大量I/O请求的累积可能会明显降低系统性能和响应能力。
问题描述
网络调用和I/O操作与生俱来就比计算任务要慢。每个I/O请求通常会产生很高的开销,大量I/O操作的累积可能会使系统变慢。下面是出现琐碎I/O的一些常见原因。
以不同请求形式在数据库中读取和写入单个记录
以下示例从产品数据库中读取数据。有三个表:Product、ProductSubcategory和ProductPriceListHistory。代码通过执行一系列查询来检索子类别中的所有产品以及价格信息:
查询ProductSubcategory表中的子类别。
通过查询Product表来查找该子类别中的所有产品。
对于每个产品,查询ProductPriceListHistory表中的价格数据。
应用程序使用Entity Framework来查询数据库。可在此处找到完整示例。(https://github.com/mspnp/performance-optimization/tree/master/ChattyIO)
此示例揭露了一些问题,但有时如果ORM隐式逐个提取子记录,则可能会掩盖问题。这就是所谓的“N+1问题”。
以一系列HTTP请求的形式执行逻辑操作
当开发人员尝试遵循面向对象的规则,并将远程对象视为内存中的本地对象时,就往往会发生这种情况。这可能导致过多的网络往返。例如,以下WebAPI通过GET方法公开User对象的单个属性。
尽管此方法在技术上没有任何问题,但是,大多数客户端可能需要获取每个User的多个属性,从而导致需要编写如下所示的客户端代码。
读写磁盘文件
文件I/O需要打开某个文件,转移到某个点,然后读取或写入数据。完成该操作后,文件可能会关闭,以节省操作系统资源。持续在文件中读取和写入少量信息的应用程序会产生很高的I/O开销。小规模写入请求还可能导致文件碎片,从而减慢后续I/O操作的速度。
以下示例使用FileStream将Customer对象写入文件。创建FileStream会打开该文件,释放它会关闭该文件。(using 语句自动释放FileStream对象。)如果每次添加新客户应用程序都调用该方法,I/O开销可能会迅速累积。
解决方案
将数据打包并减少请求数从而减少I/O请求的数量。
单次大查询而不是多次小查询的形式从数据库中提取数据。下面是检索产品信息代码的修改版本。
遵循WebAPI的REST设计原则。下面是前一示例中WebAPI的修改版。不要针对每个属性单独使用GET方法,而可使用返回整个User的GET方法。这会导致每个请求的响应正文变得更大,但每个客户端对API调用的次数会减少。
注意事项
前两个示例发出更少的I/O调用,但每个示例检索了更多的信息。必须考虑这两种因素的利弊。正确答案取决于实际应用场景。例如,在WebAPI示例中,客户端可能往往只需检索用户名。在这种情况下,将该操作公开为单独的API调用可能更有利。有关详细信息,请参阅超量提取反模式。(https://docs.microsoft.com/en-us/azure/architecture/antipatterns/extraneous-fetching/index)
读取数据时,不要发过多的I/O请求。应用程序应该只检索它要使用的信息。
有时将对象的信息分区成两个区块可能会有帮助:经常访问的数据(大多数请求就是针对这些数据发出的),不经常访问的数据(极少使用的数据)。最常访问的数据往往是对象总体数据中较小的一部分,因此,只返回这一部分数据能够大幅节省I/O开销。
写入数据时,避免将资源锁定超过必要的时间以减少在执行冗长操作期间发生资源争用的可能。如果写操作跨多个数据存储、文件或服务,则采用最终一致性方法。请参阅数据一致性指南。(http://https//msdn.microsoft.com/library/dn589800.aspx)
如果在写数据之前在内存中缓存数据,发生进程崩溃时,数据可能会丢失。如果数据率经常出现喷发或相对稀疏的情况,在将数据保存在外部队列例如事件中心(https://azure.microsoft.com/en-us/services/event-hubs/)可能会更安全。
考虑对服务或数据库检索的数据做缓存。可以避免针对相同的数据发出重复请求,从而减少I/O。有关详细信息,请参阅有关缓存的最佳实践。(https://docs.microsoft.com/en-us/azure/architecture/best-practices/caching)
