简介
Keepalived是一个用C语言编写的路由软件,该项目的主要目标是为Linux系统和基于Linux的基础设施提供简单而健壮的负载均衡和高可用性设施。负载均衡依赖于提供第四层负载均衡广泛使用的Linux虚拟服务器(IPVS)内核模块。Keepalived实现了一组检查器,用于根据负载均衡服务器池的健康状况动态地和自适应地维护和管理负载均衡服务器池。另一方面,通过VRRP协议实现了高可用性。VRRP是路由器故障转移的基础砖。此外,Keepalived实现了一组到VRRP有限状态机的钩子,提供了低级和高速的协议交互。Keepalived框架可以独立使用,或者一起使用以提供弹性基础结构。
Keepalived架构图
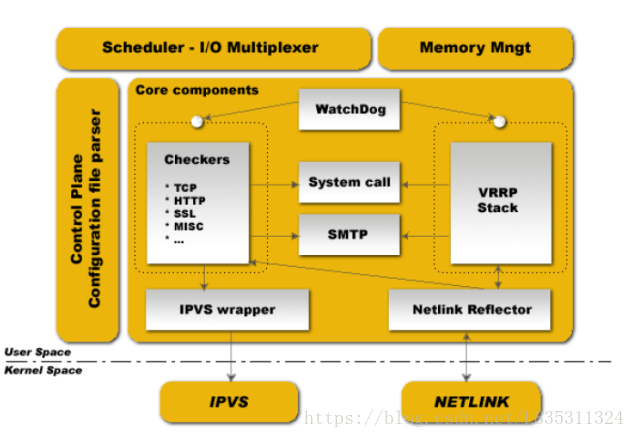
图片来自Keepalived权威指南
- WatchDog:提供了对子进程(VRRP和healthchecker)的监控
- Checkers组件:负责RealServer的健康状况检查,并在LVS的拓扑中移除、添加RealServer。它支持layer4/5/7层的协议检查。该组件使用独立的子进程负责,但被父进程监控。
- VRRP组件:提供Director的故障转移功能从而实现Director的高可用。该组件可独立提供功能,无需LVS的支持。该组件使用独立的子进程负责,但被父进程监控。
- System Call组件:提供读取自定义脚本的功能。该组件在使用时,将临时产生一个子进程来执行任务。
- IPVS wrapper组件:负责将配置文件中IPVS相关规则发送到内核的ipvs模块。
- Netlink Reflector:用来设定、监控vrrp的vip地址。
Keepalived故障切换转移原理
keepalived之间的故障切换转移,是通过VRRP协议实现的
在keepalive directors 正常工作时,主节点会不断的向备节点广播心跳信息,用以告诉备节点自己还活着,当主节点发生故障,备节点无法继续监测主节点的心跳,进而调用自身的接管程序,接管主节点的ip资源以及服务,而从节点恢复故障时,备节点会释放主节点故障时自身接管的ip资源以及服务,恢复到自身的备用角色
安装
yum install keepalived -y配置文件
组成部分
##global全局配置
global_defs {
notification_email { #定义邮件收件人
root@localhost
}
notification_email_from keepalived@localhost #定义邮件发件人
smtp_server 127.0.0.1 #邮件服务器
smtp_connect_timeout 30 #连接超时时间
router_id node1 #用来标识当前机器,可以用主机名
vrrp_mcast_group4 224.0.100.19 #多播地址
}
##vrrp协议配置
vrrp_instance VI_1 { #vrrp名称,可以自定义
state BACKUP #当前节点状态,MASTER|BACKUP
interface ens33 #vip绑定的网络接口
virtual_router_id 14 #虚拟路由标识(VRID),同一实例该数值必须相同,
#即master和backup中该值相同同一网卡上的不同vrrp实例,该值必须不能相同。取值范围0-255
priority 98 #优先级
advert_int 1 #vrrp通告的时间间隔;
authentication { #简单认证
auth_type PASS
auth_pass 571f97b2 #密码
}
virtual_ipaddress { #设置的VIP。只有master节点才会设置。master出现故障后,VIP会故障转移到backup。
#这些vip默认配置在interface指定的接口别名上,可使用dev选项来指定配置接口。
#使用ip add的方式添加。若要被ifconfig查看,在IP地址后加上label即可。
#<IPADDR>/<MASK> brd <IPADDR> dev <STRING> scope <SCOPE> label <LABEL>
10.1.0.91/16 dev ens33 ##vip绑定在en33网卡接口
}
notify_master "/etc/keepalived/notify.sh master" #状态为主节点时,触发的脚本,脚本需要自定义
notify_backup "/etc/keepalived/notify.sh backup" #状态为备节点时,触发的脚本,脚本需要自定义
notify_fault "/etc/keepalived/notify.sh fault" #节点down了,触发的脚本,脚本需要自定义
}
#虚拟服务
virtual_server {
delay_loop 1 #服务轮询的时间间隔,单位s;
lb_algo rr #定义调度方法,rr|wrr|lc|wlc|lblc|sh|dh;
lb_kind DR #集群的类型;NAT|DR|TUN
persistence_timeout 1:#持久连接时长;
protocol TCP #服务协议,仅支持TCP;
sorry_server 127.0.0.1 80 #备用服务器地址; <IPADDR> <PORT>
real_server 10.1.0.69 80 { #定义real server部分
weight 1 #LVS权重
HTTP_GET { #健康状况检查的检查方式,常见的有HTTP_GET|SSL_GET|TCP_CHECK|MISC_CHECK。
url {
path / #定义要监控的URL
status_code 200 #判断检测机制为健康状态的响应码
#digest <STRING>:判断检测机制为健康态状的响应的内容的校验码;需要比对页面内容的校验码可以用genhash或者直接md5sum 生成然后写在这里
}
nb_get_retry 3 #重试次数;
delay_before_retry 1 #重试之前的延迟时长;
#connect_ip <IP ADDRESS>:向当前RS的哪个IP地址发起健康状态检测请求
#connect_port <PORT>:向当前RS的哪个PORT发起健康状态检测请求
#bindto <IP ADDRESS>:发出健康状态检测请求时使用的源地址;
#bind_port <PORT>:发出健康状态检测请求时使用的源端口;
connect_timeout 1 #连接请求的超时时长;
}
#TCP_CHECK { tcp健康检查示例
#connect_ip <IP ADDRESS>:向当前RS的哪个IP地址发起健康状态检测请求
#connect_port <PORT>:向当前RS的哪个PORT发起健康状态检测请求
#bindto <IP ADDRESS>:发出健康状态检测请求时使用的源地址;
#bind_port <PORT>:发出健康状态检测请求时使用的源端口;
#connect_timeout <INTEGER>:连接请求的超时时长;
# }
}
real_server 10.1.0.71 80 {
weight 1
HTTP_GET {
url {
path /
status_code 200
}
connect_timeout 1
nb_get_retry 3
delay_before_retry 1
}
}
}