题目
https://www.kaggle.com/c/digit-recognizer
前言
上一篇写了一些基础的代码,用一个最简单的神经元来写了一个手写数字的识别。在这一篇里,首先扩展了神经网络的深度,并且处理了深度所带来的权重初始化的问题,另外,还尝试用了batch normalization算法进行了优化。
增加网络层数
把网络层数加深并不难,只要处理好输入输出就可以了,这里直接贴个代码好了。这里有两个隐藏层,算是比较少的了,也可以根据情况修改layers,就可以增加层数了。
#self.learning_rate = 0.02 self.batch_size = 50
def hide_layer(self, x, layer_name, var_shape):
n_input = np.prod(var_shape[:-1])
w_initializer = tf.truncated_normal_initializer(mean=0,stddev=1,dtype=tf.float32)
b_initializer = tf.constant_initializer(0.1, dtype=tf.float32)
W = tf.get_variable(layer_name + '_w', var_shape, initializer=w_initializer,dtype=tf.float32, trainable=True)
b = tf.get_variable(layer_name + '_b', [var_shape[-1]],initializer=b_initializer,dtype=tf.float32, trainable=True)
out = tf.matmul(x,W) + b
return tf.nn.elu(out)
def build_model(self):
print 'build_model'
self.x = tf.placeholder(tf.float32,[None, 784])
layer_output = self.x
layers = [784,30,10]
n = len(layers) - 1
for i in range(n):
var_shape = [layers[i], layers[i + 1]]
layer_output = self.hide_layer(layer_output, 'layer_' + str(i), var_shape)
self.y = tf.nn.softmax(layer_output)
self.label = tf.placeholder(tf.float32,[None,10])
self.cross_entropy = -tf.reduce_sum(self.label*tf.log(self.y))
opt = tf.train.GradientDescentOptimizer(learning_rate=self.learning_rate)
self.train_step = opt.minimize(self.cross_entropy)
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
self.sess = tf.Session(config=config)
init = tf.global_variables_initializer()
self.sess.run(init)
self.saver = tf.train.Saver(tf.global_variables())ok,到这里还好,当你把代码跑起来,可能会发现,loss为nan的情况更容易出现了,尤其是多加两层隐藏层会更加明显,训练很难进行下去。遇到这种情况,改小学习率是有效果的,但是过小的学习率无法让模型训练到一个合适的识别率。
权重初始化问题
为什么我们网络在层数较少的时候没问题,层数一增加,就发现loss为0了呢?说到底,还是参数初始化有问题,当我们增加层数的时候,因为参数大部分比较小,那么就会出现越乘输出越小的现象,当输出为0或者无限接近于0的时候(计算机有精度限制),算出的梯度就会变成nan了。因此,我们需要合理地安排变量的初始值,使得开始的时候,神经网络计算的输出不为0。
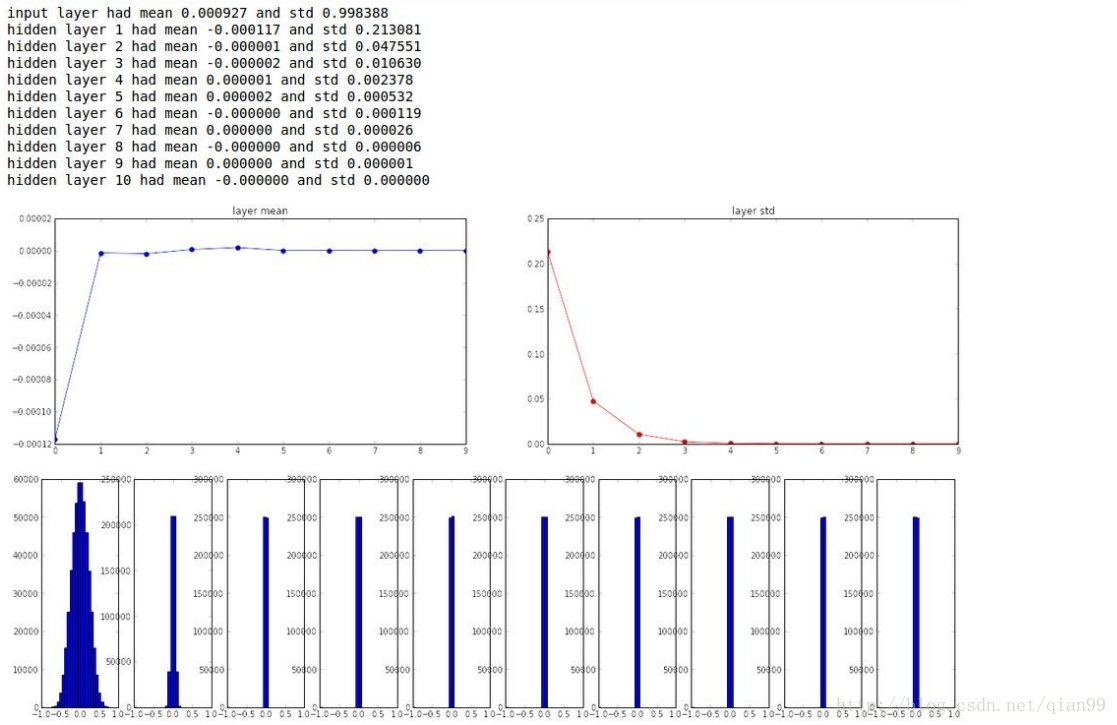
从下面这幅图可以看到,layer1的权重分布是一个标准的正态分布,但是从第3层开始,权重的就几乎都为0了。
怎样初始化可以避免最终的输出都变成这样呢?其实前辈们已经想好了解决方案,在使用sigmoid作为激活函数的时候,可以这样初始化权重:
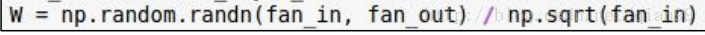
就是初始化的时候还是用一个正态分布,但是每个值都除一个该层网络的输入的size的平方根,具体为什么我也不知道,反正是公式推导的。改完以后就变成了这样:

但是呢,这对于用relu作为激活函数的网络来说,效果不是那么好,后来又有人推了公式,表示如果用relu作为激活函数,要除输入size/2的平方根:
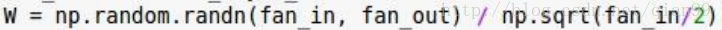
ok,这很好改,我们只需要改一行代码就可以解决这个问题了:
W = tf.get_variable(layer_name + '_w', var_shape, initializer=w_initializer,dtype=tf.float32, trainable=True)/np.sqrt(n_input/2)简单调参与发现的问题
在加上上面的代码以后,我调了一些参数,来看训练效果。不过我就记了两组,也懒得再重新调了,我大概说一下调出来的问题,首先我列一下这两组测试的参数:
第一组:
layers = [784, 1024,2048,512, 10]
act:elu
batch_size:128
epoch:15
learning_rate: 0.01
train_acc is: 0.921534, test_acc is 0.920000
