1、msyql引擎,区别,适用场景
存储引擎:如何存储data,为存储的data建立索引,如何更新、查询data等技术的实现方法
数据库的表有不同的类型,对应mysql不同的存取机制,表类型又称存储引擎
- InnoDB存储引擎
- 支持事务,支持外键,
- 行锁设计,默认读取操作不会产生锁
- 查表总行数时,需要全表扫描
- 如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表
- MyISAM
- 不支持事务,不支持外键
- 表锁设计。插入data时,锁定整个表
- 查表总行数时,不需要全表扫描
- 如果执行大量的SELECT,MyISAM是更好的选择
- Memory存储引擎
- data放在内存中,数据库重启或发生崩溃,表中的data消失
- 哈希索引,不是B+树索引
NDB存储引擎
是一个集群存储引擎,类似于 Oracle 的 RAC 集群BLACKHOLE 黑洞存储引擎
应用于--主备复制中的---分发主库
2、事务 (存储过程实现的)
事务(Transaction)是并发控制的基本单位。
将某些操作的多个sql作为原子性操作,这些操作要么都执行,要么都不执行,一旦某一个出现错误,即可回滚到原来的状态,从而保证数据库数据的完整性
ACID
- 原子性(Atomicity):一堆sql语句,要么不执行,要么全部执行
- 一致性(Consistency):事务开始前,结束后,数据库的完整性约束没有被破坏
- 隔离性(Isolation):多个事务并发访问时,事务之间是隔离的,锁实现的
- 持久性(Durability):事务一旦提交,对数据库中的data改变是永久的,不会被回滚
https://blog.csdn.net/shuaihj/article/details/14163713
事务的三个常用命令
Begin Transaction、Commit Transaction、RollBack Transaction。
3、join什么时候用?有几种?区别
多表连接查询、有外键关联
- inner join(内连接):只匹配2张表中相关联的记录。
- left join(外连接之左连接):优先显示左表全部记录,在内连接的基础上增加左表有右表没有的结果,右表中未匹配到的字段用NULL表示。
- right join(外连接之右连接):优先显示右表全部记录,在内连接的基础上增加右表有左表没有的结果,左表中未匹配到的字段用NULL表示
- full join(全外连接):内连接基础,增加左表有右表没有和右表有左表没有的结果;连接的表中不匹配的数据全部会显示出来。
mysql 不支持full join 但是可以用 union - 交叉连接:笛卡尔积,显示的结果是连接表数的乘积。
4、存储过程
相当于函数,封装了,一系列预编译可执行的sql语句,存放在MySQL中。
直接调用它的名字,可以执行其内部的一堆sql
优点:
1.程序与sql解耦。一个存储过程替代大量sql语句
2.执行效率高。存储过程是预编译的一个代码块
3.网络传输量小。传别名的数据量小,传sql数据量大
4.确保数据安全。执行存储过程需要用户有一定权限
缺点:
1.程序猿拓展功能不方便
2.移植性差create procedure p1()
BEGIN
SELECT * FROM TABLE1;
END
#在mysql中调用
call p1() 5、视图
视图是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增删改查
create view table1_view as select * from table1; 6、触发器
触发器是一种特殊的存储过程,通过事件来触发而被执行的。
使用触发器可以定制用户对表进行增、删、改操作前后的行为
create trigger tri_after_insert_table1 after insert on table1 for each row
BEGIN
SELECT * FROM TABLE1;
END7、索引是什么?什么时候用?
相当于,新华字典的,音序表
数据库管理系统中,一个排序好的数据结构,协助快速查询data,范围查询data
create index ix_age on table1(age);
create index 索引名1,索引名2 on 表名('字段1','字段2')优势
1.可以大大加快数据的检索速度,(这也是创建索引的最主要的原因)
2.分组和排序,显著减少时间
3.加速表和表之间的连接
4.创建唯一性索引,保证每一行数据的唯一性
代价
1.增加了数据库的存储空间,(每一个索引需要占用物理空间)
2.插入与修改data要花费较多时间,(index索引也跟着变动)什么时候用?
1. 经常select查询
2. 表记录超级多
3. 列。经常搜索的列、主键列、外键列、排序的列、where上的列、范围查找的列 age in [20,40]
什么时候不用?
