urllib基本库的使用
一、urllib基本使用
urllib库为内置库,无需额外安装,包含四个模块。官方文档
urlretrieve(url, filename=None, reporthook=None, data=None) 模拟发送请求,并快速的将一个网页保存下来
# 也可以怎样引用 import urllib.request
from urllib import request
url="https://www.ifeng.com"
request.urlretrieve(url=url,filename="凤凰网.html")对于GET的请求参数有中文需要先对中文进行url编码
from urllib import request,parse
# 转化为url编码
url="http://www.baidu.com/s?wd="+parse.quote("有道翻译")
request.urlretrieve(url=url,filename="百度搜索.html")urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT,*, cafile=None, capath=None, cadefault=False, context=None) 模拟发送请求。
from urllib import request
url="https://www.ifeng.com"
# 发送请求,timeout 设置超时
response=request.urlopen(url=url,timeout=0.5)
# 保存网页
with open("凤凰网.html","w",encoding="utf-8") as f:
f.write(response.read().decode("utf-8"))
# 响应后获取的数据类型
print(type(response))
# 响应状态码
print(response.status)
# 响应状态码
print(response.getcode())
# 获取当前信息
print("-"*80,"\n",response.info())
# 获取当前信息(list)
print("-"*80,"\n",response.getheaders())返回结果:
<class 'http.client.HTTPResponse'>
200
200
-----------------------------------------------------------------------------------------
Expires: Wed, 15 Aug 2018 00:05:08 GMT
Date: Wed, 15 Aug 2018 00:03:08 GMT
Server: nginx/1.10.3 (Ubuntu)
Content-Type: text/html
Transfer-Encoding: chunked
Cache-Control: max-age=120
Age: 90
X-Via: 1.1 chengwangtong25:10 (Cdn Cache Server V2.0), 1.1 PSsdtawt2xx179:2 (Cdn Cache Server V2.0)
Connection: close
Content-Security-Policy: upgrade-insecure-requests
-----------------------------------------------------------------------------------------
[('Expires', 'Wed, 15 Aug 2018 00:05:08 GMT'), ('Date', 'Wed, 15 Aug 2018 00:03:08 GMT'),
('Server', 'nginx/1.10.3 (Ubuntu)'), ('Content-Type', 'text/html'), ('Transfer-Encoding',
'chunked'), ('Cache-Control', 'max-age=120'), ('Age', '90'), ('X-Via', '1.1
chengwangtong25:10 (Cdn Cache Server V2.0), 1.1 PSsdtawt2xx179:2 (Cdn Cache Server V2.0)'),
('Connection', 'close'), ('Content-Security-Policy', 'upgrade-insecure-requests')]
request.Request(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)可以加入请求头等信息。以下为向有道云翻译发送请求:
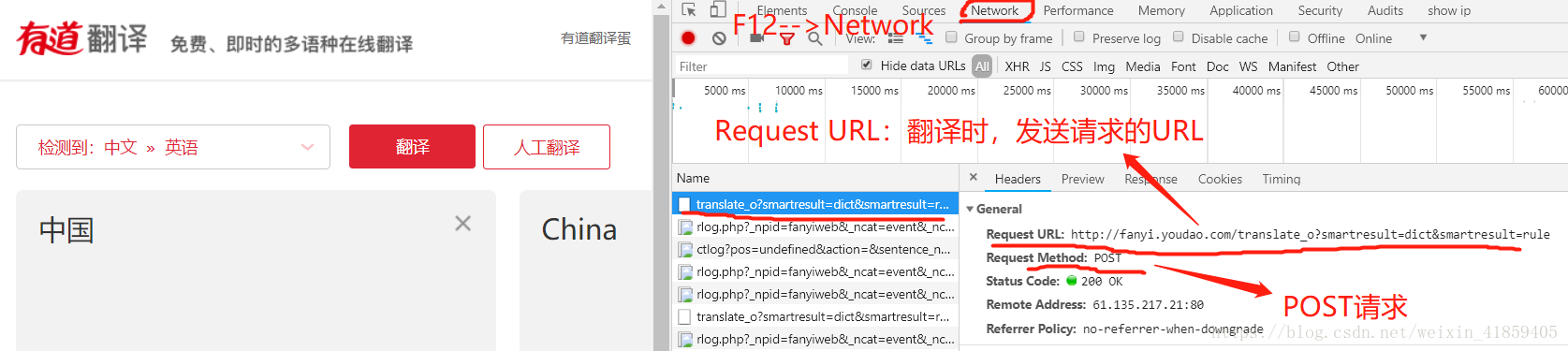
请求头:

请求数据:

代码:
from urllib import request,parse
import json
def fanyi(word):
# 转化为url编码
url = "http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
# 请求数据
data = {
"i": word,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": "1534292172502",
"sign": "20c74a80acc0f521169d2d0dba259737",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTIME",
"typoResult": "false"}
# 请求头
headers = {
"Cookie":"[email protected]; OUTFOX_SEARCH_USER_ID_NCOO=1986454282.0803714;\
SESSION_FROM_COOKIE=www.baidu.com; \
UM_distinctid=165387eb03b2eb-05823cf900a9d8-47e1039-144000-165387eb03c4e5; \
JSESSIONID=aaaYVjRJ0XqFrekDb86uw; fanyi-ad-id=48707; fanyi-ad-closed=1;\
___rl__test__cookies=1534292172494",
"Referer":"http://fanyi.youdao.com/",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
}
data = bytes(parse.urlencode(data), encoding="utf-8") # 转化为字节流
req = request.Request(url=url, data=data, headers=headers, method="POST")
response = request.urlopen(req)
return json.loads(response.read().decode("utf-8"))["translateResult"][0][0]["tgt"]
print(fanyi("中国")) # 结果:Chinaurllib模拟登陆方式一:先通过浏览器登陆,然后复制cookie进行请求
from urllib import request
# 保存网页
def wirteHtml(name,mode,data):
with open(name+".html",mode, encoding="utf-8") as f:
f.write(data)
# 请求头
headers={
"Cookie":"bid=fDJAnYMQ6hg; douban-fav-remind=1; ll=\"118235\"; \
__utmc=30149280; _ga=GA1.2.622816545.1534123840; push_noty_num=0; \
push_doumail_num=0; __utmv=30149280.18152; __yadk_uid=1DnjdDqVAAnUdD9nJLQdLj1MUtId89KS; \
ap=1; ct=y; ps=y; ue=\"[email protected]\"; _gid=GA1.2.9415980.1534544423; \
_pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1534632854%2C%22https%3A%2F%2\
Faccounts.douban.com%2Flogin%3Falias%3D1224662152%2540qq.com%26redir%3Dhttps%253A%252F%252F\
www.douban.com%252F%26source%3Dindex_nav%26error%3D1016%22%5D; _pk_ses.100001.8cb4=*; ap_v=1,6.0;\
__utma=30149280.622816545.1534123840.1534596972.1534632854.11; __utmz=30149280.1534632854.11.8.\
utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/login; __utmt=1; \
dbcl2=\"181527466:cEPNRlacF7E\"; ck=n9Vb; _pk_id.100001.8cb4=7e754246b1dbb5ee.\
1534123840.12.1534632943.1534598419.;\
__utmb=30149280.7.10.1534632854",
"Referer":"https://accounts.douban.com/login",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36//"
}
# 添加请求头需要用到request.Request然后在用request.urlopen
getRequest=request.Request("https://www.douban.com/",headers=headers,method="GET")
response=request.urlopen(getRequest)
wirteHtml("豆瓣主页","w",response.read().decode("utf-8"))