版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_32297447/article/details/79876523
本博客的学习目标:
了解Sqoop是什么,能做什么以及架构
能够进行Sqoop环境部署
MySql<=>HDFS数据的导入导出
准备工作:
Hadoop伪分布式集群环境:
CentOS7下安装配置Mysql:
Sqoop 命令使用官网:
Sqoop 导入导出官网:
1、Sqoop概述(SQl TO HADOOP)
1.1、官网:
http://sqoop.apache.org/
Sqoop是一款开源的工具,主要用于在HADOOP(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,底层是通过
mapreduce作业完成的,
充分利用了MapReduce的并行特点以批处理的方式加快数据的传输,同时也借助MapReduce实现了容错。
Sqoop1.x只有map没有reduce,Sqoop2.x既有map也有reduce
1.2、产生背景
场景:传统型数据库RDBMS与Hadoop(HDFS/Hive/HBase)相互的导入导出
导入导出的出发点是基于Hadoop角度来说
1)导入 import: RDBMS => Hadoop
2)导出 export: Hadoop => RDBMS
注意:RDBMS与HDFS/Hive之间的转换通常是双向的,但是与HBase之间通常是单向的(RDBMS=>HBase)
解决方案:MR作业
导入: DBInputFormat TextOutputFormat
导出: TextInputFormat DBOutputFormat
存在问题:开发繁琐,需求变更修改麻烦,没法复用
1.3、Sqoop优势
高效、可控的利用资源
支持多种数据库
2、Sqoop架构
2.1、Sqoop1.X

Sqoop1.x中,仅仅使用了一个Sqoop客户端,它是单用户的、架构部署简单。客户端发送命令到Sqoop,Sqoop转换为MapReduce作业运行在Hadoop集群环境上,从而实现RDBMS和Hadoop之间相互导入导出。Sqoop1.x只一个mapreduce作业,只有map没有reduce
2.2、Sqoop2.X

Sqoop2.x 中,引入了sqoop server集中化管理Connector,支持多种交互方式:命令行、Web UI、Rest API,所有的链接安装在sqoop server上,完善了权限管理机制(可配置管理员、使用者等角色),Connector规范化( 不再包含数据传输,格式转换、与Hive、Hbase交互等功能仅负责数据读写)。Sqoop2.x中的MapReduce作业既有Map也有Reduce
3、Sqoop安装部署(基于Hadoop伪分布式环境)
3.1、下载
3.2、解压
$ tar -zxvf sqoop-1.99.5-bin-hadoop200.tar.gz
$ mv sqoop-1.99.5-bin-hadoop200 sqoop
bin 目录下存放了sqoop的执行脚本,默认这些执行脚本是没有可执行权限的,所以要授予可执行权限
$ cd sqoop/bin
$ chmod a+x *

3.3、安装配置依赖
3.3.1、创建两个相关目录:
$ mkdir extra
$ mkdir logs

3.3.2、环境变量:
#Sqoop2
export SQOOP_HOME=/home/hadoop/app/sqoop
export PATH=$PATH:$SQOOP_HOME/bin
export SQOOP_SERVER_EXTRA_LIB=$SQOOP_HOME/extra
export CATALINA_BASE=$SQOOP_HOME/server
export LOGDIR=$SQOOP_HOME/logs/
3.3.3、修改Sqoop配置文件:
使用如下命令找到本机hadoop的安装路径:$ find / -name hadoop

配置服务端
$ cd /server/conf
$ vi sqoop.properties
这里可以采用
/org.apache.sqoop.submission.engine.mapreduce.configuration.directory
搜索hadoop的目录,找到并修改其路径,如下:

安装依赖
在sqoop的server/conf目录下的catalina.properties文件中配置Hadoop 库的路径,修改common.loader这个参数来包含Hadoop 库的所有目录,输入如下命令,进入Hadoop库所在目录
$ cd $HADOOP_HOME/share/hadoop

