-
- 参数介绍
- 测试用例
- Test Case Group 1: FIFO vs. FAIR
- Test Case Group 2: FIFO 1 Slot vs. FIFO 4 Slots
- Test Case Group 3: FIFO 4 Slots vs. FAIR 4 Slots
- Test Case Group 4: FAIR 4 Slots, concurrentJobs = 1 vs. FAIR 4 Slots, concurrentJobs = 4
- Test Case Group 5: FAIR 4 Slots, concurrentJobs = 4, Root Pool vs. FAIR 4 Slots, concurrentJobs = 4, Independent Pools
在本系列的前一篇文章《Spark性能调优系列一:Spark的作业模型》中介绍了Spark作业的基础模型之后,我们要在本文讨论与Spark流计算性能相关的几个重要参数,这些参数对作业执行的并发性和资源分配有着很大的影响,我们会析这些参数以怎样的方式发挥作用,同时本文会讨论一系列的测试用例,这些用例通过设定不同的参数和数值的组合来辅助我们验证和理解这些参数配置的实际效果。本文原文链接: http://blog.csdn.net/bluishglc/article/details/80754855 转载请注明出处。
参数介绍
spark.scheduler.mode
默认情况下,Spark对于Job的排期策略是FIFO,也就是spark.scheduler.mode的默认值是FIFO,这一策略的含义是:先提交的作业会先被执行,但这也不是绝对的,如果当前执行的Job并没有占用到集群的全部资源(还有空闲的executors或cpu cores)则Spark会让后续的作业立即执行,这显然是“明智”的。当然,反方向上的极端是当一个Job很“重”需要耗用大量资源长时间才能执行结束时,后续的Job都会Delay!
从Spark 0.8开始,引入了一种新的作业排期策略:“FAIR”,顾名思义,就是让所有的Job能获得相对“均等”的机会来执行。具体的作法就是:将所有job的task按一种“round robin”(轮询调度)的方式执行。注意,这里的执行粒度“下放”到了Task,并且是跨job的,这样就变成在Job之下按更细粒度的单位:Task进行轮询式的执行,宏观上起到了Job并行的效果。
