自动完形填空系统构建要求
问题描述
在语义连贯的句子中去掉一个词语,形成空格,要求在给出的对应备选答案中,系统自动选出一个最佳的答案,使语句恢复完整。
相关语料
1、 Training data:未标注训练语料,供同学选择使用。同学也可根据需要自行选择其他语料,但需要在在实验报告中注明所使用训练语料的规模、来源及性质。
2、 Development set:
提供一份含有 240 句话的语料及答案,供同学自行测试结果,根据结果调整优化自己的算法。
3、 Test set:
提供一份含有 800 句话的测试语料,每句话有一个空格和 5 个备选答案。该语料不提供答案,同学提交测试结果,由助教统一评测。
评测方法
准确率=正确填空句子的个数/全部句子的个数
题目要求
要求同学根据自己设计训练得到的系统,对测试语料进行预测,对每句话提供一个系统认为正确的选项。
本作业无统一标准方法,同学可自行设计模型,鼓励同学积极创新。
提示:模型的构建可以简单也可以复杂。例如,可以基于 n 元模型建立一个朴素的系统;也可以引入词性、句法树等;也可以使用神经网络等其他方法;可以使用自行搜集到的词典或者规则作为辅助。当然不限于这些方法,鼓励创新。
作业要求
1、可分组进行,但每个小组的规模不能超过 2 人(即≤ 2)
2、实现相关程序,可用 c/c++、Python 以及 java 语言完成。可参考网上源代码,但必须重新实现,要求程序代码完整,有必要的说明文档和 Makefile 等文件;
3、提供测试语料的预测结果,输出文件以“题目号+选项+英文单词”形式输出,中间用空格或制表符间隔,每个答案占一行。例如:
1 choice1 answer1
...... ......
...... ......
800 choice 800 answer800
4、撰写实验报告以及 PPT。实验报告以小论文的形式,要有必要的参考文献等信息,将使用的方法讲解清楚;PPT 用于在课堂上报告实验成果;
5、将预测答案、实验报告、PPT 及源程序提交到助教用以评分。
自动完形填空系统构建实验报告
第一章 基于n元模型构建的朴素系统
1.1 问题描述
在语义连贯的句子中去掉一个词语,形成空格,每个空格有5个备选答案,要求在给出的对应备选答案中,系统自动选出一个最佳的答案,使语句恢复完整。
1.2 系统分析
n元模型中,一个词的出现只与它的前n-1个词有关。填空题的句子只有一个空格,设空格在句子中的位置为i,则i-2,i-1,i+1位置上的三个词对于空格处应填词语十分重要。因此,本系统采用2元模型与3元模型相结合的办法。
1.3 系统设计与实现
系统可分为训练数据、保存训练数据、选择答案、保存结果等部分。其大致流程如图1.1所示。
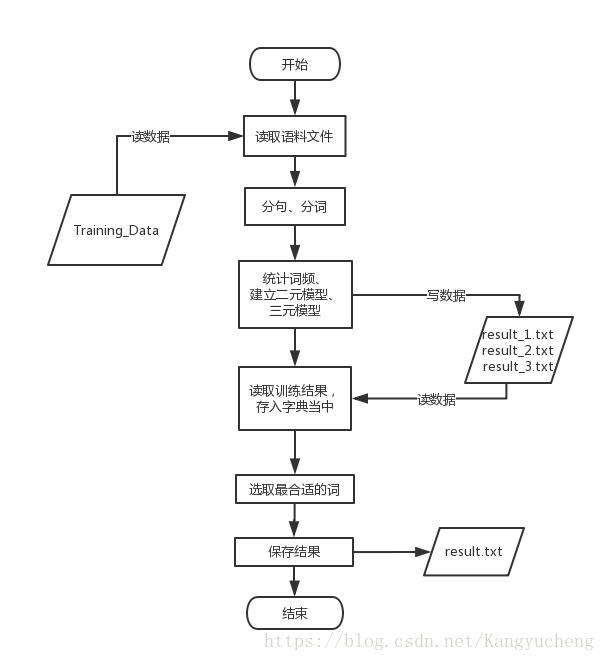
图1.1 系统流程图
1.3.1读取数据集
将词频、二元模型、三元模型的统计结果存储到字典当中,字典的key代表词和词组,字典的value代表在语料中出现的次数,将字典分别写入三个文件当中。统计结果如图1.2所示。
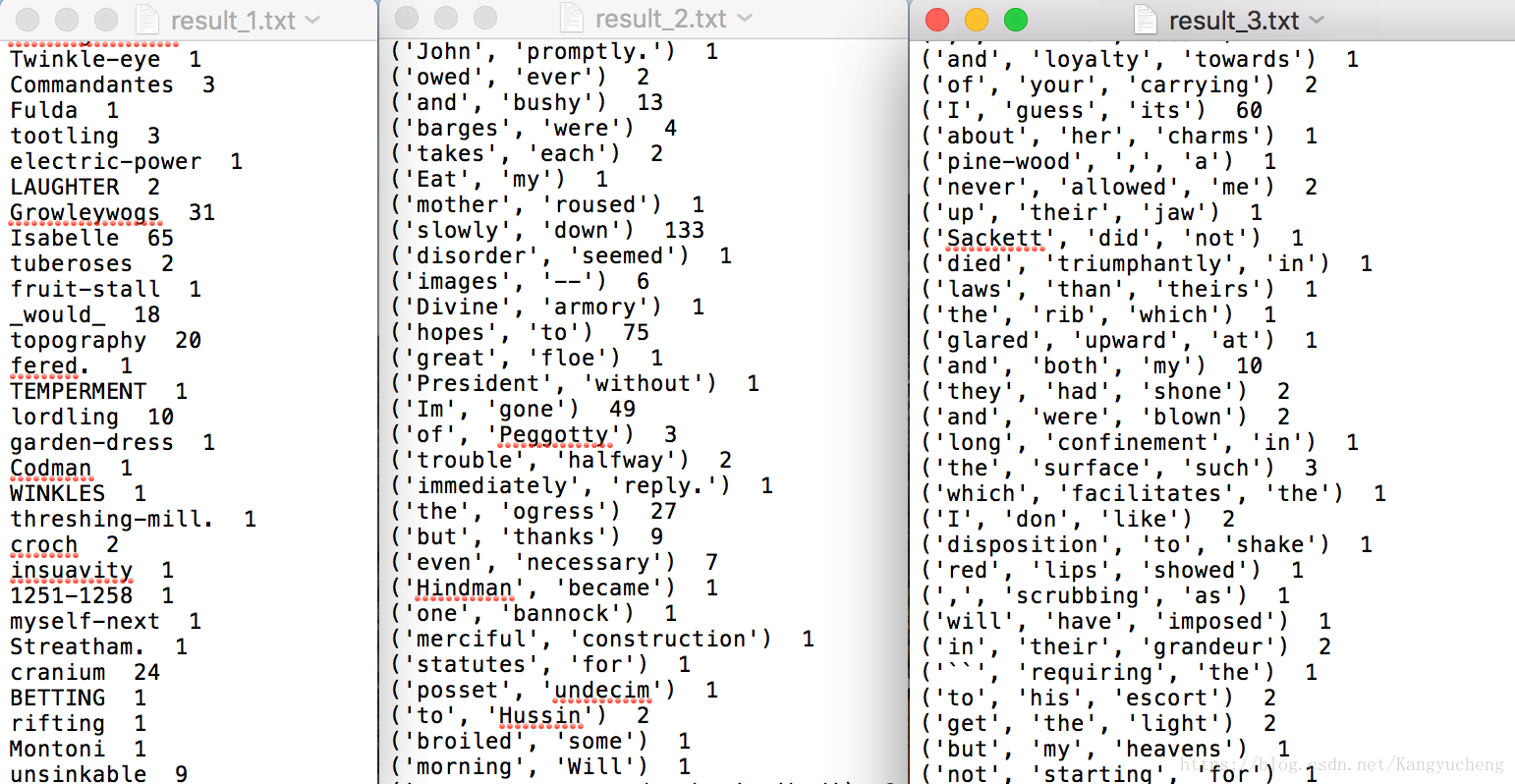
图1.2 统计结果
1.3.2 读取数据集
在训练好数据集之后,将上一步写好的文件读出来,存到字典当中,字典的key代表词和词组,字典的value代表在语料中出现的次数。
1.3.3 选择答案
每一道题分成题目和选项两部分,针对每个选项计算四个参数,计算过程如图1.3所示。根据四个概率相关的参数,选择最佳答案。选择过程如图1.4所示。

图1.3 计算过程
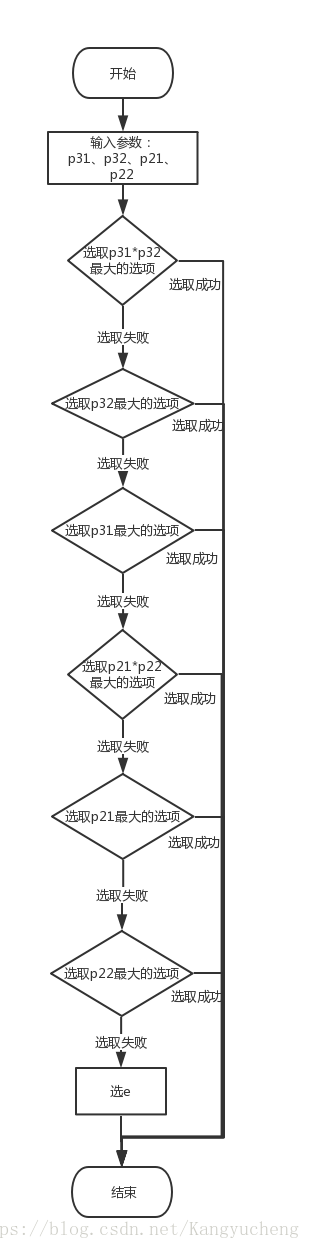
图1.4 参数选择过程
1.4 实验过程与结果
1.4.1 实验过程
首先配置python2.7,安装pip,按照官网提示安装nltk,在pycharm中创建工程,并将数据集和测试集放在工程的目录下,创建mynlp.py文件开始编码,结果如图1.5所示
图1.5 编码结果
1.4.2 实验结果
运行mynlp.py文件,分别得到相关的文件结果。创建test.py,将计算结果与正确答案进行比较。比较结果如图1.6所示,正确率可达到30%。

图1.6 测试结果
源码
# encoding=utf-8
from nltk.util import ngrams
from nltk import word_tokenize
from nltk import sent_tokenize
import os
class mynlp:
training_data_path = 'Training_Data' # 该文件夹下存储着所有的训练数据
test_data_path = 'Test_Data/development_set.txt' # 该文件存储着用于开发的测试文档
result_file_path = 'result.txt' # 发送给助教的结果
#test_data_path = 'Test_Data/test_set.txt'
training_gram1_res = {} # 存储一元模型的结果(词频)
training_gram2_res = {} # 存储二元模型的结果
training_gram3_res = {} # 存储三元模型的结果
result_list = [] # 存储计算结果
def __init__(self):
self.start()
def start(self):
# 第一步,读取数据集,将词频、二元模型、三元模型存储到字典当中,将元组写入一个文件当中,训练一次后可注释掉
# self.train_data()
# 第二步,将写好的文件读出来,存到字典当中,(an,apple) : 2
self.read_from_training()
# 第三步,针对每一道题,将每个答案放到句子中,计算这个词和前一个词与后一个词分别的2元模型,选取概率最大的那个
self.select_result()
# 第四步,将结果写入文件,发给助教
self.write_result()
def train_data(self):
datafiles = os.listdir(self.training_data_path)
for i in datafiles:
filename = self.training_data_path+'/'+i
f = open(filename)
data = self.clear_string(str(f.readlines()))
data_sent = sent_tokenize(data)
for j in data_sent:
data_words = word_tokenize(j)
# 训练一元组,求频率
for t in data_words:
# t = self.clear_string(t)
if t in self.training_gram1_res:
self.training_gram1_res[t] += 1
else:
self.training_gram1_res[t] = 1
# 训练二元组
training_gen = ngrams(data_words, 2)
for k in training_gen:
# k = self.clear_string(k)
if k in self.training_gram2_res:
self.training_gram2_res[k] += 1
else:
self.training_gram2_res[k] = 1
# 训练三元组
training_gen = ngrams(data_words, 3)
for b in training_gen:
# b = self.clear_string(b)
if b in self.training_gram3_res:
self.training_gram3_res[b] += 1
else:
self.training_gram3_res[b] = 1
f.close()
result_file1 = open('result_1.txt', 'w')
for i in self.training_gram1_res:
result_file1.writelines(str(i)+' '+str(self.training_gram1_res[i])+'\n')
result_file1.close()
result_file2 = open('result_2.txt', 'w')
for i in self.training_gram2_res:
result_file2.writelines(str(i)+' '+str(self.training_gram2_res[i])+'\n')
result_file2.close()
result_file3 = open('result_3.txt', 'w')
for i in self.training_gram3_res:
result_file3.writelines(str(i)+' '+str(self.training_gram3_res[i])+'\n')
result_file3.close()
def clear_string(self, s):
if len(s) > 1:
return s.replace('\\r', '').replace('\\n', '').replace('\\', '').replace("'", "").replace("`", "")
else:
return s
def read_from_training(self):
read_file1 = open('result_1.txt', 'r')
for i in read_file1:
read_gram_key = i.split(" ")[0]
read_gram_num = int(i.split(" ")[1].replace('\n', ''))
self.training_gram1_res[read_gram_key] = read_gram_num
read_file1.close()
read_file2 = open('result_2.txt', 'r')
for i in read_file2:
read_gram_key = i.split(" ")[0]
read_gram_num = int(i.split(" ")[1].replace('\n', ''))
self.training_gram2_res[read_gram_key] = read_gram_num
read_file2.close()
read_file3 = open('result_3.txt', 'r')
for i in read_file3:
read_gram_key = i.split(" ")[0]
read_gram_num = int(i.split(" ")[1].replace('\n', ''))
self.training_gram3_res[read_gram_key] = read_gram_num
read_file3.close()
def select_result(self):
test_file = open(self.test_data_path, 'r').readlines()
index = 0
while index < len(test_file):
question = test_file[index]
choices = {}
for l in range(5):
k = test_file[index+l+1].split()[0]
v = test_file[index+l+1].split()[1]
choices[k] = v
result = self.get_best_choice(question, choices)
# print result
self.result_list.append(result)
index += 8
def get_best_choice(self,question,choices):
result = []
q = question.split()
question_num = q[0]
space = q.index('_____')
pre_pre = q[space-2]
pre = q[space-1]
nex = q[space+1]
for c in choices:
p31 = self.get_p3(pre_pre,pre,choices[c])
p32 = self.get_p3(pre,choices[c],nex)
p21 = self.get_p2(pre,choices[c])
p22 = self.get_p2(choices[c],nex)
l = [c,p31,p32,p21,p22]
result.append(l)
find = False
# print question_num
max_choice = ''
#第一步,选出p32*p31最大的
max_p32_mul_p31 = float(0)
for i in range(5):
if result[i][1] * result[i][2] > max_p32_mul_p31:
max_p32_mul_p31 = result[i][1] * result[i][2]
max_choice = result[i][0]
find = True
# print 'p32*p31'
# 第二步,如果第一步没选出来,选出p32最大的
max_p32 = float(0)
if not find:
for i in range(5):
if result[i][2] > max_p32:
max_p32 = result[i][2]
max_choice = result[i][0]
find = True
# print 'p32'
if max_p32 < 0.0005:
find = False
# 第三步,如果第一、二步没选出来,选出p31最大的
max_p31 = float(0)
if not find:
for i in range(5):
if result[i][1] > max_p31:
max_p31 = result[i][1]
max_choice = result[i][0]
find = True
# print 'p31'
if max_p31 < 0.0005:
find = False
# 第四步,如果第一、二、三步没选出来,选出p21*p12最大的
max_p21_mul_p12 = float(0)
if not find:
for i in range(5):
if result[i][3]*result[i][4] > max_p21_mul_p12:
max_p21_mul_p12 = result[i][3]*result[i][4]
max_choice = result[i][0]
find = True
# print 'p2*p1'
# 第五步,如果第一、二、三、四步没选出来,选出p21最大的
max_p21 = float(0)
if not find:
for i in range(5):
if result[i][3] > max_p21:
max_p21 = result[i][3]
max_choice = result[i][0]
find = True
# print 'p21'
# 第六步,如果第一、二、三、四、五步没选出来,选出p22最大的
max_p22 = float(0)
if not find:
for i in range(5):
if result[i][4] > max_p22:
max_p22 = result[i][4]
max_choice = result[i][0]
find = True
# print 'p22'
# 第七步,如果第一、二、三、四、五、六步没选出来,选e
if not find:
max_choice = 'e)'
# print 'e'
return question_num+' ['+max_choice.replace(')','')+'] '+str(choices[max_choice])
def get_p3(self, pre, mid, nex):
c = float(0)
k3 = "('"+pre+"', '"+mid+"', '"+nex+"')"
k2 = "('"+pre+"', '"+mid+"')"
if k3 in self.training_gram3_res:
c = float(self.training_gram3_res[k3])/float(self.training_gram2_res[k2])
return c
def get_p2(self, v1, v2):
c = float(0)
k = "('"+v1+"', '"+v2+"')"
if k in self.training_gram2_res:
c = float(self.training_gram2_res[k])/float(self.training_gram1_res[v1])
else:
if v1 in self.training_gram1_res:
c = float(0.5)/float(self.training_gram1_res[v1])
else:
pass
return c
def write_result(self):
result_file = open(self.result_file_path, 'w')
for i in self.result_list:
result_file.writelines(i+'\n')
result_file.close()
if __name__ == '__main__':
mynlp()
测试正确率源代码
# encoding=utf-8
l1=[]
l2=[]
file = open('result.txt')
for i in file:
l1.append(i)
file.close()
file1 = open('Test_Data/development_set_answers.txt')
for i in file1:
l2.append(i)
file1.close()
c = 0
for i in range(len(l1)):
if l1[i] == l2[i]:
c += 1
# c 代表正确的数目
print '结果:正确数目:'+str(c)+' 总共题目:'+str(len(l1))+' 正确率:'+str(float(c)/float(len(l1)))完整项目
https://download.csdn.net/download/kangyucheng/10504044