将上图中所有目录下的jar包都添加到common.loader参数中
$ cd sqoop/server/conf $ vi catalina.properties
可以采用/
common.loader搜索这个参数,然后进行修改,这里其实修改的都是hadoop路径如下图所示:

common.loader=${catalina.base}/lib,${catalina.base}/lib/*.jar,${catalina.home}/lib,${catalina.home}/lib/*.jar,${catalina.home}/../lib/*.jar,
/home/hadoop/app/hadoop/share/hadoop/common/*.jar,
/home/hadoop/app/hadoop/share/hadoop/common/lib/*.jar,
/home/hadoop/app/hadoop/share/hadoop/hdfs/*.jar,
/home/hadoop/app/hadoop/share/hadoop/hdfs/lib/*.jar,
/home/hadoop/app/hadoop/share/hadoop/httpfs*.jar,
/home/hadoop/app/hadoop/share/hadoop/httpfs/../lib/*.jar,
/home/hadoop/app/hadoop/share/hadoop/mapreduce/*.jar,
/home/hadoop/app/hadoop/share/hadoop/mapreduce/lib/*.jar,
/home/hadoop/app/hadoop/share/hadoop/tools/lib/*.jar,
/home/hadoop/app/hadoop/share/hadoop/yarn/*.jar,
/home/hadoop/app/hadoop/share/hadoop/yarn/lib/*.jar
安装Mysql JDBC驱动
将MySQL的JDBC驱动放入server/lib/目录下即可(这个驱动hive目录lib下面就有)
$ cp mysql-connector-java-5.1.38.jar $SQOOP2_HOME/server/lib/
配置sqoop代理访问
因为sqoop访问Hadoop的MapReduce使用的是代理的方式,必须在Hadoop中配置所接受的proxy用户和组,找到Hadoop的core-site.xml配置文件,添加如下内容,重启Hadoop即可
<property>
<name>hadoop.proxyuser.sqoop2.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.sqoop2.groups</name>
<value>*</value>
</property>
验证配置是否成功
$ sqoop2-tool verify
如果看到类似如下的信息,恭喜你Sqoop的安装配置已经成功

如果启动成功还报下面没有数据连接的错误,启动日志追踪
JobHistoryServer进程即可
Exception in thread "PurgeThread" org.apache.sqoop.common.SqoopException: JDBCREPO_0009:Failed to finalize transaction
Caused by: java.sql.SQLNonTransientConnectionException: No current connection.
Caused by: java.sql.SQLException: No current connection.
启动Sqoop服务端
$ sqoop2-server start 启动
$ sqoop2-server stop 关闭

Sqoop的日志信息默认存放在/home/hadoop/@LOGDIR@目录下的sqoop.log文件中,该目录可在sqoop.properties配置文件中的
org.apache.sqoop.log4j.appender.file.File
这个属性中设置,笔者使用的是默认,输入如下命令查看sqoop的日志信息
$ tail -fn200 /home/hadoop/@LOGDIR@/sqoop.log
注意:在使用Sqoop之前要启动Hadoop集群服务,包括dfs、yarn以及日志追踪JobHistoryServer,如果JobHistoryServer不启动,你可能在后面启动job时会报拒绝链接,连接失败等错误。服务端启动后使用jps命令查看多出一个Bootstrap进程为成功
启动客户端
使用以下命令,以交互式模式启动客户端
$ sqoop2-shell
我们在使用的过程中可能会遇到错误,使用以下命令来使错误信息显示出来
sqoop:000> set option --name verbose --value true
连接Sqoop服务端 sqoop:000> set server --host [服务端所安装的主机名] ### 使用上面自动连接即可(set server --host 服务端所安装的主机名 --port 12000 --webapp sqoop)
验证是否已经连上
sqoop:000> show version --all ##查看所有服务信息
client version:
Sqoop 1.99.5 source revision 9665c01f674d69d41a6fcfffb2c0b94590f70f59
Compiled by vbasavaraj on Wed Feb 18 09:42:27 PST 2015
0 [main] WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
server version:
Sqoop 1.99.5 source revision 9665c01f674d69d41a6fcfffb2c0b94590f70f59
Compiled by vbasavaraj on Wed Feb 18 09:42:27 PST 2015
API versions:
[v1]
如果打印出类似上面的形式,表示已经连上了
可以使用help命令来检查sqoop shell所支持的命令:
sqoop:000> helpFor information about Sqoop, visit: http://sqoop.apache.org/
Available commands:
exit (\x ) Exit the shell
history (\H ) Display, manage and recall edit-line history
help (\h ) Display this help message
set (\st ) Configure various client options and settings
show (\sh ) Display various objects and configuration options
create (\cr ) Create new object in Sqoop repository
delete (\d ) Delete existing object in Sqoop repository
update (\up ) Update objects in Sqoop repository
clone (\cl ) Create new object based on existing one
start (\sta) Start job
stop (\stp) Stop job
status (\stu) Display status of a job
enable (\en ) Enable object in Sqoop repository
disable (\di ) Disable object in Sqoop repository
For help on a specific command type: help command
退出Sqoop
sqoop:000>
exit
集群服务启动命令:
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
sqoop2-server start
集群服务关闭命令:
sqoop2-server stop
mr-jobhistory-daemon.sh stop historyserver
stop-yarn.sh
stop-dfs.sh
==================================================================
MySql<=>HDFS数据的导入导出
在使用sqoop导入导出数据前,先使用如下命令来查看下详情模式的状态(默认为false)
sqoop:000> show option --name verbose
Sqoop 1.99.5版本中支持的连接器如下
sqoop:000> show connector