应该说spark.scheduler.mode是一个面向job级别的配置项,但是又不是这么简单,当它是FIFO时,我们可以认为它的“作用”粒度是Job,当它是FAIR时,为了真正能使得各个作业获得均等的执行机会,实际上的作业调度已经细化到了Task级别,在Spark的源代码org.apache.spark.scheduler.Pool#getSortedTaskSetQueue中我们可以看到,在同一个pool中,所有作业的Task都会依据配置的spark.scheduler.mode来对tasks统一进行排序,然后依次提交给Spark Core执行,所以说,实际的控制粒度是在task层面上的,但是对于这一点的理解也不要过,从实际并行作业的event timeline上看,这种并行并不是在两个作业中频繁地交替执行Tasks(这样的做话显然是代价巨大的), 而是在一个较长的作业中间“嵌套”进去一到两个相对短作业一直到它们执行结束再切回到长作业继续执行。
override def getSortedTaskSetQueue: ArrayBuffer[TaskSetManager] = {
var sortedTaskSetQueue = new ArrayBuffer[TaskSetManager]
val sortedSchedulableQueue =
schedulableQueue.asScala.toSeq.sortWith(taskSetSchedulingAlgorithm.comparator)
for (schedulable <- sortedSchedulableQueue) {
sortedTaskSetQueue ++= schedulable.getSortedTaskSetQueue
}
sortedTaskSetQueue
}spark.streaming.concurrentJobs
concurrentJobs要配合FAIR模式一起工作,同时你还要清楚你的集群是否有足够的资源来支撑更多并发作业,如果没有适当的资源的话,加大concurrentJobs的数值是不是会有显著的并行度和吞吐量的提升的。这里还是要再叮嘱一下:即使是concurrentJobs=1,如果集群有空闲的计算资源,Spark也同样会激活新的作业去并行执行的。
scheduler线程池
FAIR模式给每一个作业提供了均等的执行机会,但是这未必能解决这样一类问题:假定在一个Spark Streaming应用里有一个很重的作业,比如有两三百个Task,同时还有几个很小的作业,可能只有能几个Task,按FAIR的轮询调度,每个作业都有均等的机会执行各自的Task, 这样形成的结果是在一个相对固定的时间周期内,长Job作业与众多短作业执行完毕的数量是一样,比例都是1:1:1…., 那么,如果我们的需求是让这些短作业执行的频率加快,以更加实时的速率来处理数据,那么就势必要给到这些短作业更多的资源来执行Task, 那么这时就需要为这些作业引入独立的执行线程池,并配置相应的资源占用权重来解决了,具体的做法就是在代码中加入