1. 经常update、delete、insert
2. 表记录少
3. 列。不经常使用的列、数据值很少的列(固定电话)、定义为文本,图片,bit的列、修改性能远远大于检索性能的列B+树:二叉树---平衡二叉树---B树---B+树---B-树---B*树---红黑树
http://www.cnblogs.com/oldhorse/archive/2009/11/16/1604009.html
https://blog.csdn.net/samjustin1/article/details/52664514
https://blog.csdn.net/xiaqunfeng123/article/details/52534468
https://blog.csdn.net/qq_26768741/article/details/53164202
B+树
用途:用于数据库索引,操作系统的文件系统中
特点:保持data稳定有序,插入与修改有较稳定的对数时间复杂度O(logN)
1.所有关键字的信息,都出现在叶子节点
2.所有非叶子节点,不存储data,只存储key,递增排列
3.为所有叶子节点增加一个链指针
4.非叶子节点的key,是其子树的最大或最小关键字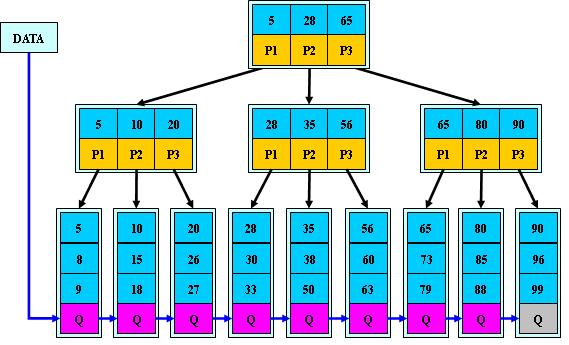
8.Mysql索引用B+树而不用B-树或者红黑树
Mysql如何衡量查询效率呢?– 磁盘IO次数
1.B+树节点小,磁盘I/O次数少
B+树。叶节点存放data,其他节点用来索引
B-树。每个索引节点都会有data区域
红黑树。树的深度过大,IO读写频繁
2.B+树,支持范围查询,B树不支持
所有的叶子节点用指针串起来,遍历叶子节点,就能获得全部数据,可以进行区间访问https://blog.csdn.net/xiedelong/article/details/81417049
9、DDL、DML、DCL
DDL (define) 数据库定义语言 database、table、view、index、producer、drop
DML(manager) 数据库操纵语言 insert、delete、update、select
DCL (control) 数据库控制语言 grant,revoke 权限
10、说一说三个范式。
- 第一范式(1NF):数据库表中的字段都是单一属性的,不可再分。
学生信息表,有姓名、年龄、性别、学号等信息组成 - 第二范式(2NF):满足第一范式,表中的字段必须完全依赖于全部主键而非部分主键。
要有主键,要求其他字段都依赖于主键。 - 第三范式(3NF):满足第二范式,非主键外的所有字段必须互不依赖
就是数据只在一个地方存储,不重复出现在多张表中,可以认为就是消除传递依赖
消除传递依赖,方便理解,可以看做是“消除冗余”。
所谓传递函数依赖,指的是如 果存在"A → B → C"的决定关系,则C传递函数依赖于A。
11、drop、delete与truncate简单说一说区别
SQL中的drop、delete、truncate都表示删除,但是三者有一些差别
1.delete和truncate只删除表的数据不删除表的结构
2.速度,一般来说: drop> truncate >delete
3.delete语句是dml,这个操作会放到rollback segement中,事务提交之后才生效;如果有相应的trigger,执行的时候将被触发.
4.truncate,drop是ddl, 操作立即生效,原数据不放到rollback segment中,不能回滚. 操作不触发trigger.
5.安全性:小心使用drop 和truncate,尤其没有备份的时候 ,不可回滚分别在什么场景之下使用?
1.不再需要一张表的时候,用drop
2.想删除部分数据行时候,用delete,并且带上where子句
3.保留表而删除所有数据的时候用truncate 12、sql语句
查询来自杭州,并且订单数少于2的客户。
select a.customer_id, count(b.order_id) as total_orders
from table1 as a left join table2 as b
on a.customer_id = b.customer_id
where a.city = 'hangzhou'
group by a.customer_id
having count(b.order_id) < 2
order by total_orders desc
limit 1;13、char与varchar区别
char是固定长度的类型
vachar是可变长度的类型
char(10):定长,字符长度为10,浪费空间,存取速度快
root存成root000000,数据不足时,右边用空格填充
varchar(10):变长,字符长度10,,精准,节省空间,存取速度慢
存储数据的真实内容,不会填充,
1-2bytes的数据字节数 + 真实数据root14、数据库优化问题
(1)服务层面:配置mysql性能优化参数;
(2)系统层面:优化数据表结构、字段类型、字段索引、分表,分库、读写分离等等。
(3)数据库层面:优化SQL语句,合理使用字段索引。
(4)代码层面:使用缓存和NoSQL数据库方式存储,MongoDB/Memcached/Redis来缓解高并发下数据库查询的压力。
(5)减少数据库操作次数,尽量使用数据库访问驱动的批处理方法。
(6)不常使用的数据迁移备份,避免每次都在海量数据中去检索。
(7)提升数据库服务器硬件配置,或者搭建数据库集群。
(8)编程手段防止SQL注入15、在数据库中查询语句速度很慢,如何优化?
1.建索引
2.减少表之间的关联
3.优化sql,尽量让sql很快定位数据,不要让sql做全表查询,应该走索引,把数据 量大的表排在前面
4.简化查询字段,没用的字段不要,尽量返回少量数据
16、数据库优化的思路
1.SQL语句优化
用Where子句替换HAVING 子句,因为HAVING 只会在检索出所有记录之后才对结果集进行
2.索引优化
看上文索引
3.数据库结构优化
1)范式优化: 比如消除冗余(节省空间。。)
2)反范式优化:比如适当加冗余等(减少join)
3)拆分表、拆分库
4)读写分离
4.服务器硬件优化17、你了解redis吗?
- 高性能,非关系型数据库,内存数据库,减少磁盘I/O
- key-value类型,hashmap实现,复杂度O(1),查找与操作速度快
- 丰富的数据类型,string,list,set,hash
- 支持事务,操作都是原子性
- 必要时部分存在硬盘上
- 丰富的特性、可用于缓存,消息,按key设置过期时间,过期自动删除
- mySQL里有2000w数据,redis中只存20w的热点数据,内存数据集达到一定大小的时候,施行数据淘汰策略(过期时间、最少使用)