第二组:
layers = [784,30,10]
act:elu
batch_size:30
epoch:10
learning_rate: 0.2
train_acc is: 0.958571, test_acc is 0.947857
最开始呢,我认为肯定层数越多越好,参数越多越好,batch_size越大越好啊,所以开始的时候,这些数值都设得比较高,最终的结果也可以看到,效果并不是非常好。这是为什么呢?我后来总结了一下,在我看来,有以下几点原因:
1. 层数的增加,导致梯度传递更加困难,容易出现梯度弥散问题,也就是梯度从后往前传的时候,越来越小,甚至为0,导致浅层网络训练不充分。
2. batch size虽然变大了,但是由于每组batch的数据的分布比较随机,比如第一个batch中的6比较多,可能会把权重的分布往这个方向拉,等下一个batch中3又比较多,可能又把更新的梯度拉回来。
3. 跟上面的问题有些相似,同一个batch中更新的时候也会出现梯度方向的竞争
4. 学习率与batch设置的不合理,这里batch的选择其实会影响学习率的范围,因为学习率过大会导致loss变为nan(即使使用了正确的权重初始化方法)。具体原因我还没太想好,这是我观察到的现象。学习率的不合理就会导致可能无法将模型训练充分。
那后面我就采用了一个层数较少的网络和较小的batch_size和较大的学习率,效果还是不错的,最终的正确率有0.94857
使用batch normalization算法
batch normalization算法(简称bn算法),是2015年才提出来的一个算法,而且效果非常好。bn算法的优点有很多:
1. 可以使用更高的学习率
2. 可以减少甚至移除神经网络中使用的正则化操作
3. 训练的效率比不用bn高很多,也就是梯度下降的比较快
4. 减少了对初始化权重的依赖,不容易出现开始训练的时候一不小心loss变成nan这种情况。
bn算法这么厉害,是不是迫不及待想知道是怎么做的了?可以看下面的图:

第一步,就是把每个x值减去均值再除一个标准差。
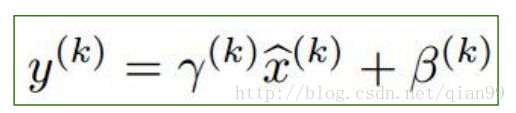
第二步,这里增加了两个需要训练的参数,最开始分别是1和0,如果这两个值训练到对应的均值和标准差时,那么x的值就相当于不变了。
那么对于第一步来说,这一步会改变输入的分布,使得输入的分布在激活函数的位置的梯度更大(可以参考一下各个激活函数的图像),另外呢,由于第一步让x的分布变了,数据的表达能力也变弱了,所以后面要进行一定的调整。在我看来这两个参数最后应该训练到的就是整体数据的分布的均值和标准差,所以到最后是对最终结果影响不大的。
其实这个操作并不复杂,不过个中原理我认识的还不是很深刻,如果想要了解更多可以搜索相关的文章(笑)。
最后来贴一下代码,其实也不难,tensorflow有相关的api,用起来就好了,不过需要注意的是,训练的时候我们需要求输入的分布和方差,用来训练参数,但是到了测试的时候,就不需要了,直接用训练好的参数,所以这里要分为两种情况。其他的变化不大:
def hide_layer(self, x, layer_name, var_shape, is_train=True, decay=0.999):
n_input = np.prod(var_shape[:-1])
w_initializer = tf.truncated_normal_initializer(mean=0,stddev=1,dtype=tf.float32)
b_initializer = tf.constant_initializer(0.1, dtype=tf.float32)
W = tf.get_variable(layer_name + '_w', var_shape, initializer=w_initializer,dtype=tf.float32, trainable=True)/np.sqrt(n_input/2)
b = tf.get_variable(layer_name + '_b', [var_shape[-1]],initializer=b_initializer,dtype=tf.float32, trainable=True)
out = tf.matmul(x,W) + b
if self.use_bn:
zero_initializer = tf.constant_initializer(0.0, dtype=tf.float32)
one_initializer = tf.constant_initializer(1.0, dtype=tf.float32)
scale = tf.get_variable(layer_name + '_scale', var_shape[-1], initializer=one_initializer,dtype=tf.float32, trainable=True)
beta = tf.get_variable(layer_name + '_beta', var_shape[-1], initializer=zero_initializer,dtype=tf.float32, trainable=True)
ema_mean = tf.get_variable(layer_name + '_emamean', var_shape[-1],initializer=zero_initializer,dtype=tf.float32, trainable=False)
ema_var = tf.get_variable(layer_name + '_emavar', var_shape[-1],initializer=one_initializer,dtype=tf.float32, trainable=False)
if is_train:
batch_mean, batch_var = tf.nn.moments(out,[0])
self.train_mean = tf.assign(ema_mean, ema_mean * decay + batch_mean * (1 - decay))
