总结的很好的一篇博客:https://blog.csdn.net/App_12062011/article/details/81665140
定点化:
百度搜“模型压缩定点化”
https://blog.csdn.net/u011961856/article/details/76736103
http://fjdu.github.io/machine/learning/2016/07/07/quantize-neural-networks-with-tensorflow.html
https://petewarden.com/2015/05/23/why-are-eight-bits-enough-for-deep-neural-networks/
基于量化的模型压缩
所谓量化,指的是减少数据在内存中的位数操作,例如,对于权重来说,如果大多数都在0附近,那么32位的浮点表示,其实是有很大浪费的。这一方向的研究,主要是8位类型来表示32位浮点(定点化),甚至直接训练低8位模型,二值模型。其作用不仅可以减少内存开销,同时,可以节省带宽,通过某些定点运算方式,甚至可以消除乘法操作,只剩加法操作,某些二值模型,直接使用位操作。当然,代价是位数越低,精度下降越明显。
一般情况下,采用8位定点运算表示,理论上,可以节省4倍内存,带宽,但是实际上,不是所有的模型参数,都可以定点化,这涉及到性能与加速的平衡。
但是 ,需要注意的是,如果你的模型本身够快,那么8位定点化操作, 可能没有加速或者甚至变慢,因为,浮点转定点,本身也是一笔开销。大量浮点运算是比较慢,但是,模型参数不是很大的情况下,这种慢的差别在现代编译器及硬件环境上几乎体现不出来的,甚至可能量化开销导致性能变慢。
剪枝:
Pruning Filters for Efficient Convnets
作者提出了基于量级的裁剪方式,用weight值的大小来评判其重要性,对于一个filter,其中所有weight的绝对值求和,来作为该filter的评价指标,将一层中值低的filter裁掉,可以有效的降低模型的复杂度并且不会给模型的性能带来很大的损失,算法流程如下:

算每个channel的绝对值,按从小到大排序不同channel,把绝对值最小的m个channel删除,并把相对应的下一层的channel也剪掉(这个相对应我还不知道怎么回事),你可以逐层剪枝再finetune,也可以所有层剪完再finetune
文章还分析了不同层剪枝的敏感度,234层敏感度高,个人觉得这几层是提基础特征,所以更加敏感,自己剪枝也主要再后面层;还有个原因前面层参数更少,越少的越剪性能就越差
An Entropy-based Pruning Method for CNN Compression
作者认为通过weight值的大小很难判定filter的重要性,通过这个来裁剪的话有可能裁掉一些有用的filter。因此作者提出了一种基于熵值的裁剪方式,利用熵值来判定filter的重要性。 作者将每一层的输出通过一个Global average Pooling将feature map转换为一个长度为c(filter数量)的向量,对于n张图像可以得到一个n*c的矩阵,对于每一个filter,将它分为m个bin,统计每个bin的概率,然后计算它的熵值 利用熵值来判定filter的重要性,再对不重要的filter进行裁剪。第j个feature map熵值的计算方式如下:
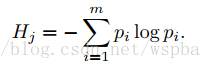
这篇论文的笔记:https://blog.csdn.net/u013082989/article/details/77943240