版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/rectsuly/article/details/78314404
这个小工具通过抓取12306网站提供的数据并进行解析,从而实现通过命令行的方式查询火车票余票数的功能。主要运用了docopt,requests,prettytable,colorama的库函数,达到简单熟悉Python3网络编程的目的。
运行效果如下: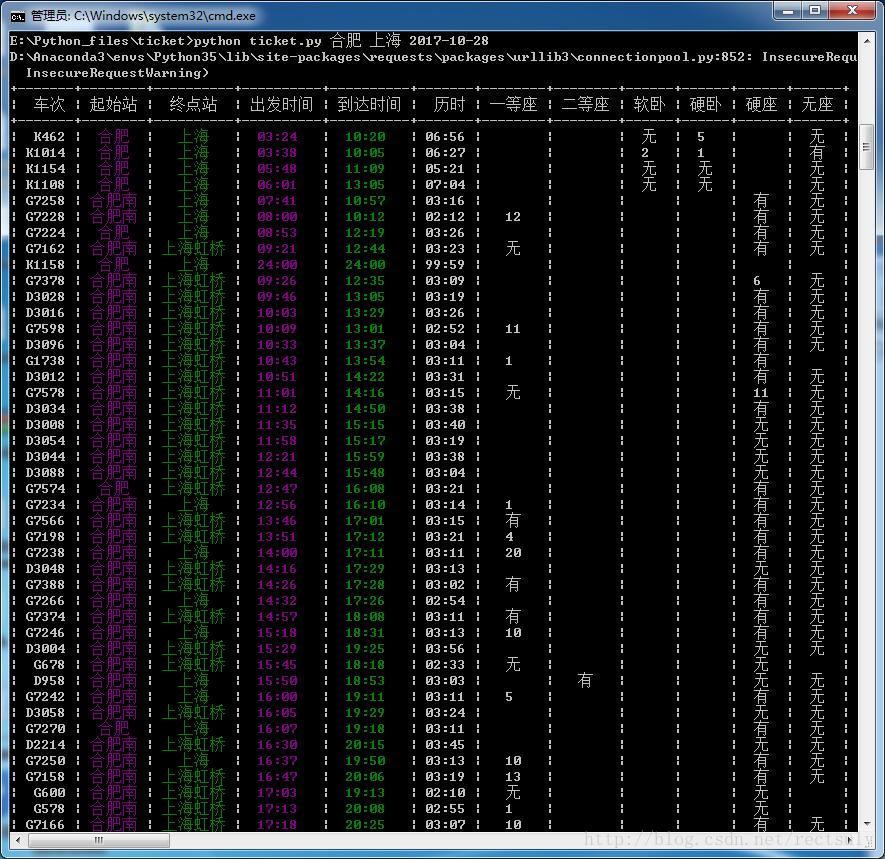
首先,我们用docopt这个库来解析Python的命令行参数,docopt可以按我们在文档字符串中定义的格式来解析参数,比如我们在代码中写下以下内容:
# coding: utf-8
"""命令行火车票查看器
Usage:
tickets [-gdtkz] <from> <to> <date>
Options:
-h,--help 显示帮助菜单
-g 高铁
-d 动车
-t 特快
-k 快速
-z 直达
Example:
tickets 北京 上海 2017-10-22
tickets -dg 成都 南京 2017-10-22
"""
from docopt import docopt
def cli():
"""command-line interface"""
arguments = docopt(__doc__)
print(arguments)
if __name__ == '__main__':
cli()接下来是获取数据,让我们先打开12306的官网,进入余票查询页面,随便查询一次从北京到上海的车次,然后按F12打开开发者工具,选中Network一栏,在调试工具观察下请求和响应:

从图中可以很容易找到请求数据的URL:https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2017-10-23&leftTicketDTO.from_station=SHH&leftTicketDTO.to_station=BJP&purpose_codes=ADULT
这个URL中包含了日期、始发站、终点站和票种这4个参数。
再来看看响应,返回的是JSON类型的数据格式:
{"validateMessagesShowId":"_validatorMessage","status":true,"httpstatus":200,"data":{"result":["bNRE8c%2BXEBWxgoY2%2BwD2EXNd9X3Vq%2Fsu%2F52Suzj1D5G04NUZC24nL3WDpgz1Ckjnylc6bjF63ZNe%0AQk%2F9%2B%2FYqE9Q5%2BXy2jBSf7CfRkAPcXYXsOUKWBp%2FBcsJhOK%2FmHgWqi%2Fx9RNh6I0hKLX1x6BIRQTwe%0AuRsDUVzFr2NeUUWimFq6ufEHCk2aPMJ4td%2FwykJHpgH4e02rqqdG7yOjTp44mSe9GdE8A%2FpDYPpt%0A%2FAsST4Q%2FbFk5|预订|24000000G704|G7|VNP|AOH|VNP|AOH|19:00|23:24|04:24|Y|PqkHst0aswwEKvaCVR7Uapmm3DXK8paJmjU9NSfvbnlBvCUt|20171022|3|P3|01|04|1|0|||||||||||无|无|3||O0M090|OM9","KoomdrHNm1Tx9kVBmvC7at4PpS5oSRXJfhdz%2FovAwoQDu38vAtxUk81JC5cbJRRzq46f%2BKv%2F1ISL%0AaHheZGr0eeDPqKg7ncxbkQRDKzQGJ4zm83g9PrLORv44LatQAMLcQbA9wt97ybVPrqiPAB7H5Cmy%0AiRtowmYcyhJkYvsIE8k1BkF4%2FVa7JPQMt7C2GQ4zbM2roP6V3Pq7frCqPy7xzeDzWwkgXcGDzmac%0Ag2jf3cG7VBs%2F|预订|24000000G900|G9|VNP|AOH|VNP|AOH|19:05|23:39|04:34|Y|pCGsb0O3dQbaBabrV4TJpg3t2pEoGaN%2Fhnbk74S03WODkZrD|20171022|3|P4|01|05|1|0|||||||||||无|1|11||O0M090|OM9","VWaI9EbpmOx%2BnPniU%2FgnFSU1FLqfyzaxu9pG27hFAtdcK%2FRdZAhRGUZeULWZGW%2F%2BOWSQd6n%2FnmFk%0AT83rJOW2qux1lQnKpPPTTLiLfbfEde21CBl2kueRvsA0meHGCfzY8VuIb6qHa5LkKvfLW8hn7q2F%0Akv728gU9%2FdBCTUXZdlc1zwGG%2FC2tsw5lounA0HQgjbfh0QjHOm8c81MfrEJ%2F81YXqNsPC6o4Tavp%0AUrDLzH1WiT4C48eUkBTTMjTx1QLG|预订|240000T1090W|T109|BJP|SHH|BJP|SHH|19:31|10:43|15:12|Y|aR5INYGawqzJ86i%2Fphbwbtd4ANudQ7765pg5VGHbH6Lnq8GodCgTCyGDmlbzTfQHQmqHJ8Wr%2B7s%3D|20171022|3|P4|01|08|0|0||2||无|||有||无|无|||||1040601030|14613","1k5vSGjsyUKKmnF3wjKsUjewdk7U69QKoVXEyQX2kMIKHIUYvqhE23w3IBA0epXq4CTrWtDQP7nz%0AQYIpWUj3Jaa276MN758C6iMAqkKbis6XLa%2B53stldGua11M3QTMDuczGfeVlVxkhlb00OfUAQsw1%0ASd1HGtLCeTuiwDWyt1aH0mcgx0ef7MdtrO2v%2BqxHarnz749ZZx0ikJslYx9HS%2Fo6bKoIXwRja64E%0AIRe8dPM%3D|预订|240000D3130S|D313|VNP|SHH|VNP|SHH|19:34|07:41|12:07|Y|zS7aXAcrDA9MGtYGt1qWAEjXj2KmL52pzmkIbYCX40Gbf8xJ|20171022|3|P3|01|04|0|0||||有|||无||||无||||O0O040|OO4","qHG7W4%2BkkK5wYlrA40Nad8qpBSQ62tAEoxqMmz8ILRPATCwg8tfv%2BwPfQtykNYj2ujediGM%2Bpfz0%0AnWWZf0ELHkPP1WFmc3oFgLsa2B0WzUbKUrI79%2Fe%2BEk%2FuI53VZclFnKpbhchiJ4Ftl67D7Q77pt%2Bv%0AeCwF1tP7sPQUd4coP%2Bdb3%2BQg0oE9sDXmhVjJNLUOHUz8MRoyIJBfV7D5cWvK49I9x6A%3D|预订|240000D3110I|D311|VNP|SHH|VNP|SHH|21:16|09:08|11:52|Y|WtArzt%2B3giRh6uPIHTnXnMFJMlFHLnOh|20171022|3|P2|01|04|0|0||||无||||||||||有|F040|F4","tSc61q3CsO1s7q4uL0veATeCmit1eJdnG1OBVn8VE8t9ow42zXNLbEeOppvc5A38DEQ%2BdYkMKMmq%0AD8krmmrRo1keh5YicUd3D9r4blEwKcaUnQ71pTMaJYxLRF5963S12ZYUXhD%2BULgWWQrKbT%2BuIpkg%0ATi3IREK9lJd0M5GTl4d9kA9ad7QsoyYPGe0cZAg6UN80GrcEUt5rMSaWfRR%2B1WVyJF8oq9dmE4mr%0AkPDK7ZA%3D|预订|240000D3210C|D321|VNP|SHH|VNP|SHH|21:23|09:13|11:50|Y|24U826GG6aSol8XIx79SYxePep2ul8PFdg5XcV9ThH1wMK0X|20171022|3|P2|01|04|0|0||||有|||无||||无||||O0O040|OO4"],"flag":"1","map":{"AOH":"上海虹桥","BJP":"北京","VNP":"北京南","SHH":"上海"}},"messages":[],"validateMessages":{}}https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9028
这个文件里的JSON内容就包含了所有车站的中文名、拼音、简写和代号等信息,我们先用re正则表达式写个小脚本来提取出所要的信息,新建stations_parse.py文件:
import re, requests
from pprint import pformat
url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9028'
response = requests.get(url, verify=False)
stations = re.findall(u'([\u4e00-\u9fa5]+)\|([A-Z]+)', response.text)
str = pformat(dict(stations), indent=4)
f = open("stations.py","w",encoding='utf-8')
f.write(str)
f.close()运行这个脚本,它将以字典的形式返回所有车站和它的大写字母代号,并输出到stations.py中。打开stations.py文件,完善字典的名称和文件头:
# -*- coding: utf-8 -*-
stations = { '一间堡': 'YJT',
'一面坡': 'YPB',
'一面山': 'YST',
'七台河': 'QTB',
'七甸': 'QDM',
'七营': 'QYJ',
'七里河': 'QLD',
'万乐': 'WEB',
'万发屯': 'WFB',
'万宁': 'WNQ',
'万州': 'WYW',
'万州北': 'WZE',
'万年': 'WWG',
'万源': 'WYY',
'三义井': 'OYD',
'三井子': 'OJT',
......class TrainCollection:
header = '车次 起始站 终点站 出发时间 到达时间 历时 一等座 二等座 软卧 硬卧 硬座 无座'.split()
def __init__(self, available_trains, options):
"""查询到的火车班次集合
:param available_trains:一个列表,包含可获得的火车班次,每个火车班次是一个字典
:param options:查询的选项,如高铁,动车,etc...
"""
self.available_trains = available_trains
self.options = options
def _color_print(self, item, color):
return color + item + colorama.Fore.RESET
@property
def train(self):
for item in self.available_trains['result']:
item = item.split('|')
train_no = item[3]
# 过滤为空或者是在过滤选项中
if not self.options or train_no[0] in self.options:
start_station = self.available_trains['map'].get(item[6])
end_station = self.available_trains['map'].get(item[7])
departure = item[8]
arrival = item[9]
duration = item[10]
yd = item[-4]
ed = item[-3]
rw = item[23]
yw = item[-7]
yz = item[-6]
wz = item[26]
row = [train_no,
self._color_print(start_station, colorama.Fore.MAGENTA),
self._color_print(end_station, colorama.Fore.GREEN),
self._color_print(departure, colorama.Fore.MAGENTA),
self._color_print(arrival, colorama.Fore.GREEN),
duration, yd, ed, rw, yw, yz, wz]
yield row
def pretty_print(self):
pt = PrettyTable()
pt._set_field_names(self.header)
for train in self.train:
pt.add_row(train)
print(pt)
def cli():
""" command-line interface"""
arguments = docopt(__doc__)
# print(arguments)
from_station = stations.get(arguments['<from>'])
to_station = stations.get(arguments['<to>'])
date = arguments['<date>']
options = ''.join([k for k, v in arguments.items() if
v is True])
# print(from_station, to_station, date)
# 构建URL
url = "https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date={}&leftTicketDTO.from_station={}&leftTicketDTO.to_station={}&purpose_codes=ADULT".format(
date, from_station, to_station)
# 添加verify=False参数不验证证书
r = requests.get(url, verify=False)
r_json = r.json()['data']
TrainCollection(r_json, options).pretty_print()完整代码见: