搭建linux虚拟机
下载virtualbox,下载地址:https://www.virtualbox.org/wiki/Downloads,然后安装。
下载centos操作系统,http://isoredirect.centos.org/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-1804.iso,然后在virtualbox中新建虚拟机。
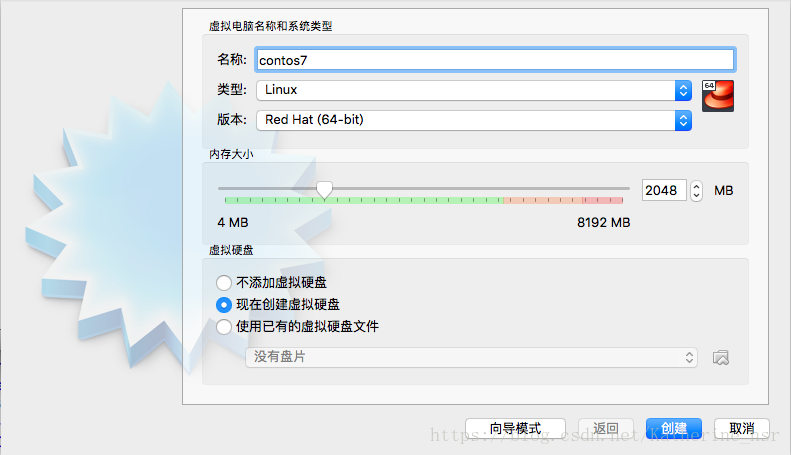
创建名字和分配内存,内存在虚拟机关机或者暂停时不占用,因此可以根据实际需要稍微调整大一些
然后选择硬盘大小,记得选择动态分配,这样可以根据真正使用的大小来实际占用磁盘空间。

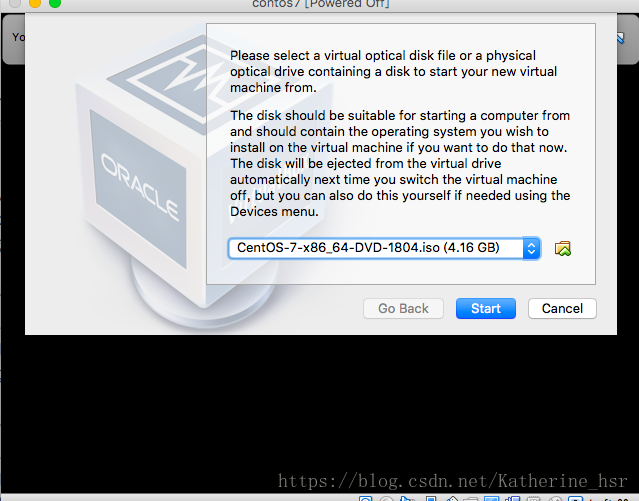
创建完成后,在虚拟机列表中可以看到刚刚新建的虚拟机,双击打开。会提示选择镜像文件,然后将上面下载的centos-7选择进去,然后start开始安装虚拟机。
虚拟机安装完成后,选择用户语言,各位可根据自身需要和爱好进行设置语言。
紧接着设置用户名密码,linux系统默认有一个root用户,你也可以新建一个用户设置为管理员
安装完成后,会提示重启。
配置ssh访问虚拟机
重启后开始配置通过ssh命令(也可以使用XShell工具)来访问虚拟机,好处是不用在主机与虚拟机中来回切换以及复制粘贴考虑。
首先查看虚拟机ip
ip addr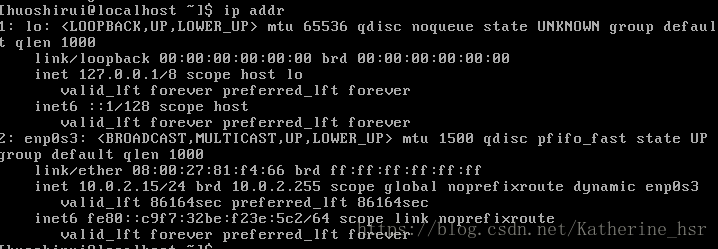
如果没有看到第二个ip,不要担心,因为centos7默认是关闭网卡的。因此我们可以把默认开启
sudo vi /etc/sysconfig/network-scripts/ifcfg-enp0s3其中enp0s3是根据ip addr命令看到的一致
打开后显示的是
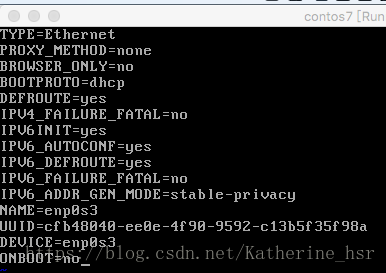
需要把此处的ONBOOT=no改为ONBOOT=yes,修改后重启网络服务
sudo service network restart 重启后再输入即可看到如上的ip地址了
然后命令