self.train_var = tf.assign(ema_var, ema_var * decay + batch_var * (1 - decay))
with tf.control_dependencies([self.train_mean, self.train_var]):
out = tf.nn.batch_normalization(out, self.train_mean, self.train_var, beta, scale, variance_epsilon=0.00001)
else:
out = tf.nn.batch_normalization(out, ema_mean, ema_var,beta, scale, variance_epsilon=0.00001)
return tf.nn.elu(out)结论
最后,我训了个模型,参数大概是这样的:
layers = [784,256,64,10]
act:elu
batch_size:50
epoch:20
learning_rate: 0.02
use_bn: True
train_acc is: 0.972566, test_acc is 0.956190
训练的轮数(epoch)可以再加10轮,但是这个结果我忘记下来了,大概会更高一点。最终交到kaggle上的准确率有0.96642,我觉得不用卷积神经网络的情况下,这个成绩还是不错的。后面我会再搞一搞更新时的优化,看看能不能搞出什么东西,如果没啥用后面再用卷积神经网络搞一下。
完整代码
import os
import numpy as np
import tensorflow as tf
import random
# layers = [784, 1024,2048,512, 10] act:elu batch_size:128 epoch:15 learning_rate: 0.01 train_acc is: 0.921534, test_acc is 0.920000
# layers = [784,30,10] act:elu batch_size:30 epoch:10 learning_rate: 0.2 train_acc is: 0.958571, test_acc is 0.947857
# layers = [784,256,64,10] act:elu batch_size:50 epoch:20 learning_rate: 0.02 use_bn: True train_acc is: 0.972566, test_acc is 0.956190
class SimpleModel(object):
def __init__(self):
self.learning_rate = 0.02
self.batch_size = 50
self.epoch = 20
self.use_bn = True
def hide_layer(self, x, layer_name, var_shape, is_train=True, decay=0.999):
n_input = np.prod(var_shape[:-1])
w_initializer = tf.truncated_normal_initializer(mean=0,stddev=1,dtype=tf.float32)
b_initializer = tf.constant_initializer(0.1, dtype=tf.float32)
W = tf.get_variable(layer_name + '_w', var_shape, initializer=w_initializer,dtype=tf.float32, trainable=True)/np.sqrt(n_input/2)
b = tf.get_variable(layer_name + '_b', [var_shape[-1]],initializer=b_initializer,dtype=tf.float32, trainable=True)
out = tf.matmul(x,W) + b
if self.use_bn:
zero_initializer = tf.constant_initializer(0.0, dtype=tf.float32)
one_initializer = tf.constant_initializer(1.0, dtype=tf.float32)
scale = tf.get_variable(layer_name + '_scale', var_shape[-1], initializer=one_initializer,dtype=tf.float32, trainable=True)
beta = tf.get_variable(layer_name + '_beta', var_shape[-1], initializer=zero_initializer,dtype=tf.float32, trainable=True)
ema_mean = tf.get_variable(layer_name + '_emamean', var_shape[-1],initializer=zero_initializer,dtype=tf.float32, trainable=False)
ema_var = tf.get_variable(layer_name + '_emavar', var_shape[-1],initializer=one_initializer,dtype=tf.float32, trainable=False)
if is_train:
batch_mean, batch_var = tf.nn.moments(out,[0])
self.train_mean = tf.assign(ema_mean, ema_mean * decay + batch_mean * (1 - decay))