如何检测问题
琐碎I/O的症状包括高延迟和低吞吐量。由于I/O资源争用的加剧,最终用户可能会反映响应时间延长,或服务超时而导致失败。可执行以下步骤来帮助确定问题的原因:
对生产系统执行进程监视,识别响应时间不佳的操作。
对上一步骤中识别到的每个操作执行负载测试。
在负载测试期间,收集有关每个操作发出的数据访问请求的遥测数据。
收集每个请求的详细统计信息。
在测试环境中分析应用程序,判定可能出现I/O瓶颈的位置。
确定是否存在以下任何症状:
向同一个文件发出大量的小(数据)I/O请求。
某个应用程序实例向同一个服务发出大量的小型网络请求。
某个应用程序实例向同一个数据存储发出大量的小型请求。
应用程序和服务受I/O约束。
诊断示例
以下部分将这些步骤应用到前面所示的查询数据库示例。
对应用程序进行负载测试
下图显示了负载测试的结果。中间响应时间是根据每个请求在数十秒内的表现测得的。该图显示延迟很高。每加载1000个用户,用户就可能需要等待将近一分钟才能看到查询结果。

备注
该应用程序是作为Azure应用服务的Web应用部署的,使用了AzureSQL数据库。负载测试使用了1000个并发用户来模拟步骤的工作负荷。数据库中配置了支持最多1000个并发连接的连接池,以减少连接争用。
监视应用程序
可使用应用程序性能监视(APM)包来捕获和分析可识别琐碎I/O的关键指标。至于哪些指标比较重要,取决于I/O工作负荷。对于此示例,要关注的I/O请求是数据库查询。
下图显示了使用NewRelic的APM所生成的结果。在承受最大工作负荷期间,数据库的平均响应时间的峰值出现在每个请求的大约5.6秒处。在整个测试过程中,系统能够支持每分钟约410个请求。

收集详细的数据访问信息
对监视数据进行更深入发掘后,应用程序执行了三个不同的SELECT语句。这些语句对应于实体框架从ProductListPriceHistory、Product和ProductSubcategory表中提取数据时生成的请求。此外,从ProductListPriceHistory表中检索数据的查询是到目前为止最频繁执行的SELECT语句,其执行频率高过其他查询一个数量级。

在测试中发现,前面所示的GetProductsInSubCategoryAsync方法执行了45个SELECT查询。每个查询都导致应用程序打开新的SQL连接。

备注
此图显示了负载测试中GetProductsInSubCategoryAsync操作的最缓慢实例的跟踪信息。在生产环境中,有用的做法是检查最缓慢的实例,以确定是否能够找到问题出现的规律。如果只需查看平均值,可能会忽略在承受负载的情况下急剧恶化的问题。
下图显示了实际的SQL语句。提取价格信息的查询是针对产品子类别中的每个产品运行的。使用联接可大幅减少对数据库的调用数。

如果使用EF等ORM,跟踪SQL查询可以洞察ORM如何将程序代码调用转换为SQL语句,并指明可优化的数据访问区域。
实施解决方案并验证结果
对EF调用部分的代码进行重写,再次测试,得到以下结果。
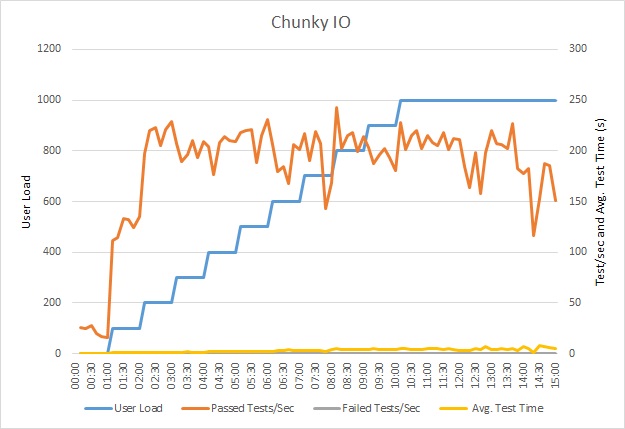
此负载测试是使用相同的负载配置文件在相同的部署上执行的。这一次,图中显示的延迟要低得多。在加载1000个用户的情况下,平均请求时间下降为5至6秒,而前面的测试中为将近一分钟。这一次,系统可支持每分钟平均3,970个请求,而在前面的测试中为410个请求。

跟踪SQL语句后发现,所有数据是在单个SELECT语句中提取的。尽管此查询要复杂得多,但只需为每个操作执行一次。此外,尽管复杂的联接可能会产生较高的开销,但关系型数据库系统已针对此类查询进行了优化。

相关资源
API设计的最佳实践(https://docs.microsoft.com/en-us/azure/architecture/best-practices/api-design)
有关缓存的最佳事件(https://docs.microsoft.com/en-us/azure/architecture/best-practices/caching)
数据一致性入门(http://https//msdn.microsoft.com/library/dn589800.aspx)
超量提取反模式(https://docs.microsoft.com/en-us/azure/architecture/antipatterns/extraneous-fetching/index)
无缓存反模式(https://docs.microsoft.com/en-us/azure/architecture/antipatterns/no-caching/index)
问题描述
网络调用和I/O操作与生俱来就比计算任务要慢。每个I/O请求通常会产生很高的开销,大量I/O操作的累积可能会使系统变慢。下面是出现琐碎I/O的一些常见原因。
以不同请求形式在数据库中读取和写入单个记录
以下示例从产品数据库中读取数据。有三个表:Product、ProductSubcategory和ProductPriceListHistory。代码通过执行一系列查询来检索子类别中的所有产品以及价格信息:
查询ProductSubcategory表中的子类别。
通过查询Product表来查找该子类别中的所有产品。
对于每个产品,查询ProductPriceListHistory表中的价格数据。
应用程序使用Entity Framework来查询数据库。可在此处找到完整示例。(https://github.com/mspnp/performance-optimization/tree/master/ChattyIO)
public async Task<IHttpActionResult> GetProductsInSubCategoryAsync(int subcategoryId)
{
using (var context = GetContext())
{
// Get product subcategory.
var productSubcategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subcategoryId)
.FirstOrDefaultAsync();
// Find products in that category.
productSubcategory.Product = await context.Products
.Where(p => subcategoryId == p.ProductSubcategoryId)
.ToListAsync();
// Find price history for each product.
foreach (var prod in productSubcategory.Product)
{
int productId = prod.ProductId;
var productListPriceHistory = await context.ProductListPriceHistory
.Where(pl => pl.ProductId == productId)
.ToListAsync();
prod.ProductListPriceHistory = productListPriceHistory;
}
return Ok(productSubcategory);
}
}此示例揭露了一些问题,但有时如果ORM隐式逐个提取子记录,则可能会掩盖问题。这就是所谓的“N+1问题”。
以一系列HTTP请求的形式执行逻辑操作
当开发人员尝试遵循面向对象的规则,并将远程对象视为内存中的本地对象时,就往往会发生这种情况。这可能导致过多的网络往返。例如,以下WebAPI通过GET方法公开User对象的单个属性。
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}/username")]
public HttpResponseMessage GetUserName(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/gender")]
public HttpResponseMessage GetGender(int id)
{
...
}
[HttpGet]
[Route("users/{id:int}/dateofbirth")]
public HttpResponseMessage GetDateOfBirth(int id)
{
...
}
}尽管此方法在技术上没有任何问题,但是,大多数客户端可能需要获取每个User的多个属性,从而导致需要编写如下所示的客户端代码。
HttpResponseMessage response = await client.GetAsync("users/1/username");
response.EnsureSuccessStatusCode();
var userName = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/gender");
response.EnsureSuccessStatusCode();
var gender = await response.Content.ReadAsStringAsync();
response = await client.GetAsync("users/1/dateofbirth");
response.EnsureSuccessStatusCode();
var dob = await response.Content.ReadAsStringAsync();读写磁盘文件
文件I/O需要打开某个文件,转移到某个点,然后读取或写入数据。完成该操作后,文件可能会关闭,以节省操作系统资源。持续在文件中读取和写入少量信息的应用程序会产生很高的I/O开销。小规模写入请求还可能导致文件碎片,从而减慢后续I/O操作的速度。
以下示例使用FileStream将Customer对象写入文件。创建FileStream会打开该文件,释放它会关闭该文件。(using 语句自动释放FileStream对象。)如果每次添加新客户应用程序都调用该方法,I/O开销可能会迅速累积。
private async Task SaveCustomerToFileAsync(Customer cust)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
byte [] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, cust);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}解决方案
将数据打包并减少请求数从而减少I/O请求的数量。
单次大查询而不是多次小查询的形式从数据库中提取数据。下面是检索产品信息代码的修改版本。
public async Task<IHttpActionResult> GetProductCategoryDetailsAsync(int subCategoryId)
{
using (var context = GetContext())
{
var subCategory = await context.ProductSubcategories
.Where(psc => psc.ProductSubcategoryId == subCategoryId)
.Include("Product.ProductListPriceHistory")
.FirstOrDefaultAsync();
if (subCategory == null)
return NotFound();
return Ok(subCategory);
}
}遵循WebAPI的REST设计原则。下面是前一示例中WebAPI的修改版。不要针对每个属性单独使用GET方法,而可使用返回整个User的GET方法。这会导致每个请求的响应正文变得更大,但每个客户端对API调用的次数会减少。
public class UserController : ApiController
{
[HttpGet]
[Route("users/{id:int}")]
public HttpResponseMessage GetUser(int id)
{
...
}
}
// Client code
HttpResponseMessage response = await client.GetAsync("users/1");
response.EnsureSuccessStatusCode();
var user = await response.Content.ReadAsStringAsync();// Save a list of customer objects to a file
private async Task SaveCustomerListToFileAsync(List<Customer> customers)
{
using (Stream fileStream = new FileStream(CustomersFileName, FileMode.Append))
{
BinaryFormatter formatter = new BinaryFormatter();
foreach (var cust in customers)
{
byte[] data = null;
using (MemoryStream memStream = new MemoryStream())
{
formatter.Serialize(memStream, cust);
data = memStream.ToArray();
}
await fileStream.WriteAsync(data, 0, data.Length);
}
}
}
// In-memory buffer for customers.
List<Customer> customers = new List<Customers>();
// Create a new customer and add it to the buffer
var cust = new Customer(...);
customers.Add(cust);
// Add more customers to the list as they are created
...
// Save the contents of the list, writing all customers in a single operation
await SaveCustomerListToFileAsync(customers);注意事项