// Assuming sc is your SparkContext variable
sc.setLocalProperty("spark.scheduler.pool", "pool1")这样,在当前线程(即调用RDD.save, count, collect的线程)中提交的作业都会使用这个指定的pool运行作业。
在没有引入任何上述代码时,所有的作业实际上是在公用一个root的线程池,这样整个集群的计算资源都分配给了这一个root线程池,然后,如果我们制定了spark.scheduler.mode=FAIR,那含义就是:所有的作业会有均等的机会轮流占用全部的资源执行任务。那么就会出现我们前面提到的那个问题。而解决方法就是:既然pool是对计算资源的划分,那么我们就可以为不同的作业引入多个独立的pool, 然后给这些pool分配相应的权重让它们来按比例来分配整体的计算资源,然后在pool内部再FAIR模式让其对应的那些Job以均等机会获取到制定配置的资源去执行!这听上去有一点抽象,我们使用会在后面的测试用例中详细的说明。
测试用例
本文全部测试用例涉及到4个作业:persist_cpu_usage,persist_mem_free,evaluate_cpu_usage,evaluate_mem_free,其中前两个是短作业,只有一个Task,没有任何shuffle动作,后两个是长作业,都含有shuffle操作,我们是在一个单节点集群上执行测试用例的,计算资源有限,为了拉大长短作业的执行时间差,我们特意将spark.sql.shuffle.partitions设置成了100,这不是从性能最优来考虑的,如果从性能考虑,我们会把大大降低shuffle.partitions的数值。
Test Case Group 1: FIFO vs. FAIR
Test Case 1-1: FIFO
- 配置
spark.num.executors=1
spark.executor.cores=1
spark.streaming.concurrentJobs=1
spark.scheduler.mode=FIFO
spark.sql.shuffle.partitions=100
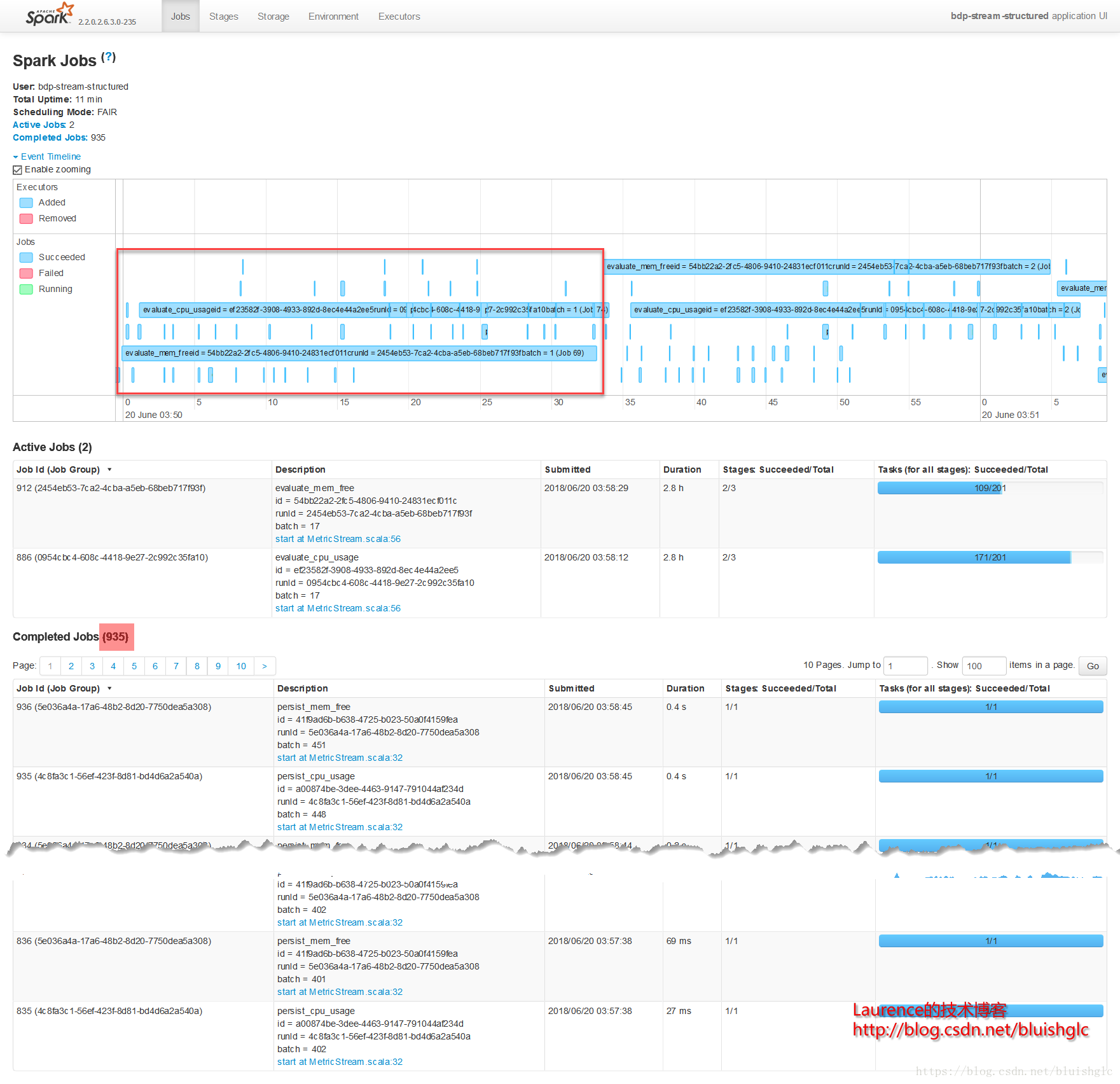
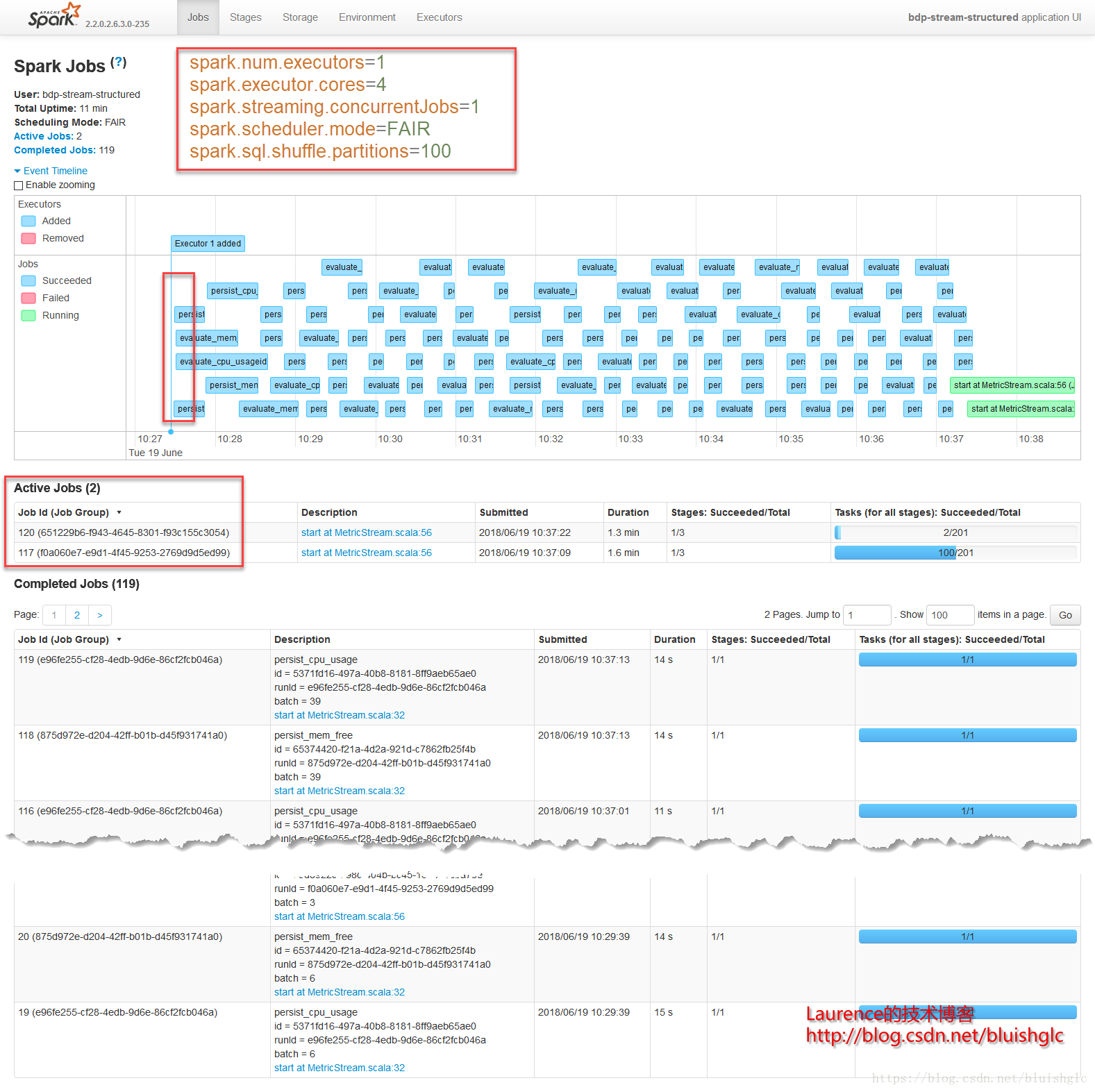
所有Job使用default pool (spark.scheduler.pool=default)- 结论
