一 序
本文接上一篇介绍锁类型之后。主要分为 两部分。第一部分介绍表锁行锁加锁流程。第二部分常见的死锁检测。
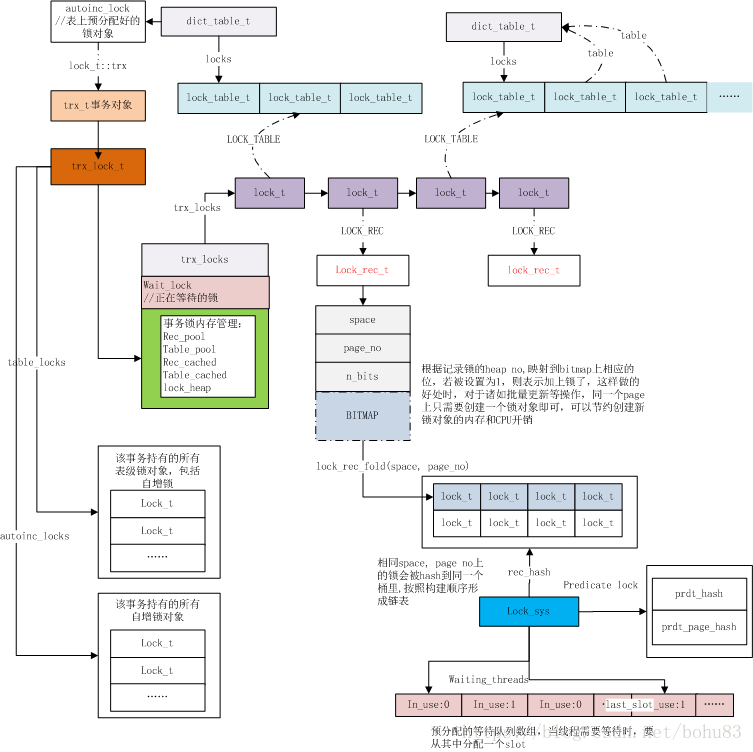
InnoDB 所有的事务锁对象都是挂在全局对象lock_sys上,同时每个事务对象上也维持了其拥有的事务锁,每个表对象(dict_table_t)上维持了构建在其上的表级锁对象。下图来自mysql.taobao.
二 表锁
表锁相关结构:
table->locks:数据字典table保存这个表上的所有表锁信息
trx->lock.table_locks:每个事务trx保存该事务所加的所有表锁信息
trx->lock.trx_locks:每个事务trx保存该事务所有的锁信息(包括行锁)
lock_table 加锁流程
- 首先从当前事务的
trx_lock_t::table_locks中查找是否已经加了等同或更高级别的表锁,如果已经加锁了,则直接返回成功(lock_table_has); - 检查当前是否有和正在申请的锁模式冲突的表级锁对象(
lock_table_other_has_incompatible); - 如果存在冲突的锁对象,则需要进入等待队列(
lock_table_enqueue_waiting)- 创建等待锁对象 (
lock_table_create) - 检查是否存在死锁(
DeadlockChecker::check_and_resolve),当存在死锁时:如果当前会话被选作牺牲者,就移除锁请求(lock_table_remove_low),重置当前事务的wait_lock为空,并返回错误码DB_DEADLOCK;若被选成胜利者,则锁等待解除,可以认为当前会话已经获得了锁,返回成功; - 若没有发生死锁,设置事务对象的相关变量后,返回错误码DB_LOCK_WAIT,随后进入锁等待状态
- 创建等待锁对象 (
- 如果不存在冲突的锁,则直接创建锁对象(
lock_table_create),加入队列。
lock_table_create: 创建锁对象 源码在innobase/lock/lock0lock.cc
/*********************************************************************//**
Creates a table lock object and adds it as the last in the lock queue
of the table. Does NOT check for deadlocks or lock compatibility.
@return own: new lock object */
UNIV_INLINE
lock_t*
lock_table_create(
/*==============*/
dict_table_t* table, /*!< in/out: database table
in dictionary cache */
ulint type_mode,/*!< in: lock mode possibly ORed with
LOCK_WAIT */
trx_t* trx) /*!< in: trx */
{
lock_t* lock;
ut_ad(table && trx);
ut_ad(lock_mutex_own());
ut_ad(trx_mutex_own(trx));
check_trx_state(trx);
if ((type_mode & LOCK_MODE_MASK) == LOCK_AUTO_INC) {
++table->n_waiting_or_granted_auto_inc_locks;
}
/* For AUTOINC locking we reuse the lock instance only if
there is no wait involved else we allocate the waiting lock
from the transaction lock heap. */
if (type_mode == LOCK_AUTO_INC) {
lock = table->autoinc_lock;
table->autoinc_trx = trx;
ib_vector_push(trx->autoinc_locks, &lock);
} else if (trx->lock.table_cached < trx->lock.table_pool.size()) {
lock = trx->lock.table_pool[trx->lock.table_cached++];
} else {
lock = static_cast<lock_t*>(
mem_heap_alloc(trx->lock.lock_heap, sizeof(*lock)));
}
lock->type_mode = ib_uint32_t(type_mode | LOCK_TABLE);
lock->trx = trx;
lock->un_member.tab_lock.table = table;
ut_ad(table->n_ref_count > 0 || !table->can_be_evicted);
UT_LIST_ADD_LAST(trx->lock.trx_locks, lock);
ut_list_append(table->locks, lock, TableLockGetNode());
if (type_mode & LOCK_WAIT) {
lock_set_lock_and_trx_wait(lock, trx);
}
lock->trx->lock.table_locks.push_back(lock);
MONITOR_INC(MONITOR_TABLELOCK_CREATED);
MONITOR_INC(MONITOR_NUM_TABLELOCK);
return(lock);
}- 当前请求的是AUTO-INC锁时;
- 递增
dict_table_t::n_waiting_or_granted_auto_inc_locks。前面我们已经提到过,当这个值非0时,对于自增列的插入操作就会退化到OLD-STYLE; - 锁对象直接引用已经预先创建好的
dict_table_t::autoinc_lock,并加入到trx_t::autoinc_locks集合中;
- 递增
- 对于非AUTO-INC锁,则从一个pool中分配锁对象
- 在事务对象
trx_t::lock中,维持了两个pool,一个是trx_lock_t::rec_pool,预分配了一组锁对象用于记录锁分配,另外一个是trx_lock_t::table_pool,用于表级锁的锁对象分配。通过预分配内存的方式,可以避免在持有全局大锁时(lock_sys->mutex)进行昂贵的内存分配操作。rec_pool和table_pool预分配的大小都为8个锁对象。(lock_trx_alloc_locks); - 如果table_pool已经用满,则走内存分配,创建一个锁对象;
- 在事务对象
- 构建好的锁对象分别加入到事务的
trx_t::lock.trx_locks链表上以及表对象的dict_table_t::locks链表上; - 构建好的锁对象加入到当前事务的
trx_t::lock.table_locks集合中。
可以看到锁对象会加入到不同的集合或者链表中,通过挂载到事务对象上,可以快速检查当前事务是否已经持有表锁;通过挂到表对象的锁链表上,可以用于检查该表上的全局冲突情况。
三 行锁
记录锁的存储单位为页,一个事务在一个页上的所有同类型锁存储为一个lock,lock中通过bitmap来表示那些记录已加锁
行锁类型:行锁类型由基本类型和精确类型组成
行锁基本类型:
LOCK_S,LOCK_X
行锁精确类型:
LOCK_ORDINARY(NK):next-key lock 既锁记录也锁记录前的gap
LOCK_GAP(GAP):不锁记录,只锁记录前的gap
LOCK_REC_NOT_GAP(NG):只锁记录,不锁记录前的gap
LOCK_INSERT_INTENTION(I):insert时,若insert位置已有gap锁,则需加LOCK_INSERT_INTENTION锁
相关结构:
trx->lock.trx_locks:每个事务trx保存该事务所有的锁信息(表锁和行锁)
lock_sys->rec_hash:保存所有事务的行锁信息
给记录加S锁之前必会给表加IS锁
给记录加X锁之前必会给表加IX锁
行加锁流程
函数入口: lock_rec_lock 源码在innobase/lock/lock0lock.cc
/*********************************************************************//**
Tries to lock the specified record in the mode requested. If not immediately
possible, enqueues a waiting lock request. This is a low-level function
which does NOT look at implicit locks! Checks lock compatibility within
explicit locks. This function sets a normal next-key lock, or in the case
of a page supremum record, a gap type lock.