查看link
sqoop:000> show link

查看job
sqoop:000> show job
=============================================================================
1.创建link对象
1.1、创建mysql的link对象
sqoop:000> create link -c 1

1.2、创建hdfs的link对象
sqoop:000> create link -c 3

1.3、查看创建的link对象
sqoop:000> show link
sqoop:000> show link -a ##显示详细信息

2、MySQL导入数据到HDFS
原理:
Sqoop与数据库通信,获取数据库表的元数据信息;Sqoop启动一个Map-Only的MR作业,利用元数据信息并行将数据写入Hadoop
注释:
将mysql表t_student的数据导入到HDFS的/user/hadoop/sqoop/t_student路径下
2.1、创建job
sqoop:000> create job -f 1 -t 2


2.2、查看创建的job
sqoop:000> show job
详细信息:sqoop:000> show job -jid 1
2.3、启动任务(执行MapReduce作业)
sqoop:000> start job -j 1 -s
看到显示Job executed successfully就表明执行完成
2.4、查看运行结果
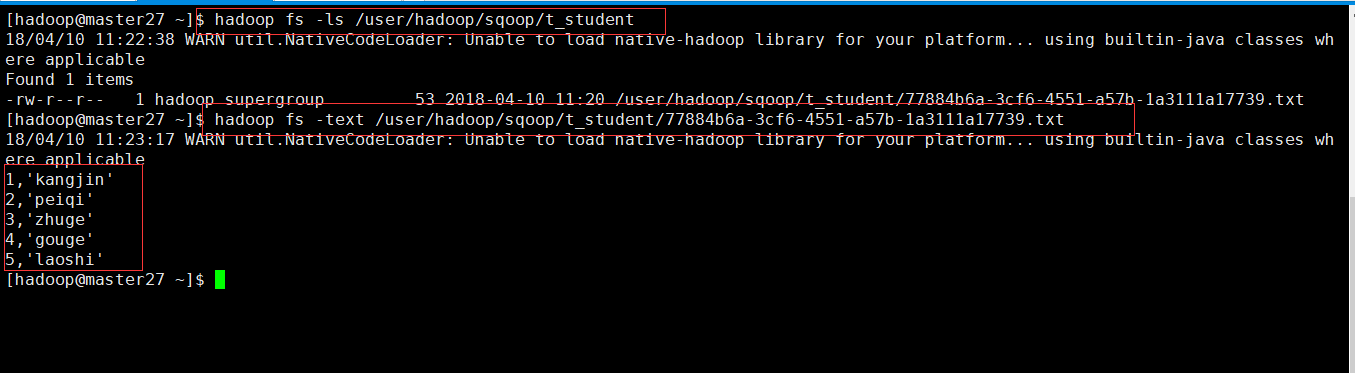
[hadoop@master27 ~]$ hadoop fs -ls /user/hadoop/sqoop/t_student
[hadoop@master27 ~]$ hadoop fs -text /user/hadoop/sqoop/t_student/77884b6a-3cf6-4551-a57b-1a3111a17739.txt
3、HDFS导入数据到MySQL
实现需求:将HDFS的/user/hadoop/sqoop/t_student路径下的数据导出到MySQL中的t_student_from_hdfs中
3.1、MySQL中创建表
t_student_from_hdfs
3.2、创建job
sqoop:000> create job -f 2 -t 1

3.3、查看创建的job
sqoop:000> show job
3.4、启动任务(执行MapReduce作业)
sqoop:000> start job -j 2 -s
看到显示Job executed successfully就表明执行完成
3.5、查看运行结果