看上去所有的Job是在并发执行的,但是Job页面在显示上是有些歧义的,它显示的进度条是从作业提交到执行结束的整个时间跨度,在本例上,前四个作业的提交动作是一个很轻量的动作,在一开始的很短的时间内变相继完成了,所以看上去几乎是在同时开始并且在“并行”执行,但是实际的情况是:作业提交后,是按0,1,2,3顺序执行的,因为我们限定了非常有限的资源,Job的排期使用的又是FIFO,所以,这此Job的实际上按先后顺序依此执行的,也就是说越后面的Job在提交之后的等待时间越多!这一点我们后面会从Task页面得到验证。
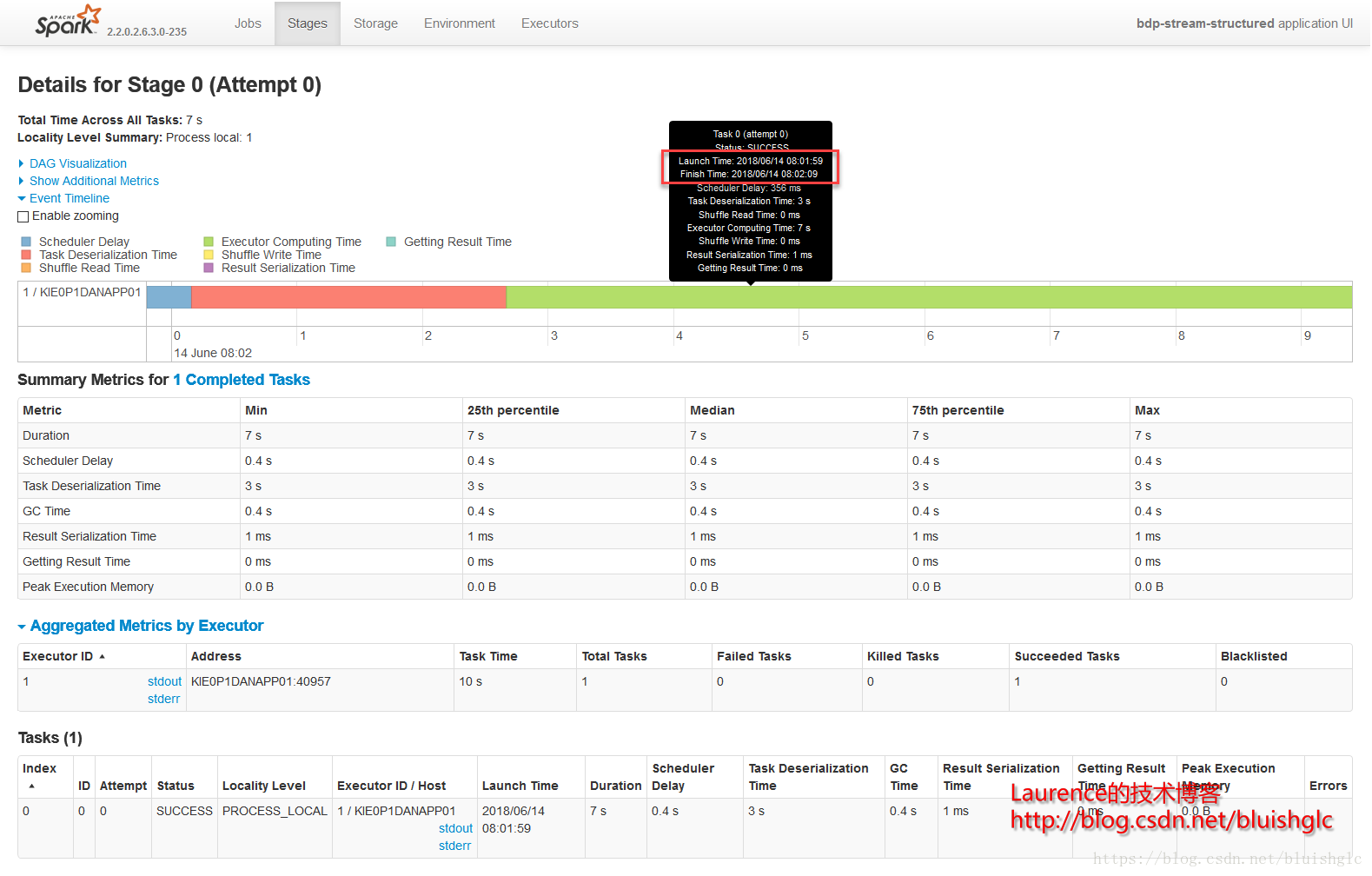
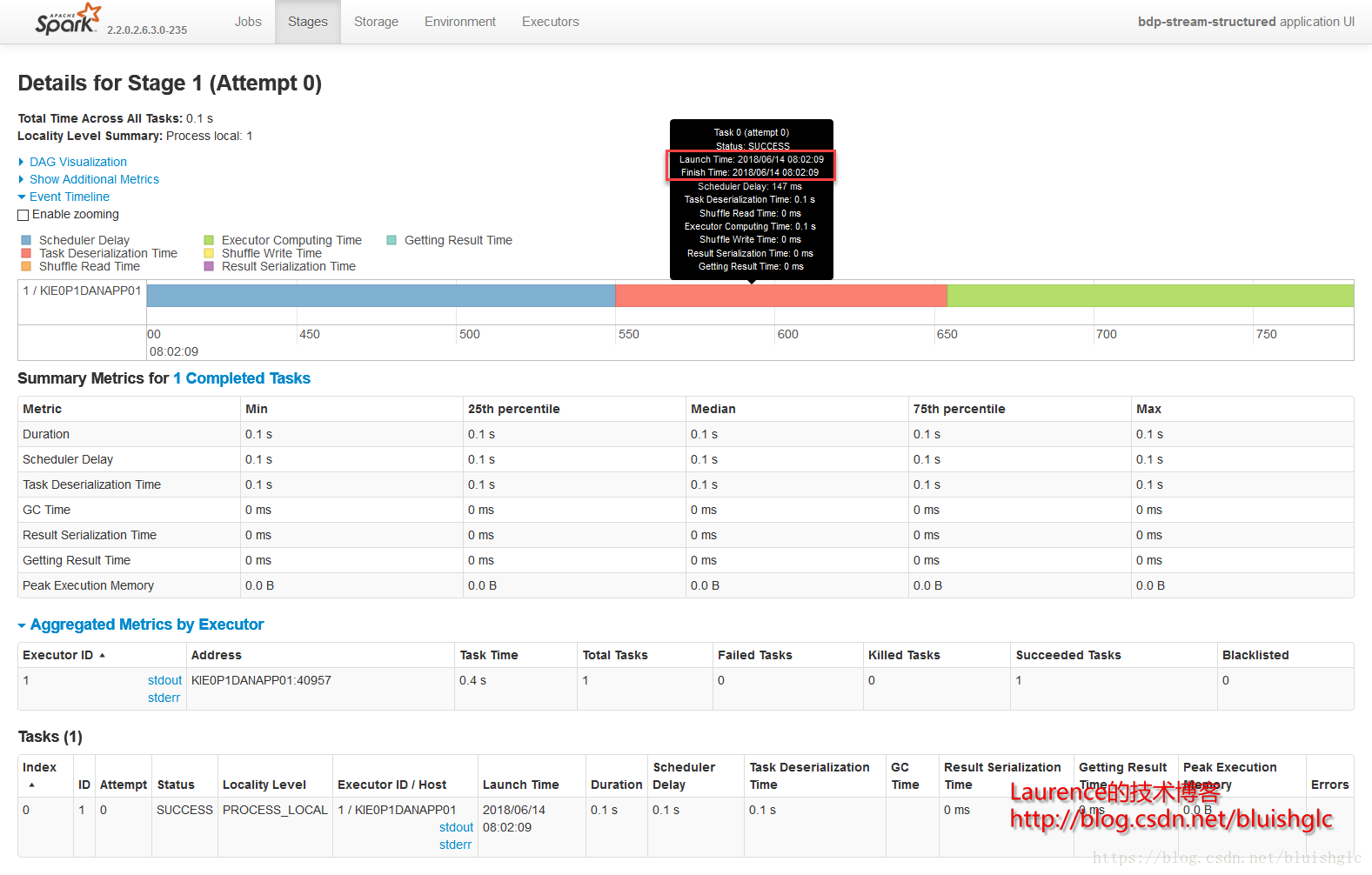
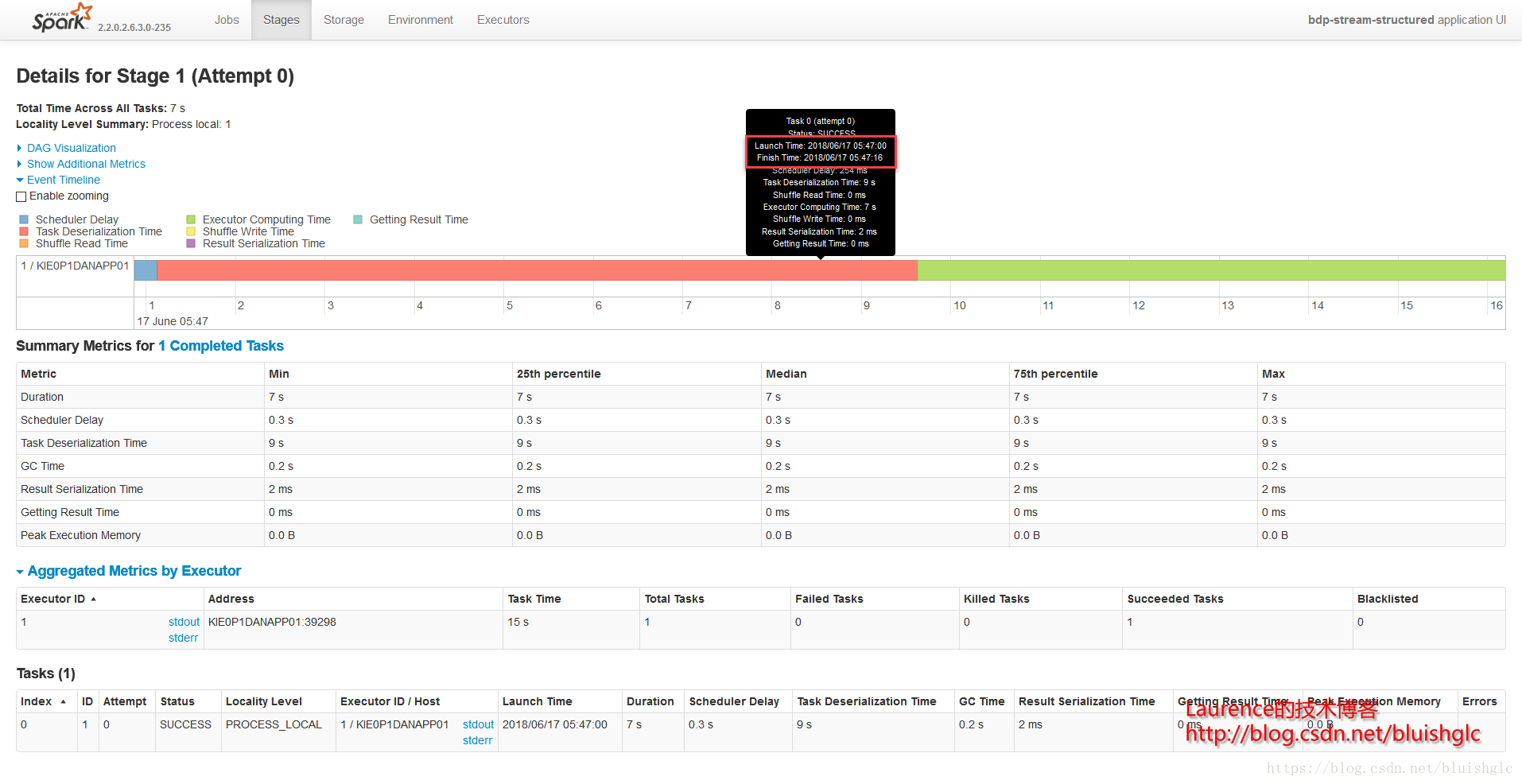
Stage 0和Stage 1分属两个独立的作业,且都只有一个Task,第二个Job的Task紧紧跟随第一个Job的Task执行完成之后开始执行,这说明集群Task的并行度(slot)是1,并且作业的排期是FIFO模式,所以所有的Job都是先进先出的串行执行。
Job
Stage 0
- Stage 1
Test Case 1-2: FAIR
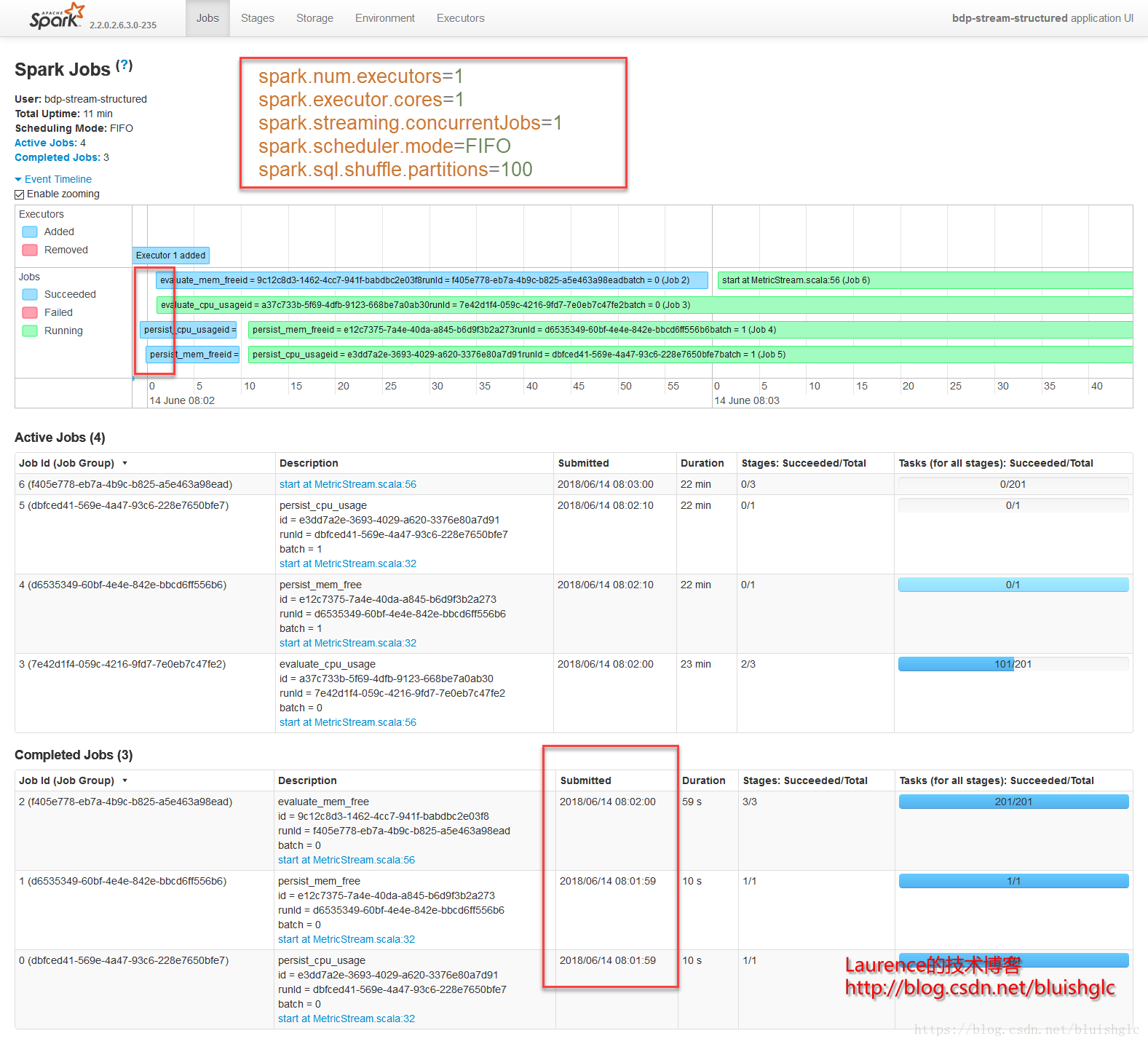
- 配置
···
spark.num.executors=1
spark.executor.cores=1
spark.streaming.concurrentJobs=1
spark.scheduler.mode=FAIR
spark.sql.shuffle.partitions=100
···
- 结论
FAIR模式下,作业视图和前面的FIFO区别不大,在提交时,都可以很快完成,造成各个作业是在“并行”的假象,但实际上的并行度是不能依赖作业视图来判断的(在计算资源充足的情况下另当别论,那时所有提交的作业往往可以立即被分配资源执行,这种情况下可以认为作业视图中蓝色的进度条就是做业的实际执行时间)因为我们的测试中资源都是严格限定的,这会导致很多作业从提交到能够得到资源开始执行之间有大量的等待时间,所以不能把这些蓝色进度条当作实际的Job执行时间。
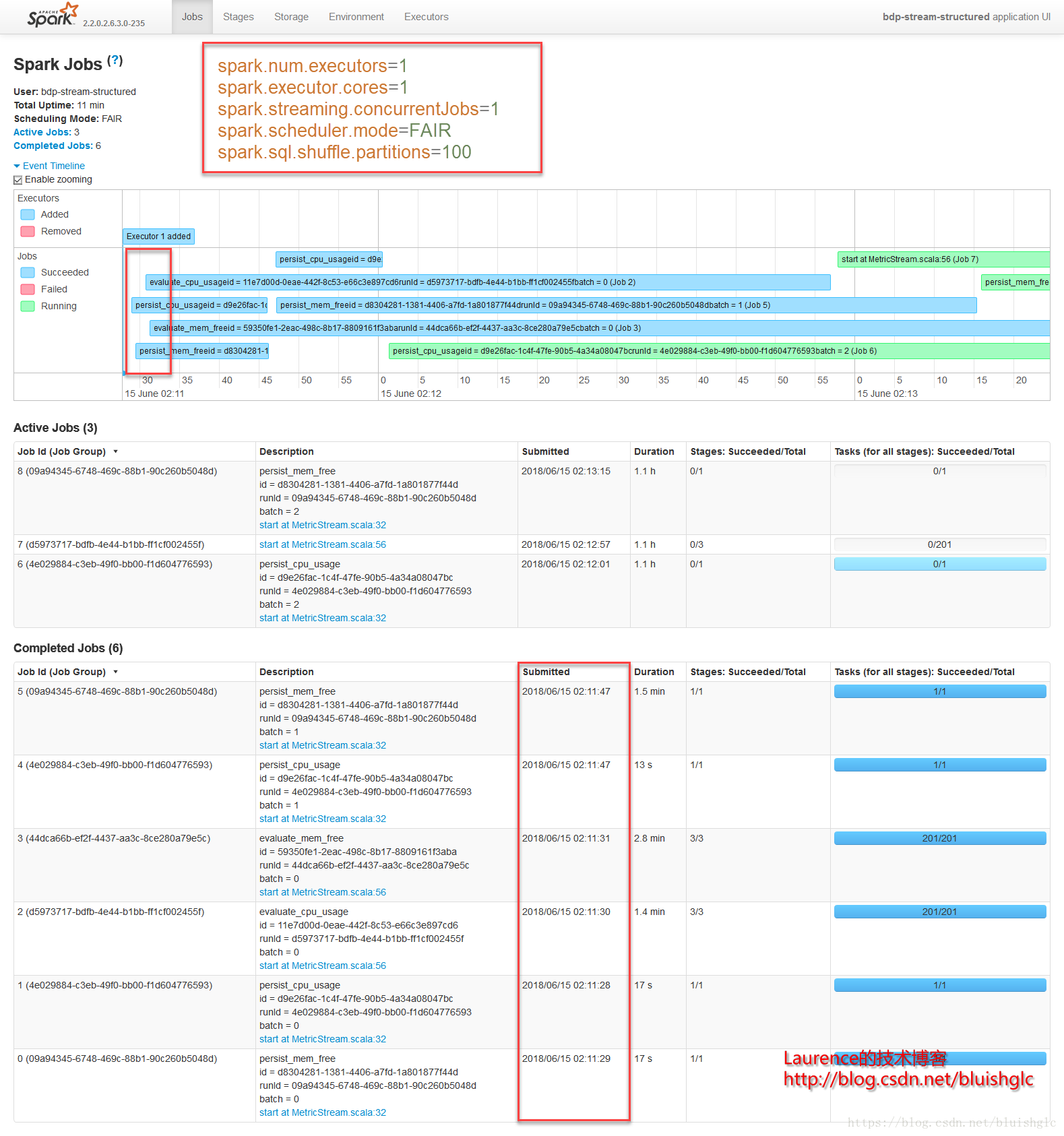
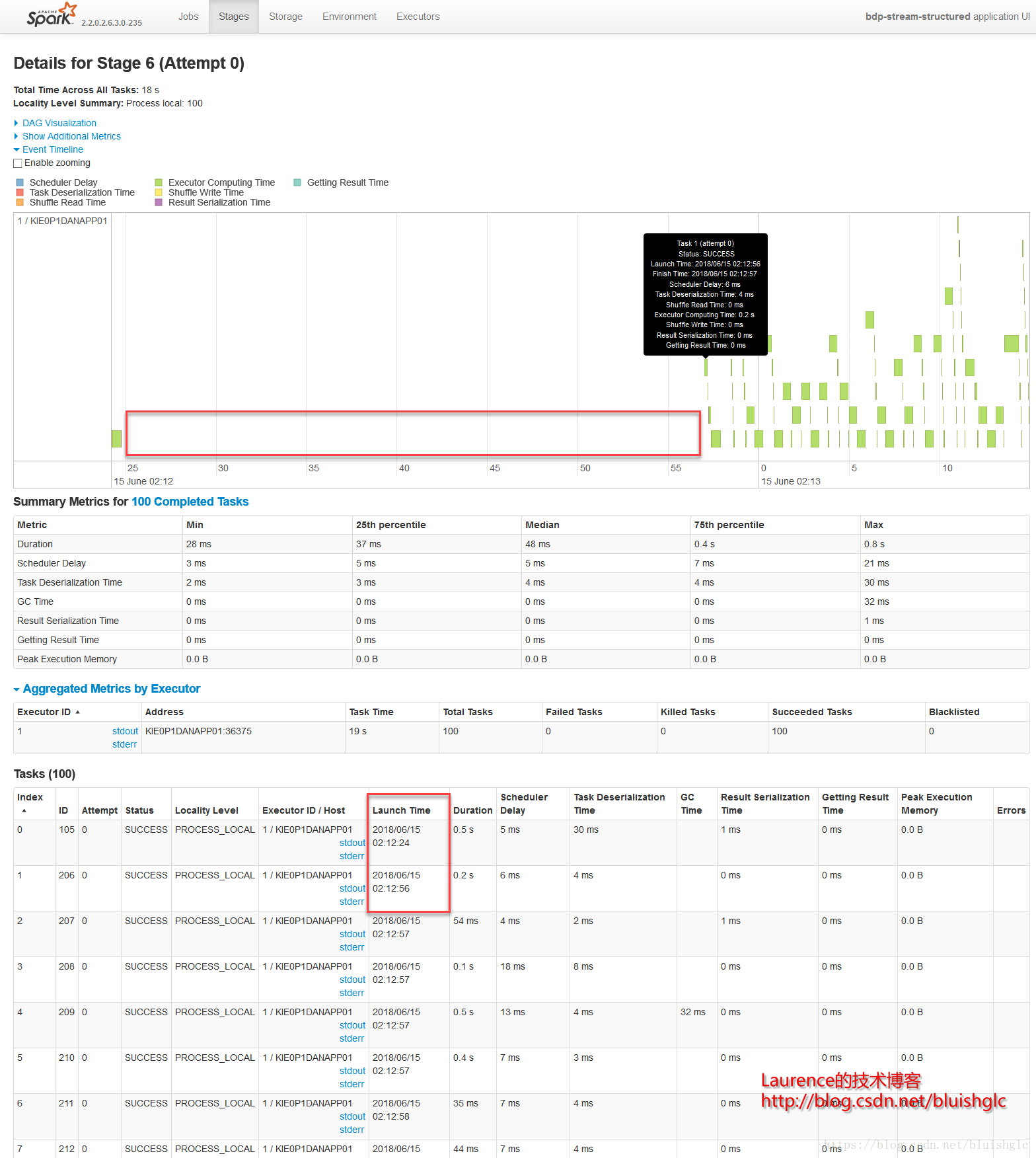
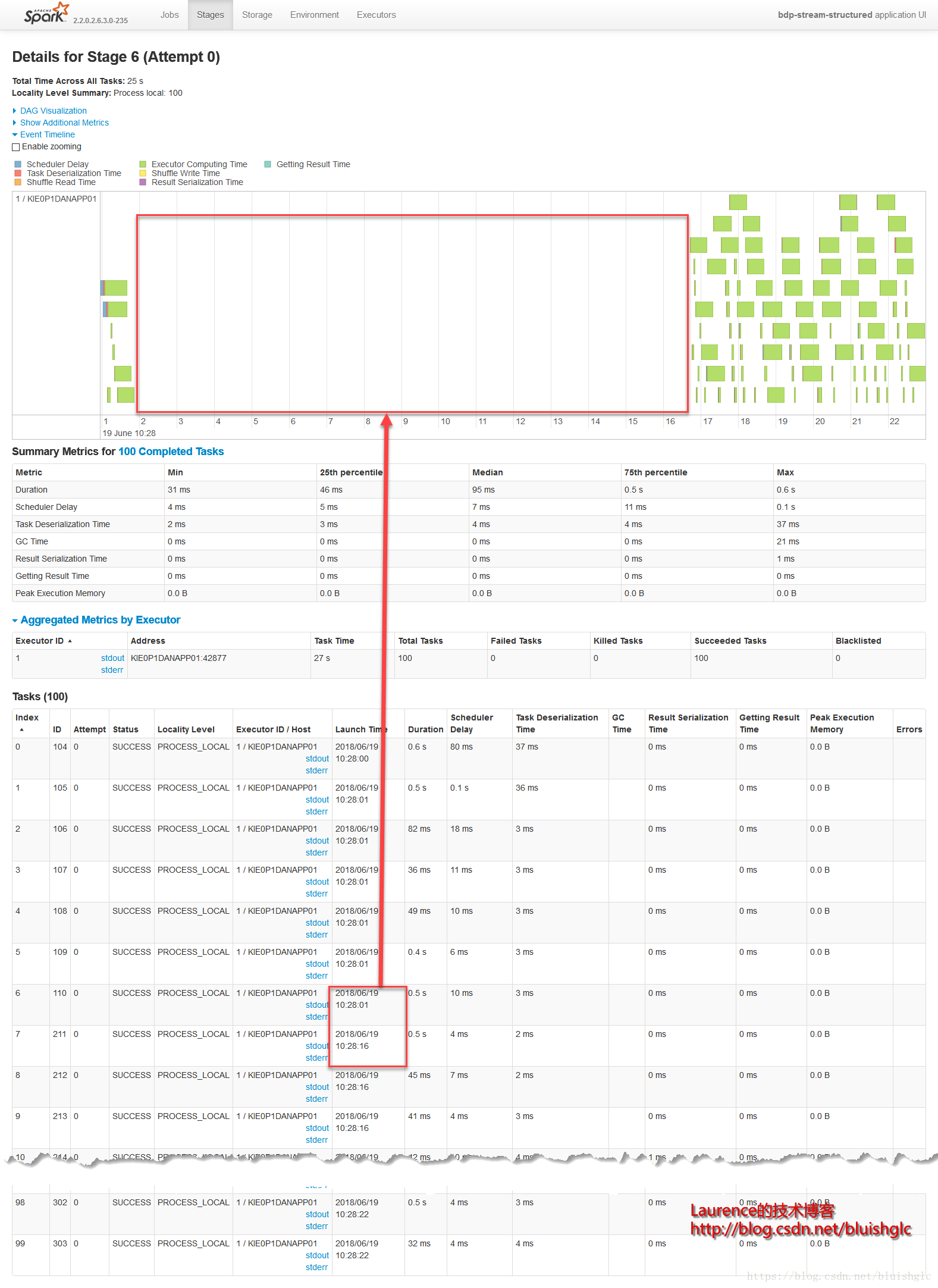
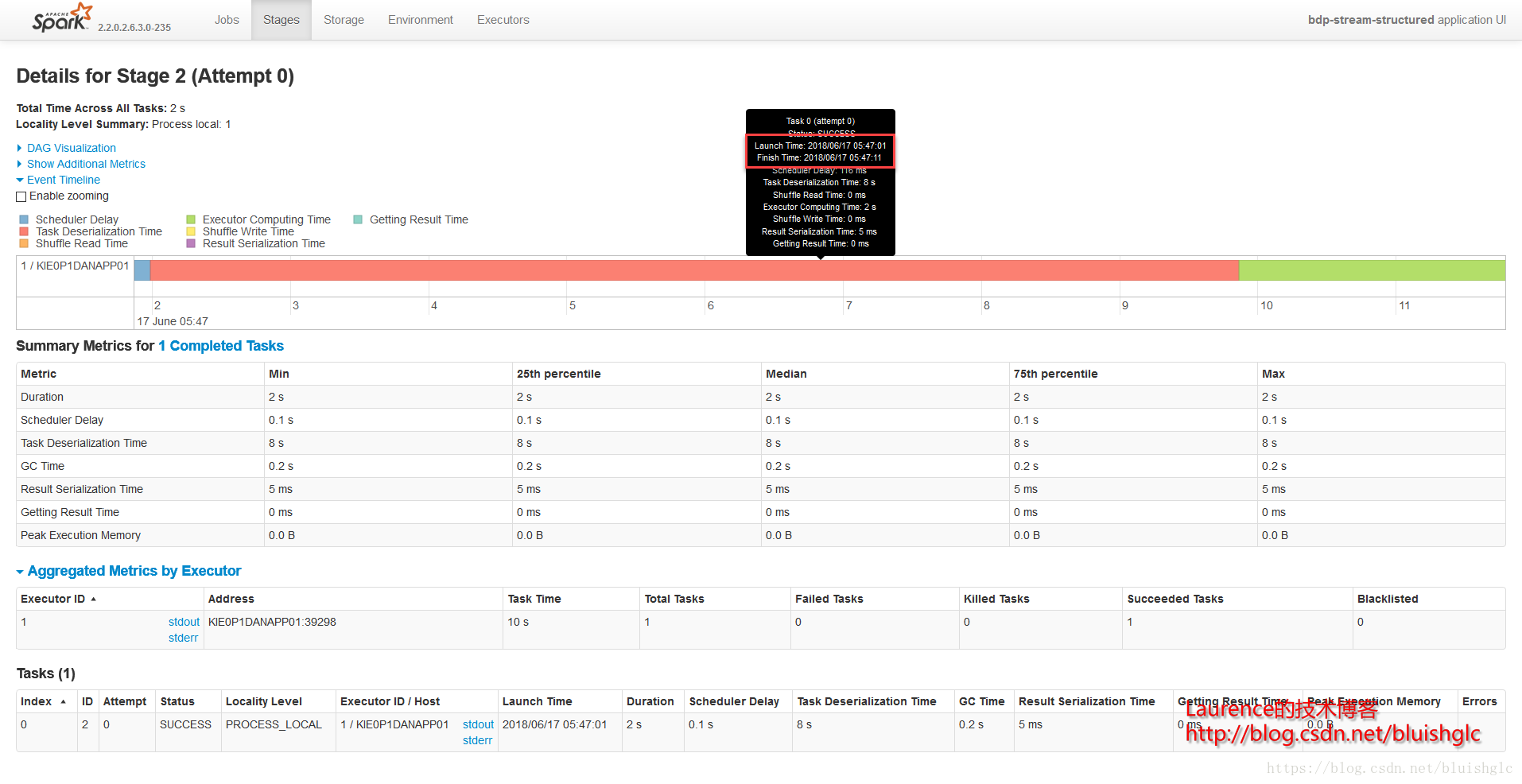