@return DB_SUCCESS, DB_SUCCESS_LOCKED_REC, DB_LOCK_WAIT, DB_DEADLOCK,
or DB_QUE_THR_SUSPENDED */
static
dberr_t
lock_rec_lock(
/*==========*/
bool impl, /*!< in: if true, no lock is set
if no wait is necessary: we
assume that the caller will
set an implicit lock */
ulint mode, /*!< in: lock mode: LOCK_X or
LOCK_S possibly ORed to either
LOCK_GAP or LOCK_REC_NOT_GAP */
const buf_block_t* block, /*!< in: buffer block containing
the record */
ulint heap_no,/*!< in: heap number of record */
dict_index_t* index, /*!< in: index of record */
que_thr_t* thr) /*!< in: query thread */
{
ut_ad(lock_mutex_own());
ut_ad(!srv_read_only_mode);
ut_ad((LOCK_MODE_MASK & mode) != LOCK_S
|| lock_table_has(thr_get_trx(thr), index->table, LOCK_IS));
ut_ad((LOCK_MODE_MASK & mode) != LOCK_X
|| lock_table_has(thr_get_trx(thr), index->table, LOCK_IX));
ut_ad((LOCK_MODE_MASK & mode) == LOCK_S
|| (LOCK_MODE_MASK & mode) == LOCK_X);
ut_ad(mode - (LOCK_MODE_MASK & mode) == LOCK_GAP
|| mode - (LOCK_MODE_MASK & mode) == LOCK_REC_NOT_GAP
|| mode - (LOCK_MODE_MASK & mode) == 0);
ut_ad(dict_index_is_clust(index) || !dict_index_is_online_ddl(index));
/* We try a simplified and faster subroutine for the most
common cases */
switch (lock_rec_lock_fast(impl, mode, block, heap_no, index, thr)) {
case LOCK_REC_SUCCESS:
return(DB_SUCCESS);
case LOCK_REC_SUCCESS_CREATED:
return(DB_SUCCESS_LOCKED_REC);
case LOCK_REC_FAIL:
return(lock_rec_lock_slow(impl, mode, block,
heap_no, index, thr));
}
ut_error;
return(DB_ERROR);
}/*********************************************************************//**
This is a fast routine for locking a record in the most common cases:
there are no explicit locks on the page, or there is just one lock, owned
by this transaction, and of the right type_mode. This is a low-level function
which does NOT look at implicit locks! Checks lock compatibility within
explicit locks. This function sets a normal next-key lock, or in the case of
a page supremum record, a gap type lock.
@return whether the locking succeeded */
UNIV_INLINE
lock_rec_req_status
lock_rec_lock_fast(
/*===============*/
bool impl, /*!< in: if TRUE, no lock is set
if no wait is necessary: we
assume that the caller will
set an implicit lock */
ulint mode, /*!< in: lock mode: LOCK_X or
LOCK_S possibly ORed to either
LOCK_GAP or LOCK_REC_NOT_GAP */
const buf_block_t* block, /*!< in: buffer block containing
the record */
ulint heap_no,/*!< in: heap number of record */
dict_index_t* index, /*!< in: index of record */
que_thr_t* thr) /*!< in: query thread */
{
ut_ad(lock_mutex_own());
ut_ad(!srv_read_only_mode);
ut_ad((LOCK_MODE_MASK & mode) != LOCK_S
|| lock_table_has(thr_get_trx(thr), index->table, LOCK_IS));
ut_ad((LOCK_MODE_MASK & mode) != LOCK_X
|| lock_table_has(thr_get_trx(thr), index->table, LOCK_IX)
|| srv_read_only_mode);
ut_ad((LOCK_MODE_MASK & mode) == LOCK_S
|| (LOCK_MODE_MASK & mode) == LOCK_X);
ut_ad(mode - (LOCK_MODE_MASK & mode) == LOCK_GAP
|| mode - (LOCK_MODE_MASK & mode) == 0
|| mode - (LOCK_MODE_MASK & mode) == LOCK_REC_NOT_GAP);
ut_ad(dict_index_is_clust(index) || !dict_index_is_online_ddl(index));
DBUG_EXECUTE_IF("innodb_report_deadlock", return(LOCK_REC_FAIL););
lock_t* lock = lock_rec_get_first_on_page(lock_sys->rec_hash, block);
trx_t* trx = thr_get_trx(thr);
lock_rec_req_status status = LOCK_REC_SUCCESS;
if (lock == NULL) {
if (!impl) {
RecLock rec_lock(index, block, heap_no, mode);
/* Note that we don't own the trx mutex. */
rec_lock.create(trx, false, true);
}
status = LOCK_REC_SUCCESS_CREATED;
} else {
trx_mutex_enter(trx);
if (lock_rec_get_next_on_page(lock)
|| lock->trx != trx
|| lock->type_mode != (mode | LOCK_REC)
|| lock_rec_get_n_bits(lock) <= heap_no) {
status = LOCK_REC_FAIL;
} else if (!impl) {
/* If the nth bit of the record lock is already set
then we do not set a new lock bit, otherwise we do
set */
if (!lock_rec_get_nth_bit(lock, heap_no)) {
lock_rec_set_nth_bit(lock, heap_no);
status = LOCK_REC_SUCCESS_CREATED;
}
}
trx_mutex_exit(trx);
}
return(status);
}/*********************************************************************//**
This is the general, and slower, routine for locking a record. This is a
low-level function which does NOT look at implicit locks! Checks lock
compatibility within explicit locks. This function sets a normal next-key
lock, or in the case of a page supremum record, a gap type lock.
@return DB_SUCCESS, DB_SUCCESS_LOCKED_REC, DB_LOCK_WAIT, DB_DEADLOCK,
or DB_QUE_THR_SUSPENDED */
static
dberr_t
lock_rec_lock_slow(
/*===============*/
ibool impl, /*!< in: if TRUE, no lock is set
if no wait is necessary: we
assume that the caller will
set an implicit lock */
ulint mode, /*!< in: lock mode: LOCK_X or
LOCK_S possibly ORed to either
LOCK_GAP or LOCK_REC_NOT_GAP */
const buf_block_t* block, /*!< in: buffer block containing
the record */
ulint heap_no,/*!< in: heap number of record */
dict_index_t* index, /*!< in: index of record */
que_thr_t* thr) /*!< in: query thread */
{
ut_ad(lock_mutex_own());
ut_ad(!srv_read_only_mode);
ut_ad((LOCK_MODE_MASK & mode) != LOCK_S
|| lock_table_has(thr_get_trx(thr), index->table, LOCK_IS));
ut_ad((LOCK_MODE_MASK & mode) != LOCK_X
|| lock_table_has(thr_get_trx(thr), index->table, LOCK_IX));
ut_ad((LOCK_MODE_MASK & mode) == LOCK_S
|| (LOCK_MODE_MASK & mode) == LOCK_X);
ut_ad(mode - (LOCK_MODE_MASK & mode) == LOCK_GAP
|| mode - (LOCK_MODE_MASK & mode) == 0
|| mode - (LOCK_MODE_MASK & mode) == LOCK_REC_NOT_GAP);
ut_ad(dict_index_is_clust(index) || !dict_index_is_online_ddl(index));
DBUG_EXECUTE_IF("innodb_report_deadlock", return(DB_DEADLOCK););
dberr_t err;
trx_t* trx = thr_get_trx(thr);
trx_mutex_enter(trx);
if (lock_rec_has_expl(mode, block, heap_no, trx)) {
/* The trx already has a strong enough lock on rec: do
nothing */
err = DB_SUCCESS;
} else {
const lock_t* wait_for = lock_rec_other_has_conflicting(
mode, block, heap_no, trx);
if (wait_for != NULL) {
/* If another transaction has a non-gap conflicting
request in the queue, as this transaction does not
have a lock strong enough already granted on the
record, we may have to wait. */
RecLock rec_lock(thr, index, block, heap_no, mode);
err = rec_lock.add_to_waitq(wait_for);
} else if (!impl) {
/* Set the requested lock on the record, note that
we already own the transaction mutex. */
lock_rec_add_to_queue(
LOCK_REC | mode, block, heap_no, index, trx,
true);
err = DB_SUCCESS_LOCKED_REC;
} else {
err = DB_SUCCESS;
}
}
trx_mutex_exit(trx);
return(err);
}
行级锁加锁的入口函数为lock_rec_lock,其中第一个参数impl如果为TRUE,则当当前记录上已有的锁和LOCK_X | LOCK_REC_NOT_GAP不冲突时,就无需创建锁对象。(见上文关于记录锁LOCK_X相关描述部分),为了描述清晰,下文的流程描述,默认impl为FALSE。
lock_rec_lock:
- 首先尝试fast lock的方式,对于冲突少的场景,这是比较普通的加锁方式(
lock_rec_lock_fast), 符合如下情况时,可以走fast lock:- 记录所在的page上没有任何记录锁时,直接创建锁对象,加入rec_hash,并返回成功;
- 记录所在的page上只存在一个记录锁,并且属于当前事务,且这个记录锁预分配的bitmap能够描述当前的heap no(预分配的bit数为创建锁对象时的page上记录数 + 64,参阅函数
