。