但是在FAIR模式下,确实发生了一些不同,我们继续看:Stage 6 & 4是对FAIR模式的一个很好的诠释,从Stage 6的截图上可以看到在02:12:24到02:12:56之间有32秒的空白,而这段时间正好是Stage 4在执行,两个Stage隶属两个不同的Job,产生这一结果的原因是在FAIR模式下,不同的Job会获得同等的执行机会,也就是在所有已提交的作业中,Spark使用轮询调度的方式从各个作业中依此选取Task执行。但是本例在展示跨Job的Task轮询调度上显得不是很典型,这是还是因为我们在这个示例中的限定了很有限的计算资源导致的,后续的示例中会有更好的演示示例。
Job
Stage 6
Stage 4
Test Case Group 2: FIFO 1 Slot vs. FIFO 4 Slots
Test Case 2-1: FIFO 1 Slot
这个Case就是 Test Case 1-1: FIFO
Test Case 2-2: FIFO 4 Slots
- 配置
spark.num.executors=1
spark.executor.cores=4
spark.streaming.concurrentJobs=1
spark.scheduler.mode=FIFO
spark.sql.shuffle.partitions=100- 结论
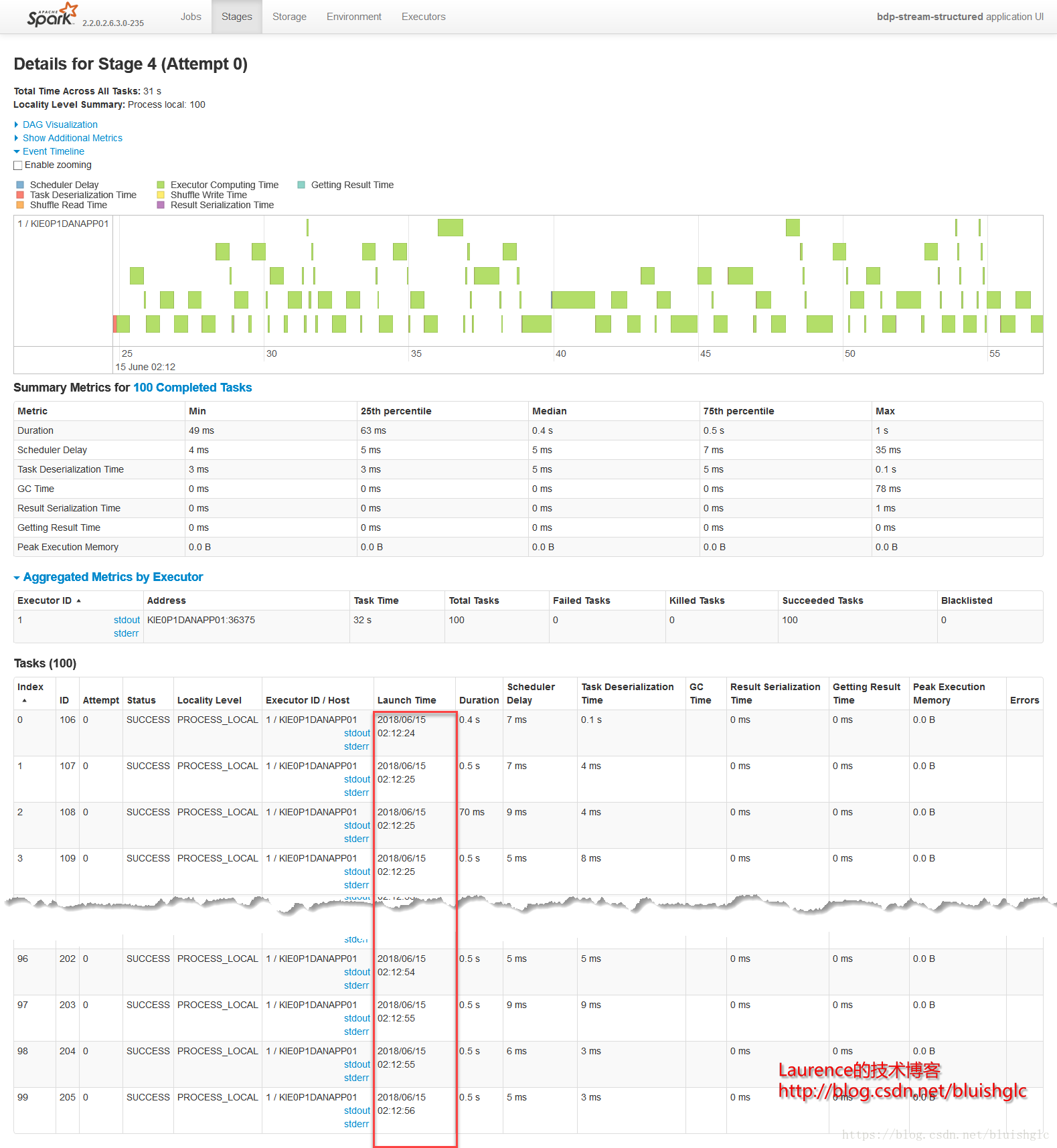
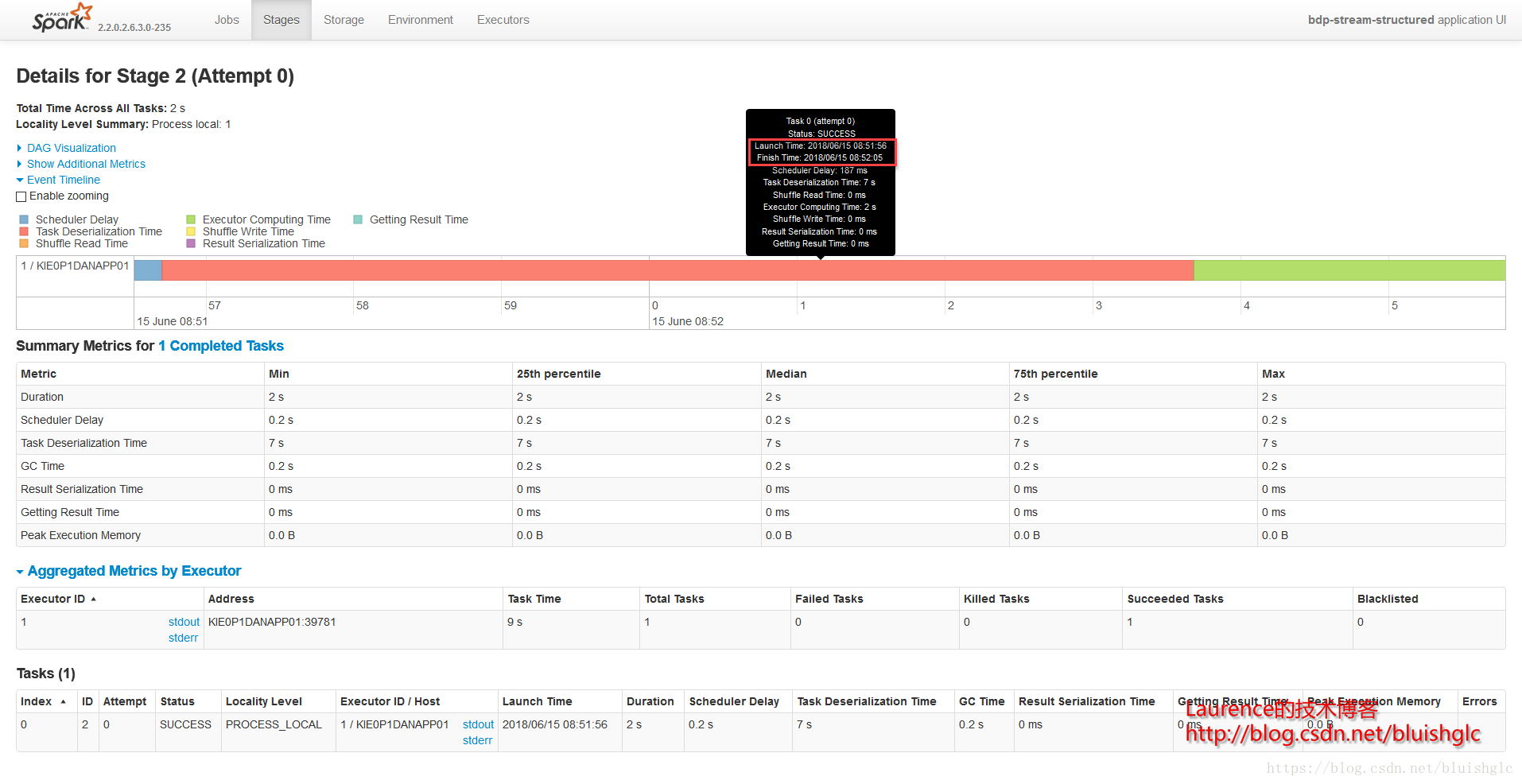
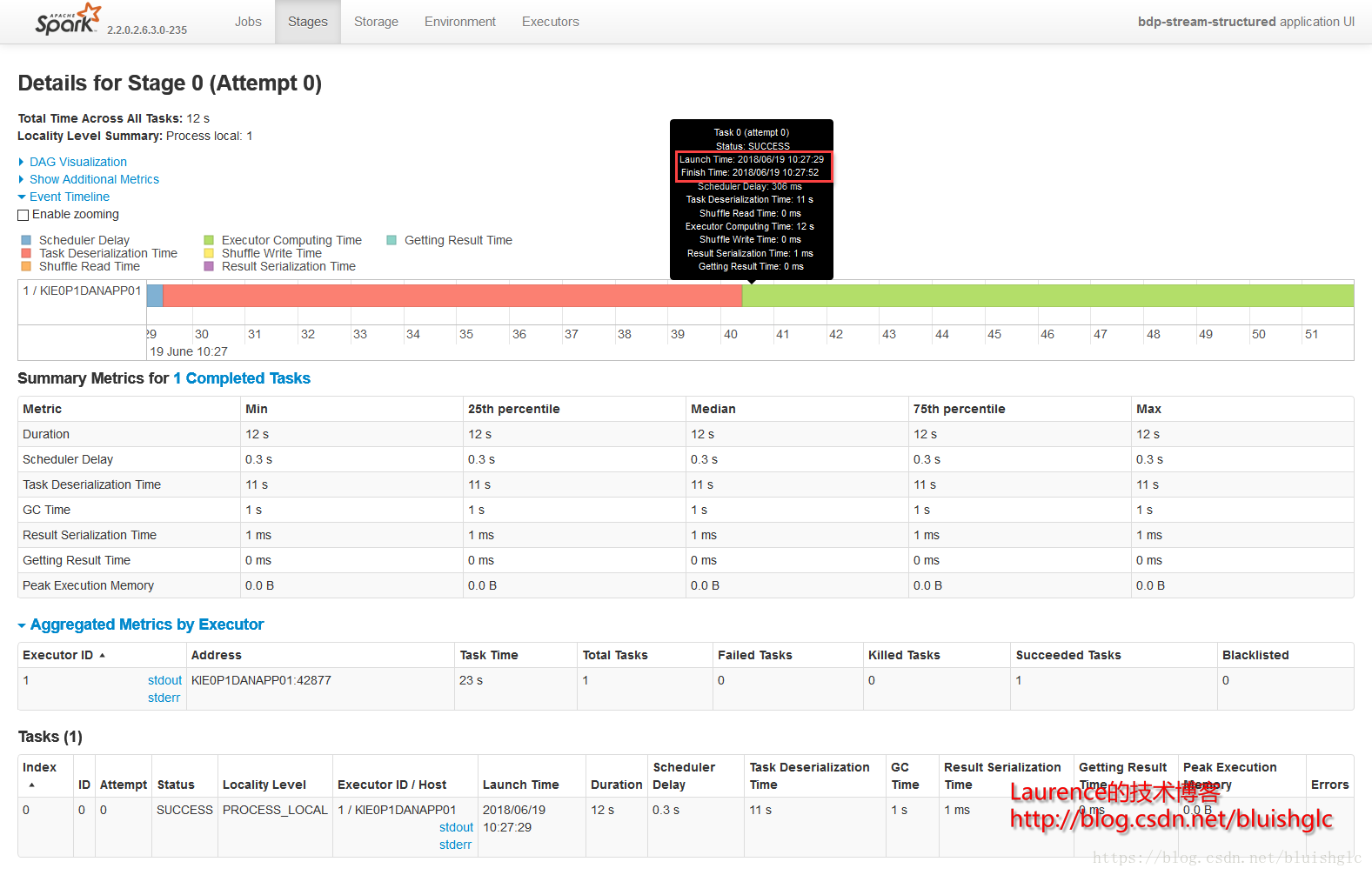
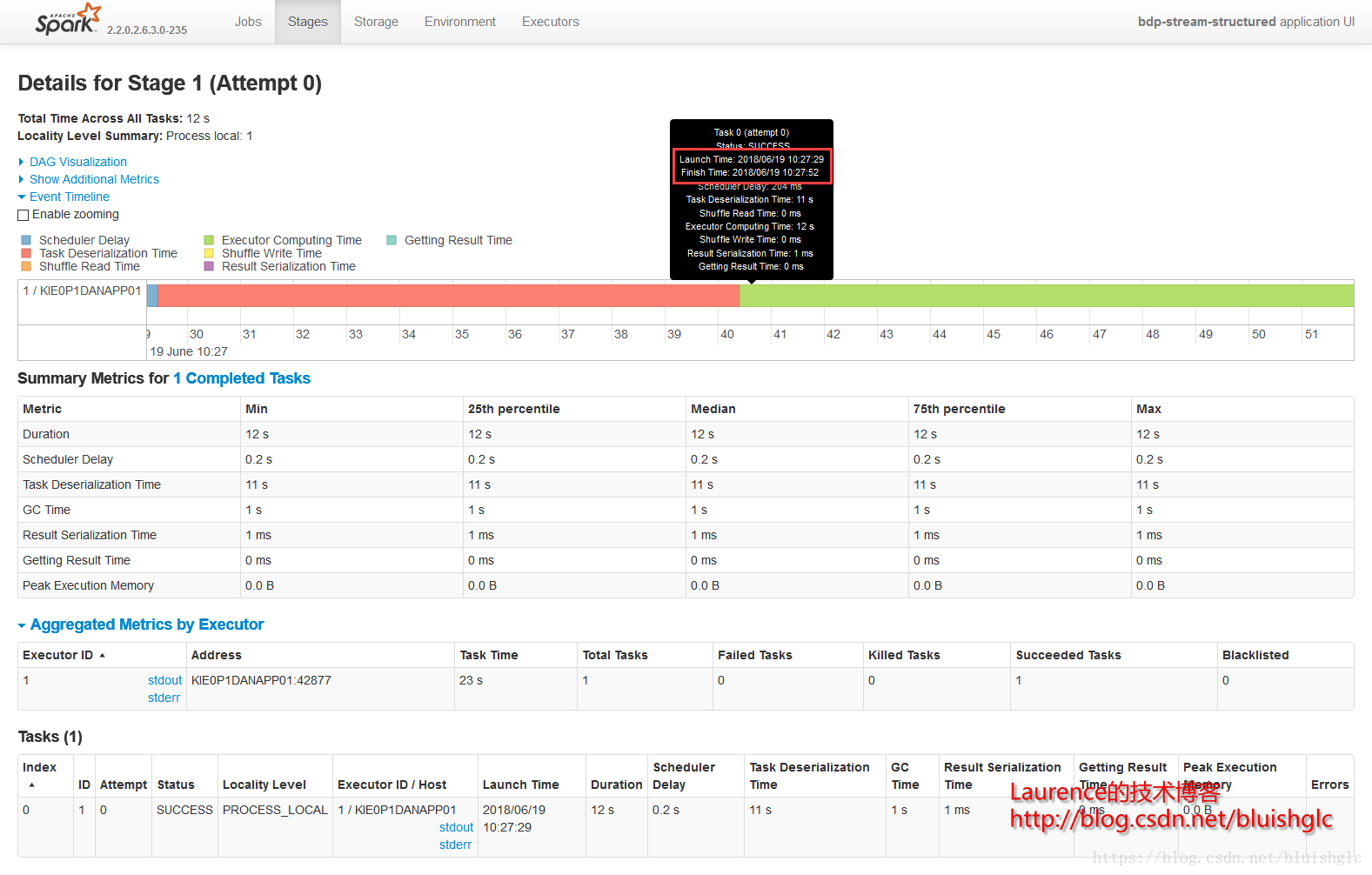
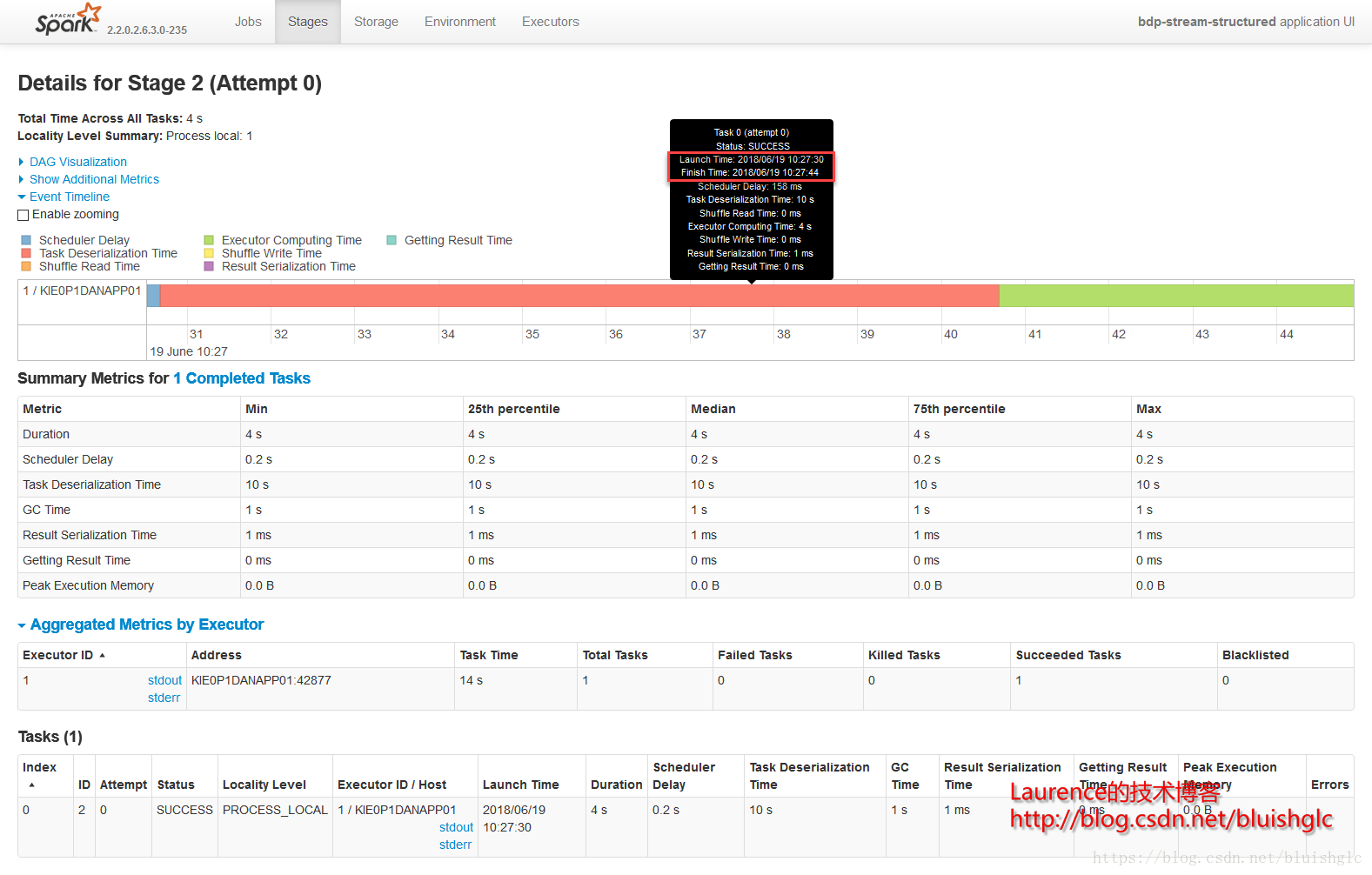
在cores从1提长到4之后,作业层面一个宏观的改变是作业的并发度得到了提升!后续Task层面的执行历史能更准确地体现这一点。这里要着重解释的是虽然spark.scheduler.mode=FIFO,但是这并不意味着不存在作业级别的并发,Spark文档中对FIFO的介绍中也特别强调道:如果当前提交的作业并没有占据集群的全部资源,则后续的作业会跟进提交并执行!这在我们这个测试用例中得到了很好的体现。我们可以看到在08:51:55到08:52:10这段时间,Job 0(Stage 0)和Job 1(Stage 1)这两个作业是严格意义上并行的!并且这类情况在后续频繁发生,这就是对FIFO模式在资源充裕时允许并行多个作业的展示。
另外一个要补充的是,在扩充为4核之后,像Stage 3这样比较重的计算,并行程度得到提升,执行时间大幅度缩短,对比前面所有1核的测试用例我们可以发现,用于只有一个可以的core, 每个stage,特别是有100个task的重的stage, 它们的task都是串行的,在同一个时间点上,只有一个在running的task,而本例中core提升为4之后,同样的stage, 任意时刻总是有4个running的task.
- Job
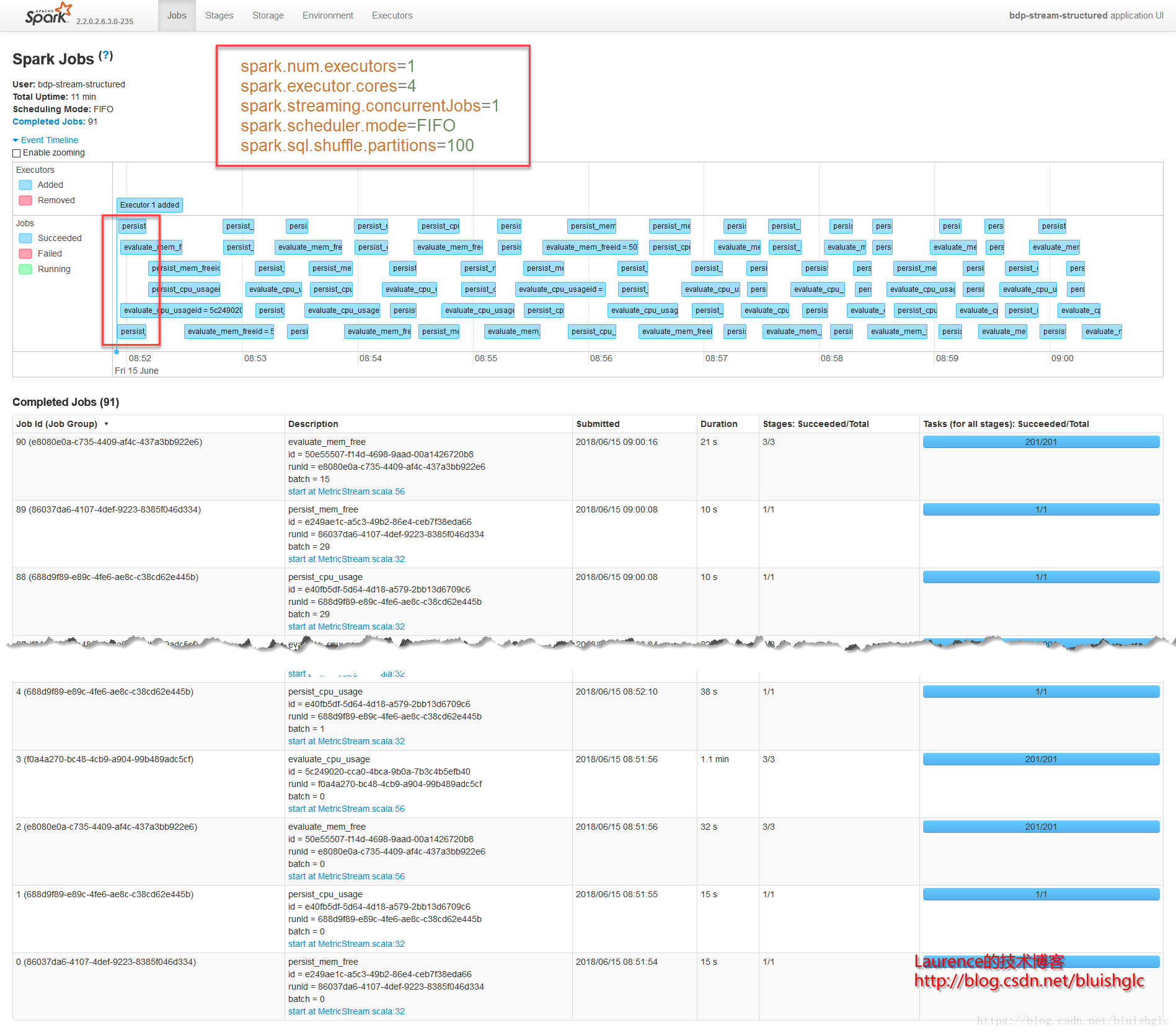
Stage 0
Stage 1
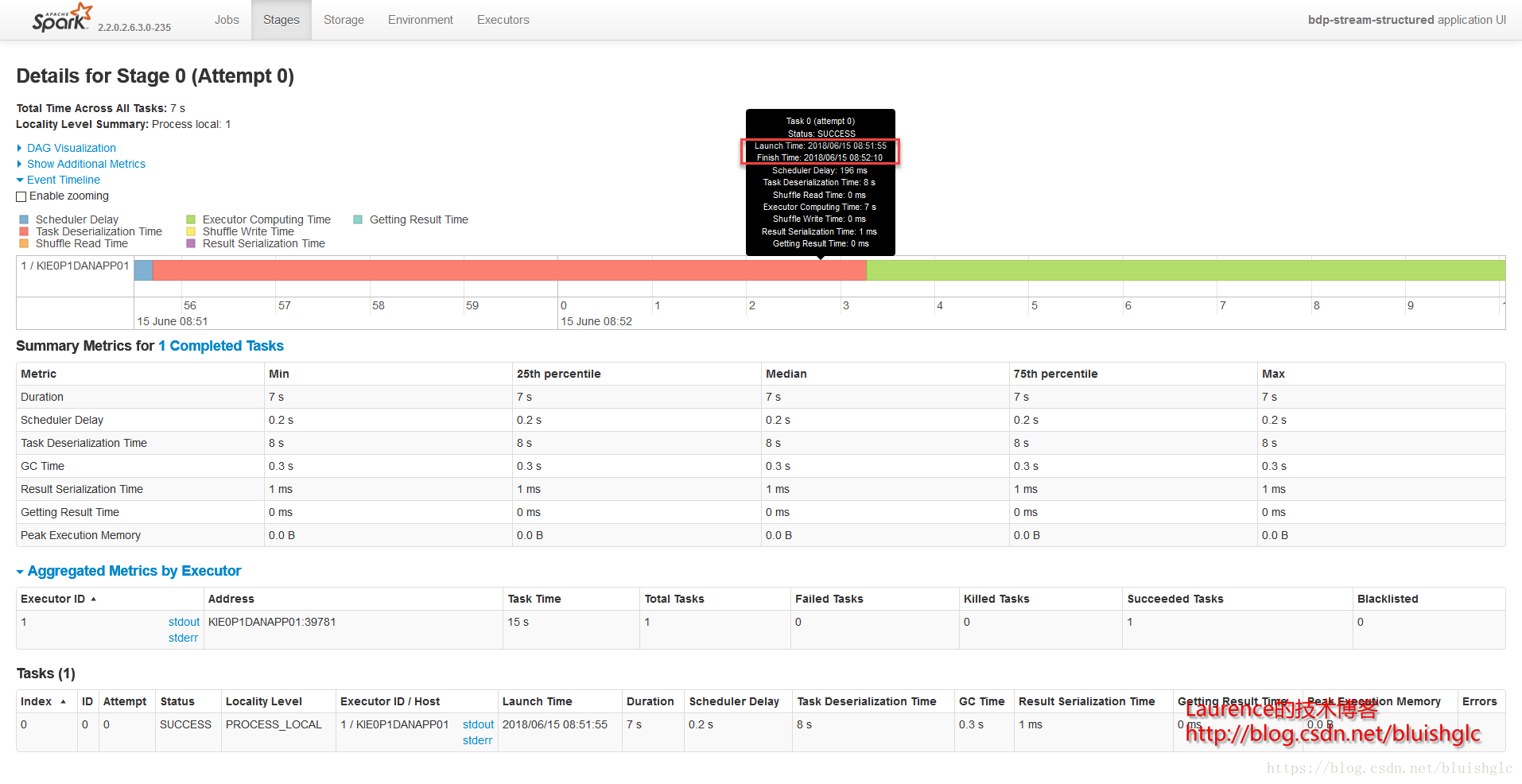
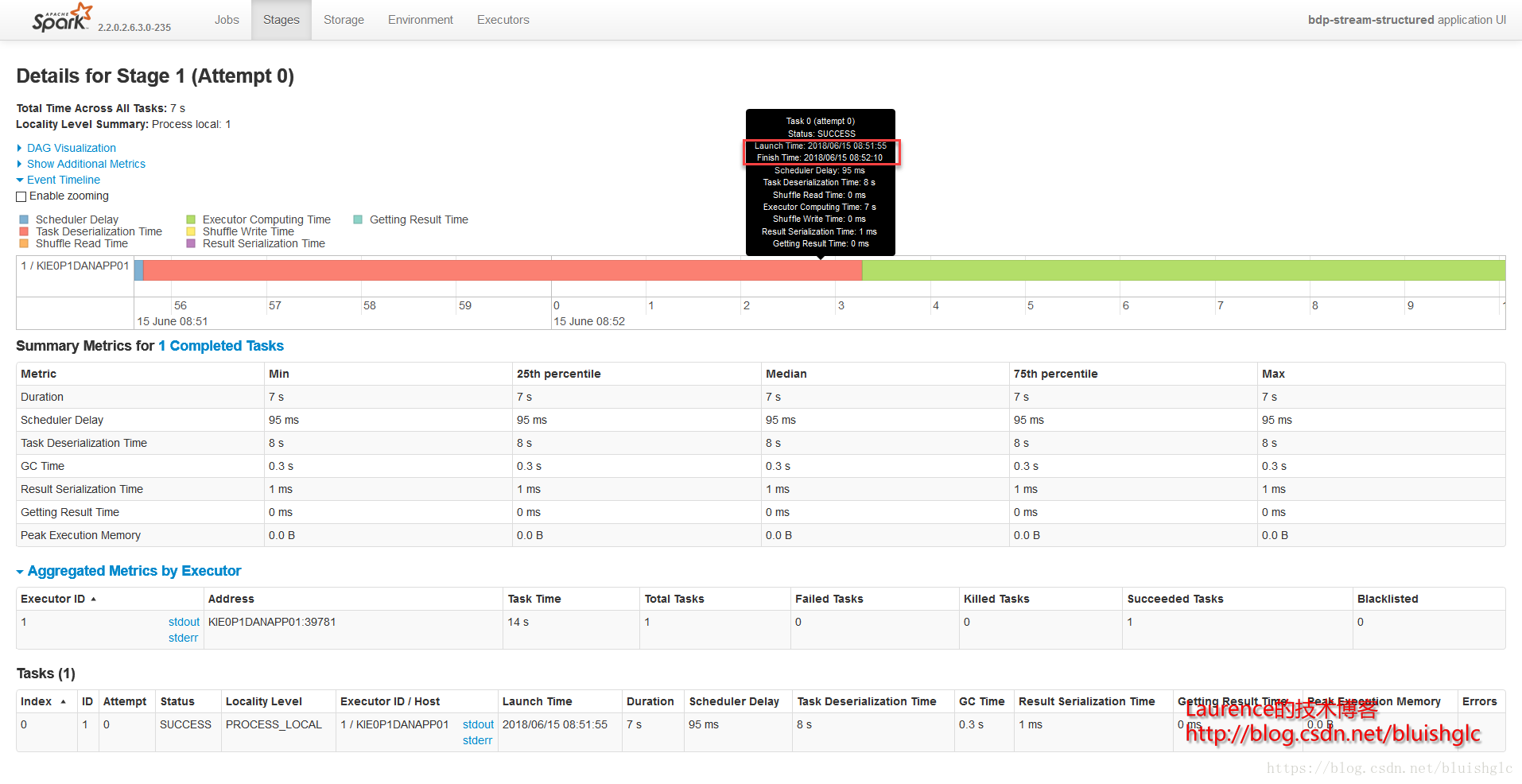
- Stage 2
- Stage 3
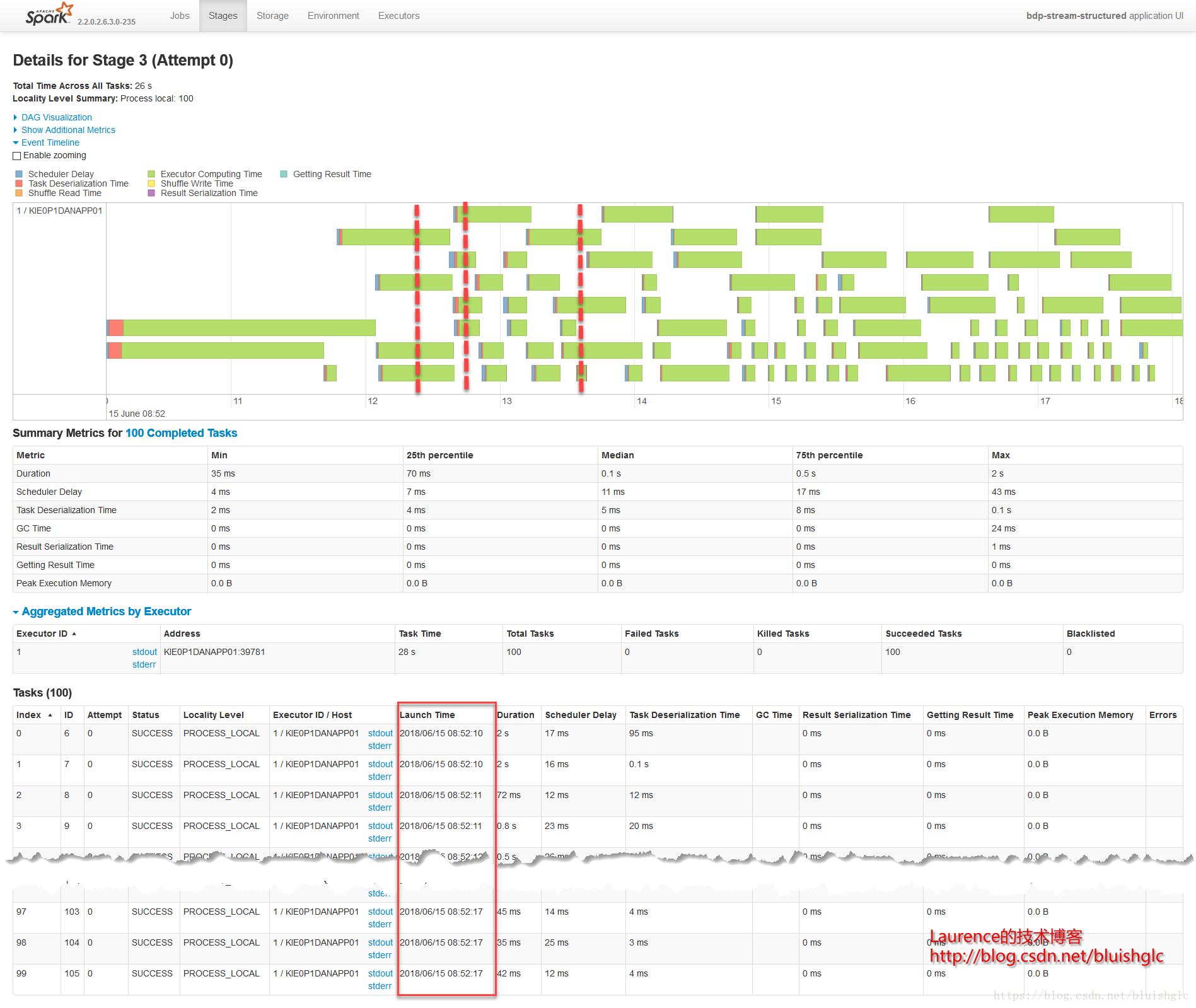
Test Case Group 3: FIFO 4 Slots vs. FAIR 4 Slots
Test Case 3-1: FIFO 4 Slots
这个Case就是 Test Case 2-2: FIFO 4 Slots
Test Case 3-2:FAIR 4 Slots
- 配置
spark.num.executors=1
spark.executor.cores=4
spark.streaming.concurrentJobs=1
spark.scheduler.mode=FAIR
spark.sql.shuffle.partitions=100- 结论
首先,对比, 本用例改为FAIR模式后最大的一个变化就是作业的整体吞吐量由原来的91个Job提升到了119个Job(concurrentJobs并没有变,依然是默认值1), 这有力地证明了FAIR模式可以提升作业的并行度,当然,更加显著的效果要配合提升concurrentJobs,我们会在下一个测试用例中了解到。
从Job页面以及前三个Stage上看,本测试和对比测试《Test Case 3-1: FIFO 4 Slots》是很类似的,对于FIFO我们前面已有解释,但是对于FAIR模式我们也要认清一点:即使concurrentJobs=1,Spark也会遵从与FIFO同样的原则:如果集群当前尚有空闲资源,则处于等待状态中的作业一定会被激活。例如在本例中,我们就可以从Job截图上看到,虽然concurrentJobs=1,但是依然有两个Active的Job。
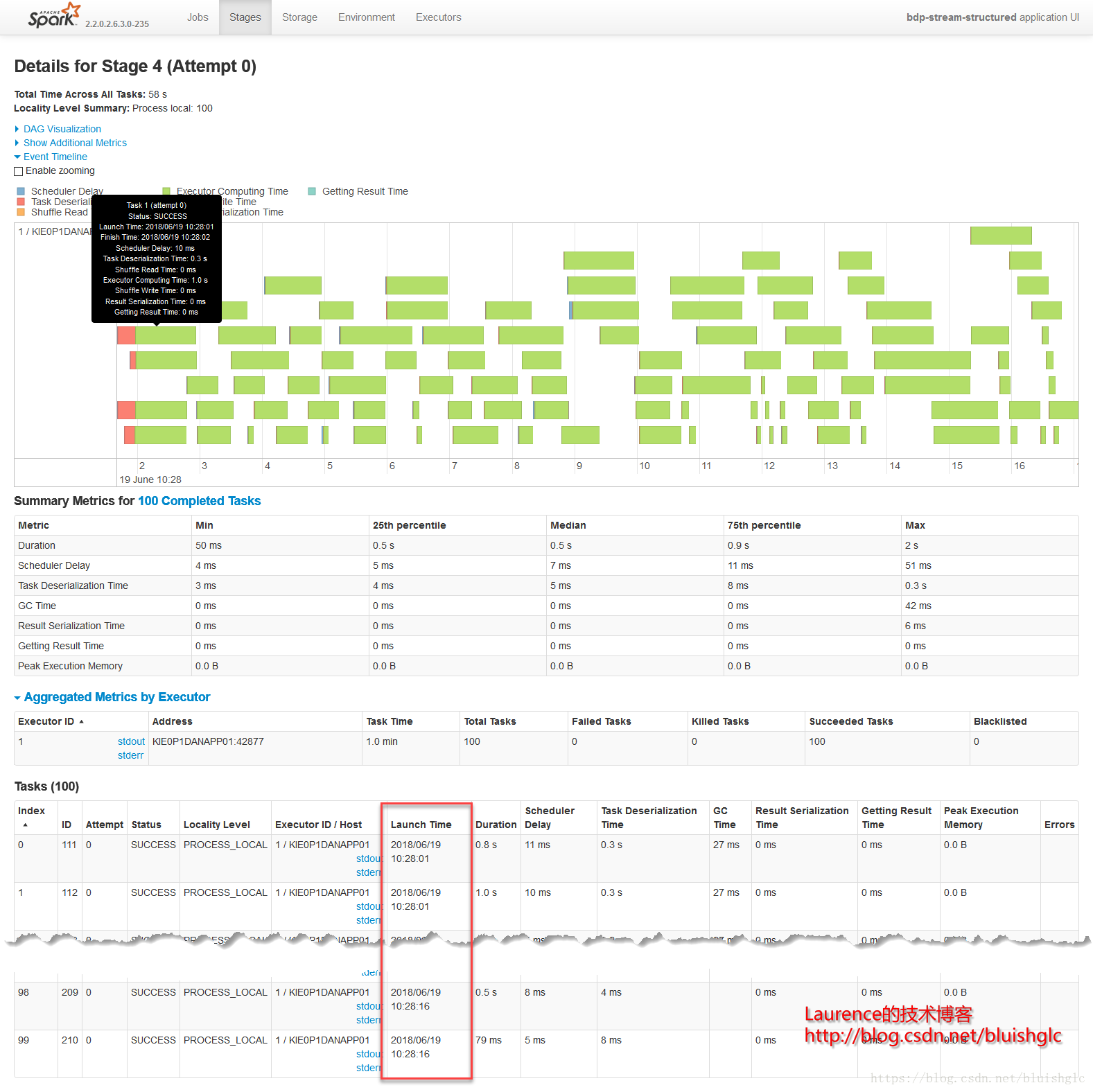
当然,FAIR模式作业运行的一个最基本的“特征”就是一个需要话费长时间完成的长作业会在中途被“打断”,Spark留出资源给到其他的作业去执行,例如本例stage 3和stage 6关系,同样的情况也发生在《Test Case 1-2: FAIR》
Job
Stage 0
- Stage 1
- Stage 2
- Stage 3
- Stage 6
Test Case Group 4: FAIR 4 Slots, concurrentJobs = 1 vs. FAIR 4 Slots, concurrentJobs = 4
Test Case 4-1: FAIR 4 Slots, concurrentJobs = 1
该测试用例就是《Test Case 3-2:FAIR 4 Slots》
Test Case 4-2: FAIR 4 Slots, concurrentJobs = 4
- 配置
spark.num.executors=1
spark.executor.cores=4
spark.streaming.concurrentJobs=4
spark.scheduler.mode=FAIR
spark.sql.shuffle.partitions=100- 结论
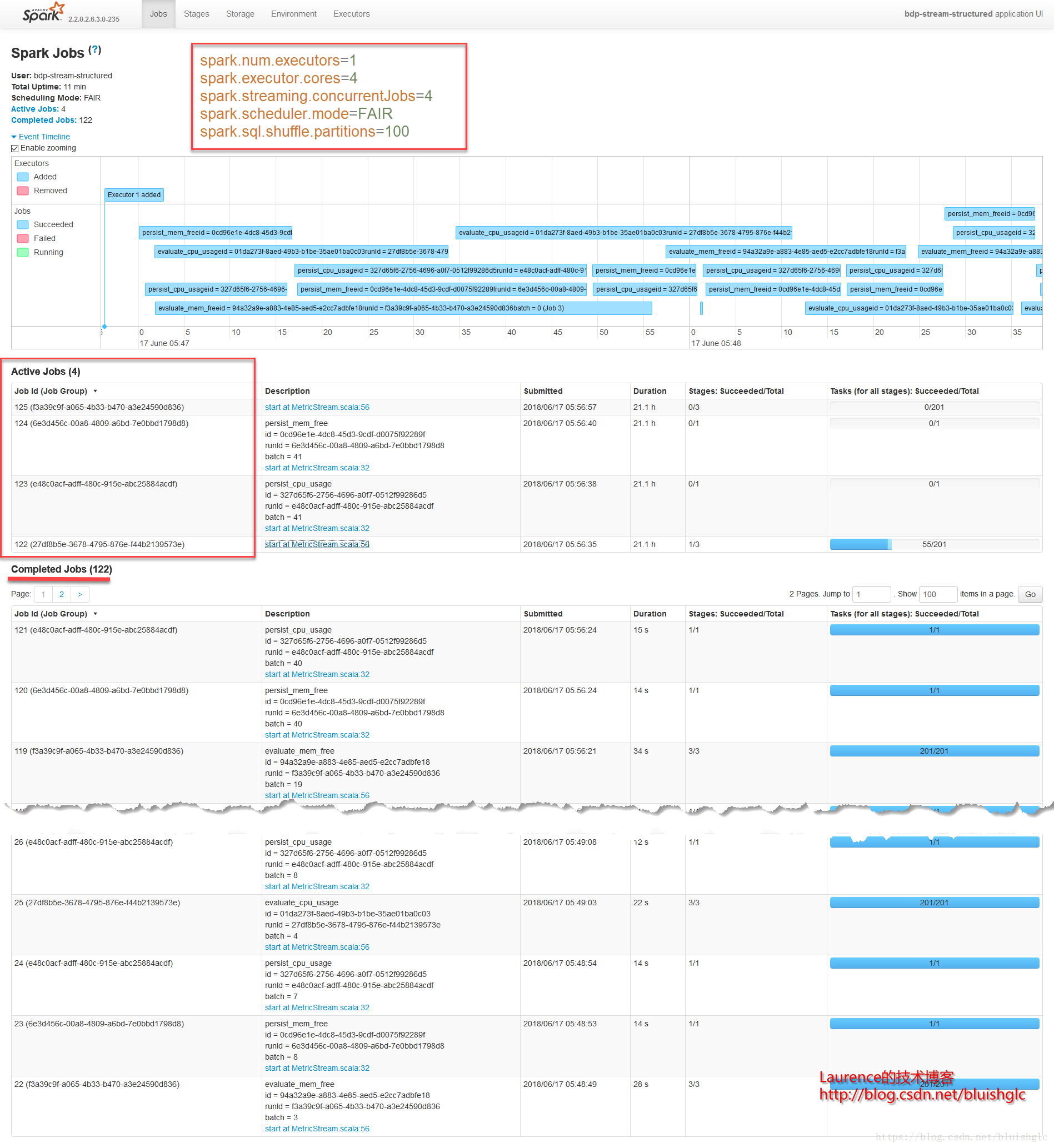
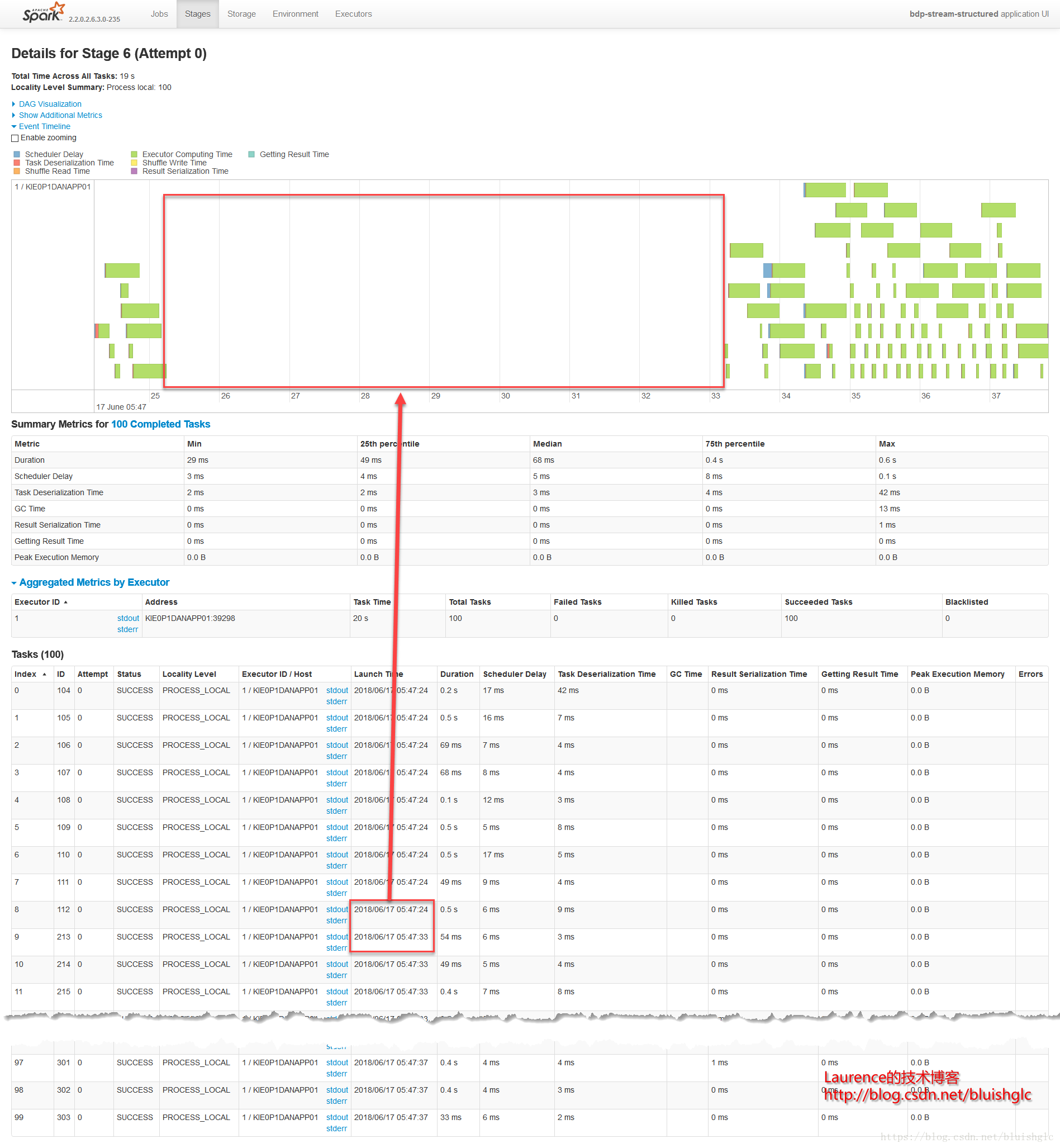
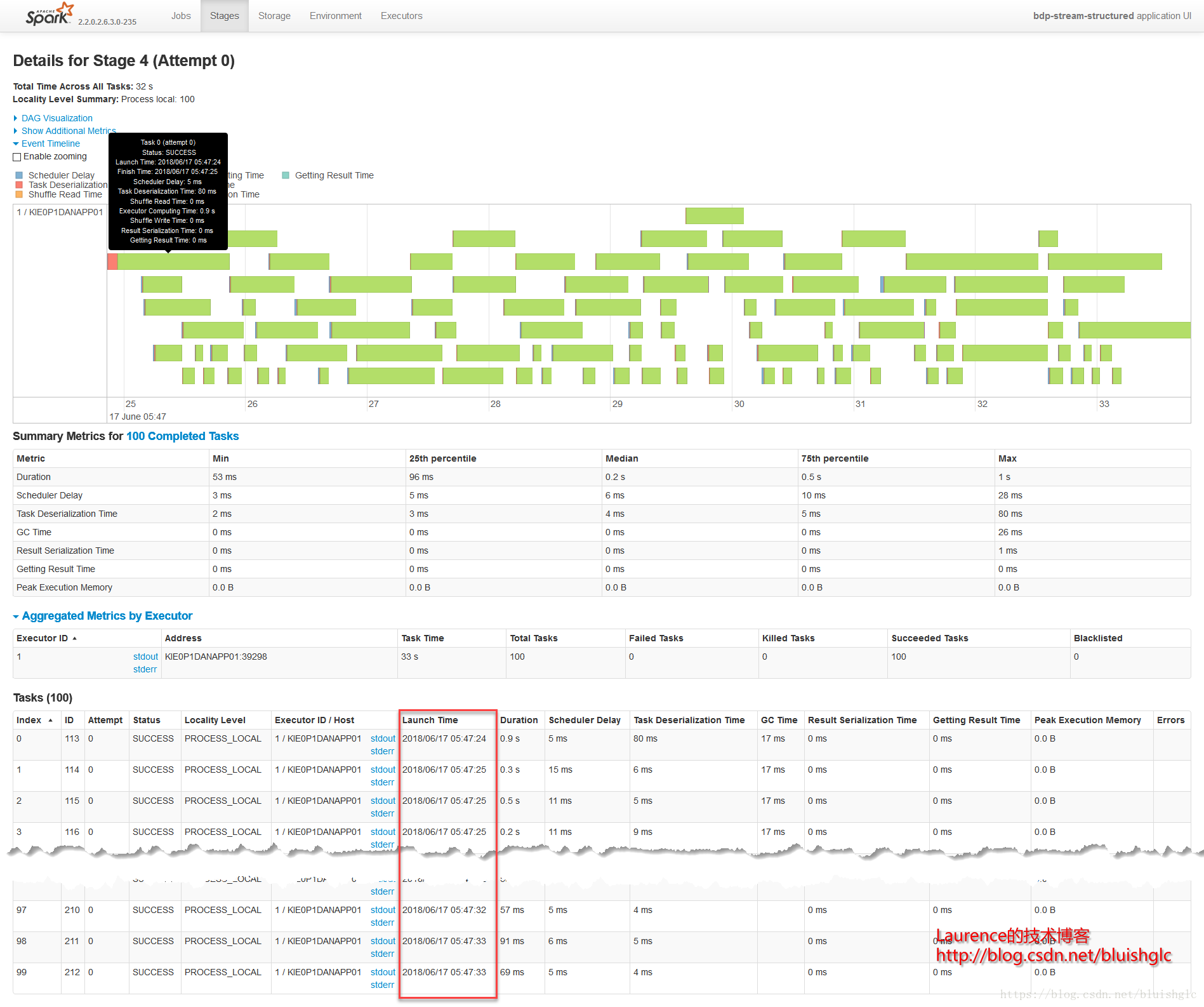
