为什么引入线程
为了实现服务端并发处理客户端请求,我们介绍了多进程模型、select和epoll,这三种办法各有优缺点。创建(复制)进程的工作本身会给操作系统带来相当沉重的负担。而且,每个进程有独立的内存空间,所以进程间通信的实现难度也会随之提高。且进程的切换同样也是不菲的开销。什么是进程切换?我们都知道计算机即便只有一个CPU也可以同时运行多个进程,这是因为系统将CPU时间分成多个微小的块后分配给多个进程,比方进程B在进程A之后执行,当进程A所分配的CPU时间到点之后,要开始执行进程B,此时需要将进程A的数据移出内存保存到磁盘,并读入进程B的数据,所以上下文切换需要比较长的时间,即使通过优化加快速度,也会存在局限
为了保持多进程的优点,同时在一定程度上克服其缺点,人们引入了线程。这是为了将进程的各种劣势降至最低限度而设计的一种“轻量级进程”,线程相比进程有如下优点:
- 线程的创建和上下文切换比进程的创建和上下文切换更快
- 线程间交换数据时无需特殊技术
线程和进程的差异
每个进程的内存空间都由保存全局变量的“数据区”、向malloc等函数动态分配提供空间的堆(Heap)、函数运行时使用的栈(Stack)构成。每个进程都拥有这种独立的空间,多个进程结构如图1-1所示
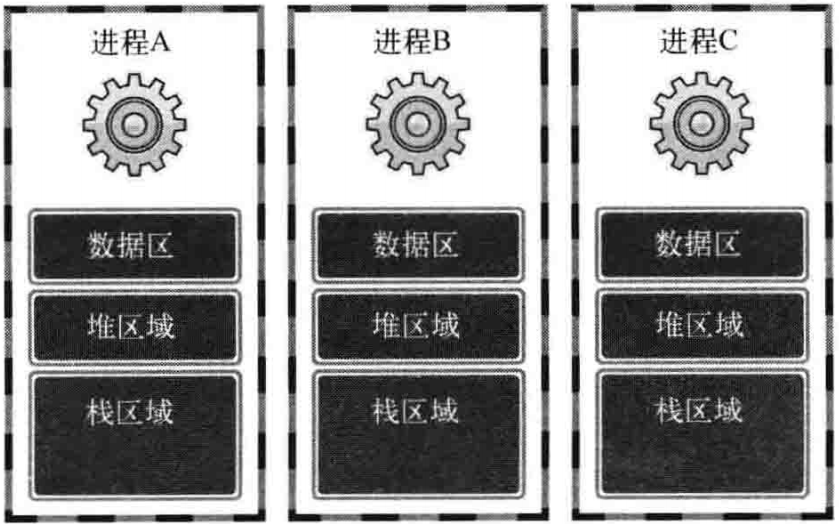
图1-1 进程间独立的内存
但如果以获得多个代码执行流为主要目的,则不应像图1-1那样完全分离内存结构,而只需分离栈区域,通过这种方式可以获得如下优势:
- 上下文切换时不需要切换数据区和堆
- 可以利用数据区和堆交换数据
实际上这就是线程,线程为了保持多条代码执行流而隔开了栈区域,因此具有如图1-2所示的内存结构