RecLock::lock_size),则直接设置对应的bit位并返回;
- 无法走fast lock时,再调用slow lock的逻辑(
lock_rec_lock_slow)- 判断当前事务是否已经持有了一个优先级更高的锁,如果是的话,直接返回成功(
lock_rec_has_expl); - 检查是否存在和当前申请锁模式冲突的锁(
lock_rec_other_has_conflicting),如果存在的话,就创建一个锁对象(RecLock::RecLock),并加入到等待队列中(RecLock::add_to_waitq),这里会进行死锁检测; - 如果没有冲突的锁,则入队列(
lock_rec_add_to_queue):已经有在同一个Page上的锁对象且没有别的会话等待相同的heap no时,可以直接设置对应的bitmap(lock_rec_find_similar_on_page);否则需要创建一个新的锁对象;
- 判断当前事务是否已经持有了一个优先级更高的锁,如果是的话,直接返回成功(
- 返回错误码,对于DB_LOCK_WAIT, DB_DEADLOCK等错误码,会在上层进行处理。
四 死锁检测
/**
Check and resolve any deadlocks
@param[in, out] lock The lock being acquired
@return DB_LOCK_WAIT, DB_DEADLOCK, or DB_QUE_THR_SUSPENDED, or
DB_SUCCESS_LOCKED_REC; DB_SUCCESS_LOCKED_REC means that
there was a deadlock, but another transaction was chosen
as a victim, and we got the lock immediately: no need to
wait then */
dberr_t
RecLock::deadlock_check(lock_t* lock)
{
ut_ad(lock_mutex_own());
ut_ad(lock->trx == m_trx);
ut_ad(trx_mutex_own(m_trx));
const trx_t* victim_trx =
DeadlockChecker::check_and_resolve(lock, m_trx);
/* Check the outcome of the deadlock test. It is possible that
the transaction that blocked our lock was rolled back and we
were granted our lock. */
dberr_t err = check_deadlock_result(victim_trx, lock);
if (err == DB_LOCK_WAIT) {
set_wait_state(lock);
MONITOR_INC(MONITOR_LOCKREC_WAIT);
}
return(err);
}/** Checks if a joining lock request results in a deadlock. If a deadlock is
found this function will resolve the deadlock by choosing a victim transaction
and rolling it back. It will attempt to resolve all deadlocks. The returned
transaction id will be the joining transaction instance or NULL if some other
transaction was chosen as a victim and rolled back or no deadlock found.
@param[in] lock lock the transaction is requesting
@param[in,out] trx transaction requesting the lock
@return transaction instanace chosen as victim or 0 */
const trx_t*
DeadlockChecker::check_and_resolve(const lock_t* lock, trx_t* trx)
{
ut_ad(lock_mutex_own());
ut_ad(trx_mutex_own(trx));
check_trx_state(trx);
ut_ad(!srv_read_only_mode);
/* If transaction is marked for ASYNC rollback then we should
not allow it to wait for another lock causing possible deadlock.
We return current transaction as deadlock victim here. */
if (trx->in_innodb & TRX_FORCE_ROLLBACK_ASYNC) {
return(trx);
} else if (!innobase_deadlock_detect) {
return(NULL);
}
/* Release the mutex to obey the latching order.