concurrentJobs变为4之后,我们可以在作业视图中观察到有4个Active的作业,顾名思义,concurrentJobs参数的作用就是Spark Streaming允许并行作业的数量,具体到代码层面上就是用来执行作业的线程数。但是,从运行结果上看,可能让人出乎意料:concurrentJobs变为4之后,作业的整个吞吐量没有得到明显的提升!这说明作业执行的瓶颈已不再是并发度了,原因是我们前面所有concurrentJobs=1的测试用例中,配置上是限定了一个并发作业,但是在鉴于部分作业只需要一个core,所以集群中某些时刻总是有空余资源,这时候Spark会启动新的作业,从而让硬件资源充分利用。即使我们在这个测试中人为的把作业并发数改为了4,也不会在整体的资源利用率上有所提升了!
补充说明:
不管是FIFO还FAIR(concurrentJobs=1),某一时刻都是可能存在两上以上的Active Job的!!这是因为只要还有空闲资源,Spark就会激活等待中的作业!它们的Task就会进入到Pool的Task队列里!
- Job
Stage 0
Stage 1
Stage 2
Stage 6
- Stage 4
Test Case Group 5: FAIR 4 Slots, concurrentJobs = 4, Root Pool vs. FAIR 4 Slots, concurrentJobs = 4, Independent Pools
Test Case 5-1: FAIR 4 Slots, concurrentJobs = 4, Root Pool
该测试用例就是《Test Case 4-2: FAIR 4 Slots, concurrentJobs = 4》
Test Case 5-2: FAIR 4 Slots, concurrentJobs = 4, Independent Pools
- 配置
spark.num.executors=1
spark.executor.cores=4
spark.streaming.concurrentJobs=4
spark.scheduler.mode=FAIR
spark.sql.shuffle.partitions=100
//在4个流上都使用了独立的pool:
sparkSession.sparkContext.setLocalProperty("spark.scheduler.pool", s"pool_persist_$metric")
sparkSession.sparkContext.setLocalProperty("spark.scheduler.pool", s"pool_evaluate_$metric")4个独立pool的配置:
<?xml version="1.0"?>
<allocations>
<pool name="pool_persist_cpu_usage">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>0</minShare>
</pool>
<pool name="pool_persist_mem_free">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>0</minShare>
</pool>
<pool name="pool_evaluate_cpu_usage">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>0</minShare>
</pool>
