最基础的HTTP 库有urllib 、httplib2 、requests 、treq 等。
使用urllib
urllib 库,它是Python 内置的HTTP 请求库,也就是说不需要额外安装即可使用。它包含如下4 个模块。
request : 它是最基本的HTTP 请求模块,可以用来模拟发送请求。就像在浏览器里输入网挝然后回车一样,只需要给库方法传入URL 以及额外的参数,就可以模拟实现这个过程了。
error : 异常处理模块,如果出现请求错误, 我们可以捕获这些异常,然后进行重试或其他操作以保证程序不会意外终止。
parse : 一个工具模块,提供了许多URL 处理方法,比如拆分、解析、合并等。
robotparser :主要是用来识别网站的robots.txt 文件,然后判断哪些网站可以爬,哪些网站不可以爬,它其实用得比较少。
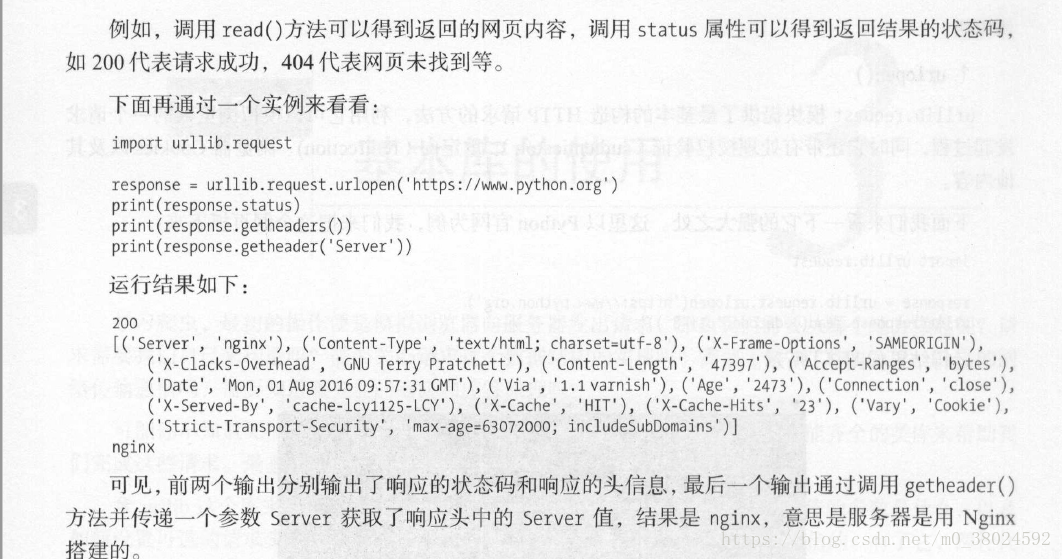
import urllib.request
response = urllib.request.urlopen("https://www.baidu.com")
print(response.read().decode("utf-8"))


解析链接
urllib 库里还提供了parse 模块,它定义了处理URL 的标准接口,例如实现URL 各部分的抽取、合并以及链接转换。它支持如下协议的URL 处理:file 、ftp 、gopher 、hdl 、http、https 、imap 、mailto 、mms 、news 、nntp 、prospero 、rsync 、rtsp 、rtspu 、sftp 、sip 、sips 、snews 、svn 、svn+ssh 、telnet
和wais 。
1. urlparse() -- 实现URL 的识别和分段
import urllib
result = urllib.parse.urlparse('https://study.163.com/course/courseLearn.htm?courseId=252008#/learn/video?lessonId=361356&courseId=252008')
print(type(result), result, sep='\n')
# <class 'urllib.parse.ParseResult'>
# ParseResult(scheme='https', netloc='www.baidu.com', path='/index.html', params='user', query='id=5', fragment='comment')可以看到,返回结果是一个ParseResult 类型的对象,它包含6 个部分,分别是scheme、netloc、path、params、query 和fragment 。
可以发现, urlparse() 方法将其拆分成了6 个部分。大体观察可以发现,解析时有特定的分隔符。比如,://前面的就是scheme ,代表协议;第一个/符号前面便是netloc ,即域名,后面是path ,即访问路径;分号;前面是pa rams ,代表参数;问号?后面是查询条件query , 一般用作GET 类型的URL;井号#后面是锚点,用于直接定位页面内部的下拉位置。
所以,可以得出一个标准的链接格式,具体如下:
scheme://netloc/path;params?query#fragment








分析Robots协议