图1-2 线程的内存结构
如图1-2所示,多个线程将共享数据区和堆,为了保持这种结构,线程将在进程内创建并运行。也就是说,进程和线程可以定义为如下形式:
- 进程:在操作系统构成单独执行流的单位
- 线程:在进程构成单独执行流的单位
如果说进程在操作系统内部生成多个执行流,那么线程就在同一进程内部创建多条执行流。因此,操作系统、进程、线程之间的关系可以通过图1-3表示
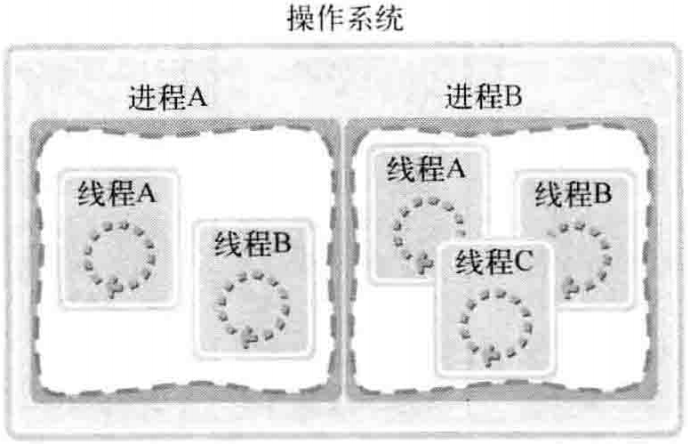
图1-3 操作系统、进程、线程之间的关系
线程的创建及运行
线程具有单独的执行流,因此需要单独定义线程的main函数,还需要请求操作系统在单独的执行流中执行该函数,完成该功能的函数如下:
#include<pthread.h> int pthread_create(pthread_t * restrict thread, const pthread_attr_t * restrict attr, void* (* start_routine)(void *), void * restrict arg);//成功时返回0,失败时返回其他值
- thread:保存新创建线程ID的变量地址值,线程与进程相同,也需要用于区分不同线程的ID
- attr:用于传递线程属性的参数,传递NULL时,创建默认属性的线程
- start_routine:相当于线程的main函数的、在单独执行流中执行的函数地址值(函数指针)
- arg:通过第三个参数传递调用函数时包含传递参数信息的变量地址值
下面,我们来看一个示例
thread1.c
#include <stdio.h>
#include <pthread.h>
void *thread_main(void *arg);
int main(int argc, char *argv[])
{
pthread_t t_id;
int thread_param = 5;
if (pthread_create(&t_id, NULL, thread_main, (void *)&thread_param) != 0)
{
puts("pthread_create() error");
return -1;
};
sleep(10); puts("end of main");
return 0;
}
void *thread_main(void *arg)
{
int i;
int cnt = *((int *)arg);
for (i = 0; i < cnt; i++)
{
sleep(1); puts("running thread");
}
return NULL;
}
- 第10行:请求创建一个线程,从thread_main函数调用开始,在单独的执行流中执行。同时在调用thread_main函数时向其传递thread_param变量的地址值
- 第15行:调用sleep函数使main函数停顿10秒,这是为了延迟进程的终止时间。执行第16行的return语句后终止进程,同时终止内部创建的线程。因此,为保证线程的正常执行而添加这条语句
- 第19、22行:传入arg参数的是第10行pthread_create函数的第四个参数
编译thread1.c并运行
# gcc thread1.c -o thread1 -lpthread # ./thread1 running thread running thread running thread running thread running thread end of main
从上述运行结果可以看到,线程相关代码在编译时需添加-lpthread选项声明需要连接线程库,只有这样才能调用头文件pthread.h中声明的函数,上述程序的执行流程如图1-4所示

图1-4 示例thread1.c的执行流程
图1-4中的虚线代表执行流程,向下的箭头指的是执行流,横向箭头是函数调用。
接下来,可以尝试将上述示例的第15行sleep函数的调用语句改为sleep(2)。运行之后大家会发现不会再像之前那样打印5次"running thread"字符串。因为main函数返回后整个进程将被销毁,如图1-5所示

图1-5 终止进程和线程
正因如此,我们之前的示例中通过调用sleep函数向线程提供了充足的时间
那么,如果我们希望等线程执行完毕,再结束程序,是不是一定要调用sleep函数?如果是,那么又牵扯出一个问题了,线程是在何时执行完毕呢?并非所有的程序都像thread1.c一样可预测线程的执行时间。那么,为了等待线程执行完毕,难道我们要用一个非常大的数作为sleep的参数吗?那这样就算线程可以执行完,程序依然在休眠,造成计算机资源的浪费是一定的。那么,针对这一困境,是否有解决方案呢?当然是有的,那就是pthread_join函数
#include <pthread.h> int pthread_join(pthread_t thread, void ** status);//成功时返回0,失败时返回其他值
- thread: thread所对应的线程终止后才会从pthread_join函数返回,换言之调用该函数后当前线程会一直阻塞到thread对应的线程执行完毕后才返回
- status:保存线程的main函数返回值的指针变量地址值
thread2.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <pthread.h>
void *thread_main(void *arg);
int main(int argc, char *argv[])
{
pthread_t t_id;
int thread_param = 5;
void *thr_ret;
if (pthread_create(&t_id, NULL, thread_main, (void *)&thread_param) != 0)
{
puts("pthread_create() error");
return -1;
};
if (pthread_join(t_id, &thr_ret) != 0)
{
puts("pthread_join() error");
return -1;
};
printf("Thread return message: %s \n", (char *)thr_ret);
free(thr_ret);
return 0;
}
void *thread_main(void *arg)
{
int i;
int cnt = *((int *)arg);
char *msg = (char *)malloc(sizeof(char) * 50);
strcpy(msg, "Hello, I'am thread~ \n");
for (i = 0; i < cnt; i++)
{
sleep(1); puts("running thread");
}
return (void *)msg;
}
- 第19行:main函数中,针对第13行创建的线程调用pthread_join函数,因此,main函数将等待ID保存在t_id变量中的线程终止
- 第11、19、41行:第41行返回的值将保存到第19行第二个参数thr_ret。需要注意的是,该返回值是thread_main函数内部动态分配的内存空间地址值
编译thread2.c并运行
# gcc thread2.c -o thread2 -lpthread # ./thread2 running thread running thread running thread running thread running thread Thread return message: Hello, I'am thread~
接下来我们来看thread2.c的执行流程图,如图1-6所示

