本文是根据考研数据结构2019版天勤高分笔记理解编写的:
首先给出代码:
1 void getnext(Str substr,int next[]){
2 int i=0,j=0;
3 next[1]<=0;
4 while(i<substr.length){
5 if(j==0 || substr.ch[i]==substr.ch[j]){ //俩种情况会导致j==0。a,给串第一个元素的next[1]赋值时j默认为0 b,当模式串和主串不匹配时,j回溯到next[1]=0
//当前元素和已经匹配的串(正在延伸的前缀)的下一个元素进行比较,相等就继续延伸,否则j进行回溯,第10行(需要明白next的作用)
6 ++i;++j;
7 next[i]=j; //j表示0-j-1的前缀和后面一部分的子串已经匹配成功
8 }
9 else{
10 j=next[j]; //j回溯
11 }
12 }
13 }
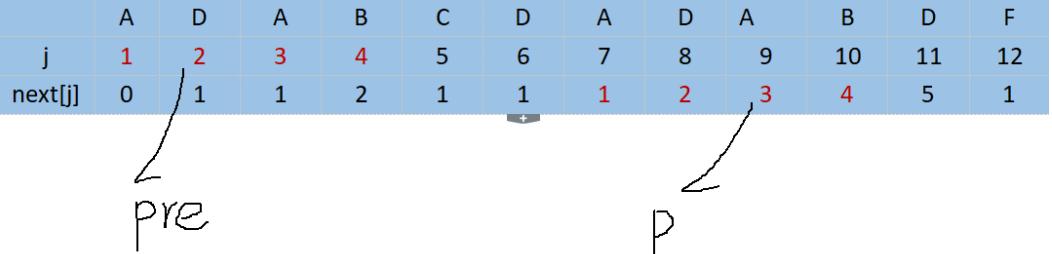
数组pre和数组p一致,即next[j]代表已匹配前缀串pre的下标 如:j=5就代表已匹配的前缀ADAB的下标1,2,3,4
当j=5时,ch[11]!=ch[5],此时,退而其次,在已匹配的串"ADAB"中寻找能匹配D的元素。
而next数组的作用就是当模式串中第j个字符发生不匹配时,应从next[j]处的字符开始重新与主串比较。所以j回溯的时候用的是j=next[j];
只是:为什么next能起这样的作用呢?给个串对照一下:

这里我只把上面那部分的串的4位置和10位置的B改成了A,next数组只有next[5]由1变成了2.
现在讲讲我自己的理解:1,回退的过程中不仅2位置要和11位置想对应,2位置之前的所有位置(虽然这里只有一个元素)都必须和11位置前的响应元素一一对应,而next数组就代表前面有多个字符和前缀匹配成功。
2,正如前面所说的,数组pre和数组p一致,即next[j]代表已匹配前缀串pre的下标 ,,为什么改next【5】是2,对应了2(下标)位置的D,因为4位置的A和前缀A匹配。
=》保证俩个元素比较前,前缀和 j 位置前的对应长度的串是相等的(也就 是next的作用)
c和D不匹配ADAA这个前缀串的前缀是A,回溯到j=2,此时是保证了2(因为举例较简单,所以前缀只有一个元素,但我们可以把2位置发散成n位置)位置前所有的前缀(2-1 即n-1)个元素是和C元素前(2-1 即n-1)个元素匹配成功的;
而"ADAAC"和"ADAAD"中的"ADAA"的元素是匹配成功的,所以保证了ch【2-1】=ch【5-1】=ch【11-1】同样,这里的ch虽然只是一个字符,但也可以发散成一个串。
3,如果没有符合要求的子串,j必定回溯到1.
小编也是花了一整天根据自己对书本的理解,如果大家有什么不明白还请耐心点,kmp需要时间来理解!