ssh loginname@ip输入密码登录。
配置pyspark
在当前用户目录下创建一个spark目录
mkdir spark
cd spark进入spark目录后,下载spark文件
wget http://mirrors.hust.edu.cn/apache/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz如果出现wget命令找不到是因为centos默认最小安装,没有安装wget工具,因此执行
sudo yum install wget
然后重新执行wget命令下载spark文件,下载过程如图

下载完成后解压
tar -xf spark-2.3.1-bin-hadoop2.7.tgz然后配置spark环境变量
sudo vi /etc/profile在最末尾添加一句
PATH=/home/huoshirui/spark/spark-2.3.1-bin-hadoop2.7/bin:$PATH添加的具体路径根据下载路径决定
然后执行
source /etc/profile
echo $PATH然后执行命令pyspark
如果当前没有安装java环境配置JAVA_HOME则会进行提示,因此需要安装java环境配置JAVA_HOME,可以使用快捷安装
sudo yum install java然后java安装完成后,再次运行pyspark
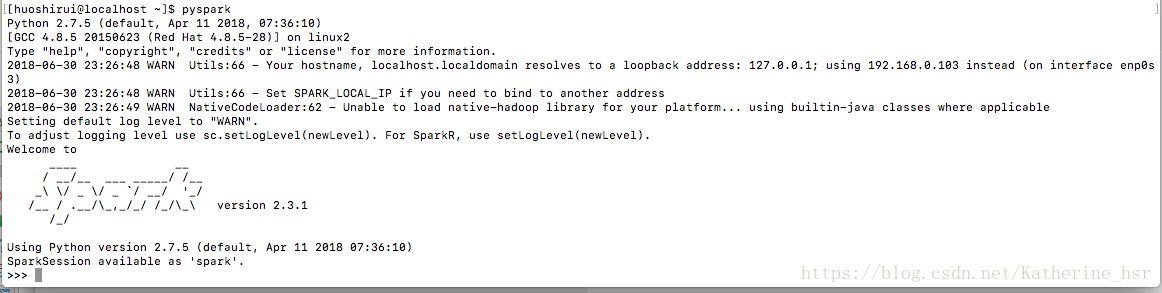
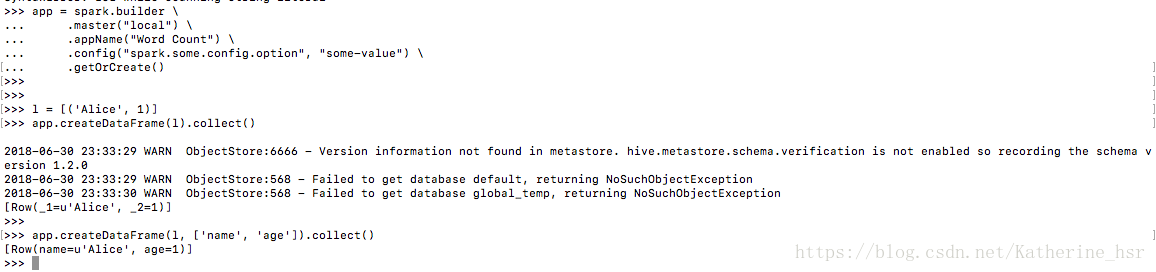
然后运行简单代码:
app = spark.builder \
.master("local") \
.appName("Word Count") \
.config("spark.some.config.option", "some-value") \
.getOrCreate()
l = [('Alice', 1)]
app.createDataFrame(l).collect()
app.createDataFrame(l, ['name', 'age']).collect()最终出现结果如下,pyspark安装成功