前两个示例发出更少的I/O调用,但每个示例检索了更多的信息。必须考虑这两种因素的利弊。正确答案取决于实际应用场景。例如,在WebAPI示例中,客户端可能往往只需检索用户名。在这种情况下,将该操作公开为单独的API调用可能更有利。有关详细信息,请参阅超量提取反模式。(https://docs.microsoft.com/en-us/azure/architecture/antipatterns/extraneous-fetching/index)
读取数据时,不要发过多的I/O请求。应用程序应该只检索它要使用的信息。
有时将对象的信息分区成两个区块可能会有帮助:经常访问的数据(大多数请求就是针对这些数据发出的),不经常访问的数据(极少使用的数据)。最常访问的数据往往是对象总体数据中较小的一部分,因此,只返回这一部分数据能够大幅节省I/O开销。
写入数据时,避免将资源锁定超过必要的时间以减少在执行冗长操作期间发生资源争用的可能。如果写操作跨多个数据存储、文件或服务,则采用最终一致性方法。请参阅数据一致性指南。(http://https//msdn.microsoft.com/library/dn589800.aspx)
如果在写数据之前在内存中缓存数据,发生进程崩溃时,数据可能会丢失。如果数据率经常出现喷发或相对稀疏的情况,在将数据保存在外部队列例如事件中心(https://azure.microsoft.com/en-us/services/event-hubs/)可能会更安全。
考虑对服务或数据库检索的数据做缓存。可以避免针对相同的数据发出重复请求,从而减少I/O。有关详细信息,请参阅有关缓存的最佳实践。(https://docs.microsoft.com/en-us/azure/architecture/best-practices/caching)
如何检测问题
琐碎I/O的症状包括高延迟和低吞吐量。由于I/O资源争用的加剧,最终用户可能会反映响应时间延长,或服务超时而导致失败。可执行以下步骤来帮助确定问题的原因:
对生产系统执行进程监视,识别响应时间不佳的操作。
对上一步骤中识别到的每个操作执行负载测试。
在负载测试期间,收集有关每个操作发出的数据访问请求的遥测数据。
收集每个请求的详细统计信息。
在测试环境中分析应用程序,判定可能出现I/O瓶颈的位置。
确定是否存在以下任何症状:
向同一个文件发出大量的小(数据)I/O请求。
某个应用程序实例向同一个服务发出大量的小型网络请求。
某个应用程序实例向同一个数据存储发出大量的小型请求。
应用程序和服务受I/O约束。
诊断示例
以下部分将这些步骤应用到前面所示的查询数据库示例。
对应用程序进行负载测试
下图显示了负载测试的结果。中间响应时间是根据每个请求在数十秒内的表现测得的。该图显示延迟很高。每加载1000个用户,用户就可能需要等待将近一分钟才能看到查询结果。
备注
该应用程序是作为Azure应用服务的Web应用部署的,使用了AzureSQL数据库。负载测试使用了1000个并发用户来模拟步骤的工作负荷。数据库中配置了支持最多1000个并发连接的连接池,以减少连接争用。
监视应用程序
可使用应用程序性能监视(APM)包来捕获和分析可识别琐碎I/O的关键指标。至于哪些指标比较重要,取决于I/O工作负荷。对于此示例,要关注的I/O请求是数据库查询。
下图显示了使用NewRelic的APM所生成的结果。在承受最大工作负荷期间,数据库的平均响应时间的峰值出现在每个请求的大约5.6秒处。在整个测试过程中,系统能够支持每分钟约410个请求。
收集详细的数据访问信息
对监视数据进行更深入发掘后,应用程序执行了三个不同的SELECT语句。这些语句对应于实体框架从ProductListPriceHistory、Product和ProductSubcategory表中提取数据时生成的请求。此外,从ProductListPriceHistory表中检索数据的查询是到目前为止最频繁执行的SELECT语句,其执行频率高过其他查询一个数量级。
在测试中发现,前面所示的GetProductsInSubCategoryAsync方法执行了45个SELECT查询。每个查询都导致应用程序打开新的SQL连接。
备注
此图显示了负载测试中GetProductsInSubCategoryAsync操作的最缓慢实例的跟踪信息。在生产环境中,有用的做法是检查最缓慢的实例,以确定是否能够找到问题出现的规律。如果只需查看平均值,可能会忽略在承受负载的情况下急剧恶化的问题。
下图显示了实际的SQL语句。提取价格信息的查询是针对产品子类别中的每个产品运行的。使用联接可大幅减少对数据库的调用数。
如果使用EF等ORM,跟踪SQL查询可以洞察ORM如何将程序代码调用转换为SQL语句,并指明可优化的数据访问区域。
实施解决方案并验证结果
对EF调用部分的代码进行重写,再次测试,得到以下结果。
此负载测试是使用相同的负载配置文件在相同的部署上执行的。这一次,图中显示的延迟要低得多。在加载1000个用户的情况下,平均请求时间下降为5至6秒,而前面的测试中为将近一分钟。这一次,系统可支持每分钟平均3,970个请求,而在前面的测试中为410个请求。
跟踪SQL语句后发现,所有数据是在单个SELECT语句中提取的。尽管此查询要复杂得多,但只需为每个操作执行一次。此外,尽管复杂的联接可能会产生较高的开销,但关系型数据库系统已针对此类查询进行了优化。
相关资源
API设计的最佳实践(https://docs.microsoft.com/en-us/azure/architecture/best-practices/api-design)
有关缓存的最佳事件(https://docs.microsoft.com/en-us/azure/architecture/best-practices/caching)
数据一致性入门(http://https//msdn.microsoft.com/library/dn589800.aspx)
超量提取反模式(https://docs.microsoft.com/en-us/azure/architecture/antipatterns/extraneous-fetching/index)
无缓存反模式(https://docs.microsoft.com/en-us/azure/architecture/antipatterns/no-caching/index)