<pool name="pool_evaluate_mem_free">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>0</minShare>
</pool>
</allocations>- 结论
这是变化最剧烈的一个测试用例,也就是意味着spark.scheduler.pool是一个效用非常大的配置项!我们先看一下Job页面,最大的变化是完成的作业数激增到935个!在之前的所有用例里, 四个作业(包含两个短作业:persist_cpu_usage和persist_mem_free以及两个长作业: evaluate_cpu_usage和evaluate_mem_free),无论长短,都是保持1:1:1:1的比例,而在本测试中两个短作业persist_cpu_usage和persist_mem_free的数量明显增多,远远超过了两个长作业数量的N倍!那么造成这一现象的原因是什么呢?关键点就是pool的weight属性!我们来看一下Spark官方文档对pool的weight属性的介绍:
weight: This controls the pool’s share of the cluster relative to other pools. By default, all pools have a weight of 1. If you give a specific pool a weight of 2, for example, it will get 2x more resources as other active pools. Setting a high weight such as 1000 also makes it possible to implement priority between pools—in essence, the weight-1000 pool will always get to launch tasks first whenever it has jobs active.
不难看出:对于多个pool, 它们的weight决定了它们所能分得的硬件资源的“份额”!我们来对比地理解一下这个差别:在前面所有使用FAIR模式的测试用例中,都没有特别地配置pool, 它们都使用同一个默认的root pool, 则在同一个pool内,应用FAIR模式,四个作业得到的是均等的执行机会,因此4个作业完成的比例是1:1:1:1,而在本测试用例中,我们为四个作业配备了独立的pool, 而pool与pool之间是按占有资源的份额划分的,这就变成四个作业获得的执行资源是均等的,这一变化的实质效果就是提升了短作业占有资源的份额!因为之前4个作业是按均等的执行机会分配的,对于那些短作业,它们获得了资源之后,只需要很短的时间就完成了工作,所以宏观上它们实际占用资源的份额并不高,而现在的模式变成了,分配给它们均等的资源,则实质上短作业获得了更多的资源份额,因此完成作业数量就成倍地激增了!
但是这一定是好的吗?这要看我们到底想如何协调长短作业之间的资源竞争关系!因为总的资源就这么多了,分配给了短作业更多的资源就意味了长作业获得的资源别消减了,这可以从长作业完成的数量上得到验证,在本测试用例中,一共完成了28个长作业(evaluate_cpu_usage和evaluate_mem_free),而在前一个对比测试中,完成的长作业数量是122/2=61个,所以总结下来最重点的结论是:pool是从整体计算资源上按份额(weight)进行切分的,在一个pool内部,如果是FAIR模式,则作业是按均等的执行机会来划分的。
- Job