图1-6 调用pthread_join函数
可在临界区内调用的函数
之前的示例只创建一个线程,接下来的示例将创建多个线程。当然,无论创建多少个线程,其创建方法没有区别。但关于线程的运行需要考虑“多个线程同时调用函数时(执行时)可能产生的问题”。这类函数内部存在临界区,也就是说,多个线程同时执行这部分代码时,可能引起问题。根据临界区是否引起问题,函数可分为两类:
- 线程安全函数
- 非线程安全函数
线程安全函数被多个线程同时调用不会发生问题,反之,非线程安全函数被调用时就会出现问题。
下面我们介绍一个示例,将计算1到10的和,但并不是在main函数中计算,而是创建两个线程,其中一个线程计算1到5的和,另一个线程计算6到10的和,main函数只负责输出结果。这种方式的编程模型称为“工作线程模型”。计算1到5之和与计算6到10之和的线程将成为main线程管理的工作。最后,在给出示例代码之前先给出程序执行流程图,如图1-7所示

图1-7 示例thread3.c的执行流程
thread3.c
#include <stdio.h>
#include <pthread.h>
void *thread_summation(void *arg);
int sum = 0;
int main(int argc, char *argv[])
{
pthread_t id_t1, id_t2;
int range1[] = {1, 5};
int range2[] = {6, 10};
pthread_create(&id_t1, NULL, thread_summation, (void *)range1);
pthread_create(&id_t2, NULL, thread_summation, (void *)range2);
pthread_join(id_t1, NULL);
pthread_join(id_t2, NULL);
printf("result: %d \n", sum);
return 0;
}
void *thread_summation(void *arg)
{
int start = ((int *)arg)[0];
int end = ((int *)arg)[1];
while (start <= end)
{
sum += start;
start++;
}
return NULL;
}
这里要注意一下,两个线程都访问全局变量sum
编译thread3.c 并运行
# gcc thread3.c -o thread3 -lpthread # ./thread3 result: 55
运行结果是55,虽然正确,但示例本身存在问题。此处存在临界区相关问题,因此再介绍另一示例,该示例与上述示例相似,只是增加了发生临界区相关错误的可能性
thread4.c
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <pthread.h>
#define NUM_THREAD 100
void *thread_inc(void *arg);
void *thread_des(void *arg);
long long num = 0;
int main(int argc, char *argv[])
{
pthread_t thread_id[NUM_THREAD];
int i;
printf("sizeof long long: %d \n", sizeof(long long));
for (i = 0; i < NUM_THREAD; i++)
{
if (i % 2)
pthread_create(&(thread_id[i]), NULL, thread_inc, NULL);
else
pthread_create(&(thread_id[i]), NULL, thread_des, NULL);
}
for (i = 0; i < NUM_THREAD; i++)
pthread_join(thread_id[i], NULL);
printf("result: %lld \n", num);
return 0;
}
void *thread_inc(void *arg)
{
int i;
for (i = 0; i < 50000000; i++)
num += 1;
return NULL;
}
void *thread_des(void *arg)
{
int i;
for (i = 0; i < 50000000; i++)
num -= 1;
return NULL;
}
上述示例共创建100个线程,其中一半执行thread_inc函数中的代码,另一半则执行thread_des函数中的代码,全局变量sum经过增减后的值应还是0,但是,我们在编译执行下程序
# gcc thread4.c -o thread4 -lpthread # ./thread4 sizeof long long: 8 result: 10862532
可以看到,结果并非我们预想的那样。虽然暂时不清楚原因,但可以肯定,冒然使用线程对变量进行操作,是有可能发生问题的。那么,这是什么问题?如何解决,我们会在后面的一章介绍