self.train_var = tf.assign(ema_var, ema_var * decay + batch_var * (1 - decay))
with tf.control_dependencies([self.train_mean, self.train_var]):
out = tf.nn.batch_normalization(out, self.train_mean, self.train_var, beta, scale, variance_epsilon=0.00001)
else:
out = tf.nn.batch_normalization(out, ema_mean, ema_var,beta, scale, variance_epsilon=0.00001)
return tf.nn.elu(out)
def build_model(self, is_train=True):
print 'build_model'
self.x = tf.placeholder(tf.float32,[None, 784])
layer_output = self.x
layers = [784,30,10]
layers = [784,256,64,10]
n = len(layers) - 1
for i in range(n):
var_shape = [layers[i], layers[i + 1]]
layer_output = self.hide_layer(layer_output, 'layer_' + str(i), var_shape, is_train)
# layer_output = tf.nn.elu(tf.matmul(layer_output,W) + b)
self.y = tf.nn.softmax(layer_output)
self.label = tf.placeholder(tf.float32,[None,10])
self.cross_entropy = -tf.reduce_sum(self.label*tf.log(self.y))
opt = tf.train.GradientDescentOptimizer(learning_rate=self.learning_rate)
self.train_step = opt.minimize(self.cross_entropy)
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
self.sess = tf.Session(config=config)
init = tf.global_variables_initializer()
self.sess.run(init)
self.saver = tf.train.Saver(tf.global_variables())
def randomBatch(self,size, epoch):
self.data_tags = []
for i in range(epoch):
for j in range(size):
self.data_tags.append(j)
random.shuffle(self.data_tags)
self.data_pos = 0
def getNextBatch(self, x_inputs, y_labels):
batch_x = []
batch_y = []
m = len(self.data_tags)
for i in range(self.batch_size):
p = self.data_tags[self.data_pos]
self.data_pos = (self.data_pos + 1)%m
batch_x.append(x_inputs[p])
batch_y.append(y_labels[p])
return np.array(batch_x),np.array(batch_y)
def train(self,x_inputs, y_labels):
pos = 0
count = 0
total = int(len(x_inputs)/self.batch_size)
self.randomBatch(len(x_inputs),self.epoch)
for i in range(self.epoch*total):
x_batch,y_batch = self.getNextBatch(x_inputs,y_labels)
y, loss,_ = self.sess.run([self.y, self.cross_entropy,self.train_step],feed_dict={self.x:x_batch,self.label:y_batch})
# print 'y:' + str(y)
# print 'loss :' + str(loss)
count += 1
if count % 50 == 0:
print 'step %d: ,loss:%.6f' % (count, loss)
self.saver.save(self.sess, './train_models/simple2.model.ckpt',global_step=0)
print 'train over'
def init_model(self,modelName):
self.build_model(False)
self.saver.restore(self.sess, os.path.join('./train_models/',modelName) )
def test(self, x):
predict = self.sess.run(self.y, feed_dict={self.x:x})
#predict = np.array(predict).astype(float)
res = np.argmax(predict, axis=1)
# print res
return res
#return np.argmax(predict, axis=1)