This is safe, because DeadlockChecker::check_and_resolve()
is invoked when a lock wait is enqueued for the currently
running transaction. Because m_trx is a running transaction
(it is not currently suspended because of a lock wait),
its state can only be changed by this thread, which is
currently associated with the transaction. */
trx_mutex_exit(trx);
const trx_t* victim_trx;
/* Try and resolve as many deadlocks as possible. */
do {
DeadlockChecker checker(trx, lock, s_lock_mark_counter);
victim_trx = checker.search();
/* Search too deep, we rollback the joining transaction only
if it is possible to rollback. Otherwise we rollback the
transaction that is holding the lock that the joining
transaction wants. */
if (checker.is_too_deep()) {
ut_ad(trx == checker.m_start);
ut_ad(trx == victim_trx);
rollback_print(victim_trx, lock);
MONITOR_INC(MONITOR_DEADLOCK);
break;
} else if (victim_trx != NULL && victim_trx != trx) {
ut_ad(victim_trx == checker.m_wait_lock->trx);
checker.trx_rollback();
lock_deadlock_found = true;
MONITOR_INC(MONITOR_DEADLOCK);
}
} while (victim_trx != NULL && victim_trx != trx);
/* If the joining transaction was selected as the victim. */
if (victim_trx != NULL) {
print("*** WE ROLL BACK TRANSACTION (2)\n");
lock_deadlock_found = true;
}
trx_mutex_enter(trx);
return(victim_trx);
}当发现有冲突的锁时,调用函数RecLock::add_to_waitq进行判断。通常我们没有机会设置事务的优先级,在创建了一个处于WAIT状态的锁对象后,我们需要进行死锁检测,死锁检测采用深度优先遍历的方式,通过事务对象上的trx_t::lock.wait_lock构造事务的wait-for graph进行判断,当最终发现一个锁请求等待闭环时,可以判定发生了死锁。另外一种情况是,如果检测深度过长(即锁等待的会话形成的检测链路非常长),也会认为发生死锁,最大深度默认为LOCK_MAX_DEPTH_IN_DEADLOCK_CHECK,值为200。
当发生死锁时,需要选择一个牺牲者(DeadlockChecker::select_victim())来解决死锁,通常事务权重低的回滚(trx_weight_ge)。
- 修改了非事务表的会话具有更高的权重;
- 如果两个表都修改了、或者都没有修改事务表,那么就根据的事务的undo数量加上持有的事务锁个数来决定权值(TRX_WEIGHT);
- 低权重的事务被回滚,高权重的获得锁对象。
当无法立刻获得锁时,会将错误码传到上层进行处理(row_mysql_handle_errors)
释放锁及唤醒
大多数情况下事务锁都是在事务提交时释放,但有两种意外:
- AUTO-INC锁在SQL结束时直接释放(
innobase_commit --> lock_unlock_table_autoinc); - 在RC隔离级别下执行DML语句时,从引擎层返回到Server层的记录,如果不满足where条件,则需要立刻unlock掉(
ha_innobase::unlock_row)。
除这两种情况外,其他的事务锁都是在事务提交时释放的(lock_trx_release_locks --> lock_release)。事务持有的所有锁都维护在链表trx_t::lock.trx_locks上,依次遍历释放即可。
对于行锁,从全局hash中删除后,还需要判断别的正在等待的会话是否可以被唤醒(lock_rec_dequeue_from_page)。例如如果当前释放的是某个记录的X锁,那么所有的S锁请求的会话都可以被唤醒。
对于表锁,如果表级锁的类型不为LOCK_IS,且当前事务修改了数据,就将表对象的dict_table_t::query_cache_inv_id设置为当前最大的事务id。在检查是否可以使用该表的Query Cache时会使用该值进行判断(row_search_check_if_query_cache_permitted),如果某个用户会话的事务对象的low_limit_id(即最大可见事务id)比这个值还小,说明它不应该使用当前table cache的内容,也不应该存储到query cache中。
表级锁对象的释放调用函数lock_table_dequeue。
/*************************************************************//**
Removes a table lock request, waiting or granted, from the queue and grants
locks to other transactions in the queue, if they now are entitled to a
lock. */
static
void
lock_table_dequeue(
/*===============*/
lock_t* in_lock)/*!< in/out: table lock object; transactions waiting
behind will get their lock requests granted, if
they are now qualified to it */
{
ut_ad(lock_mutex_own());
ut_a(lock_get_type_low(in_lock) == LOCK_TABLE);
lock_t* lock = UT_LIST_GET_NEXT(un_member.tab_lock.locks, in_lock);
lock_table_remove_low(in_lock);
/* Check if waiting locks in the queue can now be granted: grant
locks if there are no conflicting locks ahead. */
for (/* No op */;
lock != NULL;
lock = UT_LIST_GET_NEXT(un_member.tab_lock.locks, lock)) {
if (lock_get_wait(lock)
&& !lock_table_has_to_wait_in_queue(lock)) {
/* Grant the lock */
ut_ad(in_lock->trx != lock->trx);
lock_grant(lock);
}
}
}注意在释放锁时,如果该事务持有的锁对象太多,每释放1000(LOCK_RELEASE_INTERVAL)个锁对象,会暂时释放下lock_sys->mutex再重新持有,防止InnoDB hang住。
if (count == LOCK_RELEASE_INTERVAL) {
/* Release the mutex for a while, so that we
do not monopolize it */
lock_mutex_exit();
lock_mutex_enter();
count = 0;
}
...下一篇结合例子来看常见的死锁。
参考: