上一篇,展示了一个简单的WordCount程序,但是总是使用命令行来操作有些繁琐。
接下来将分享如何使用Eclipse来搭建hadoop开发环境。
开发环境:
系统:window7
IDE:Eclipse Java EE IDE for Web Developers【Version: Juno Service Release 2】
Hadoop版本:hadoop2.5.2
准备工作
- 下载hadoop2.5.2.tar.gz(如果从前两篇文章传送过来的就可以免这步操作。)
- 下载hadoop-eclipse-plugin-2.5.2.jar插件。如果你的hadoop步是这个版本的,请自己动手编译插件,教程戳这
一、解压安装hadoop2.5.2.tar.gz,并配置相关文件。
具体我就不说了,可以戳这看教程。【教你Windows平台安装配置Hadoop2.5.2(不借助cygwin)】
二、安装插件
将hadoop-eclipse-plugin-2.5.2.jar,复制到eclipse安装目录下的plugins下。如:D:\eclipse4\plugins
重启Eclipse。
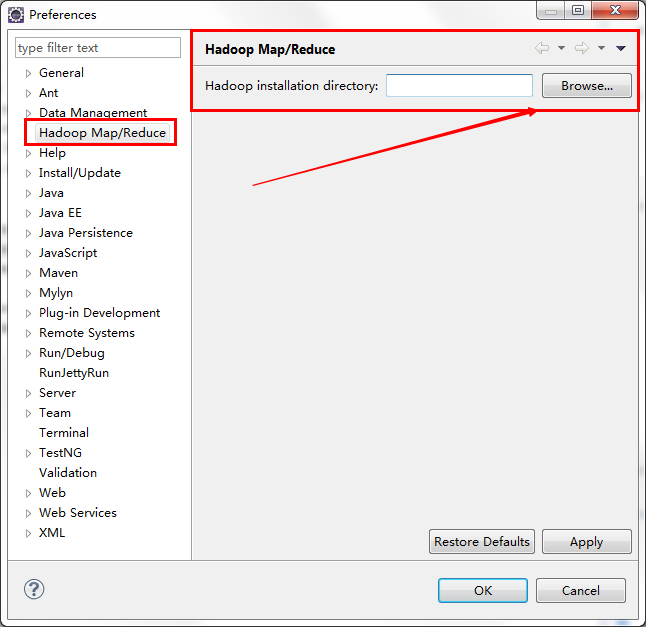
点击菜单栏Windows–>Preferences ,如果插件安装成功,就会出现如下图
【如果插件安装不成功,可能是因为plugin版本的问题,或者是Eclipse未刷新插件,可以自行百度解决。】
选择,hadoop安装目录,如:D:\dev\hadoop-2.5.2
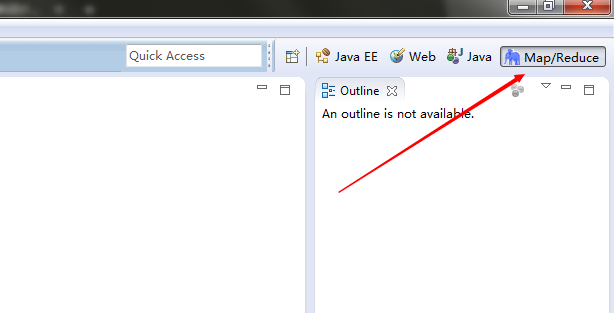
点击Windows–> Show View –> Others –> Map/Redure Location 。 然后点击右上角Map/Redure切换视图。
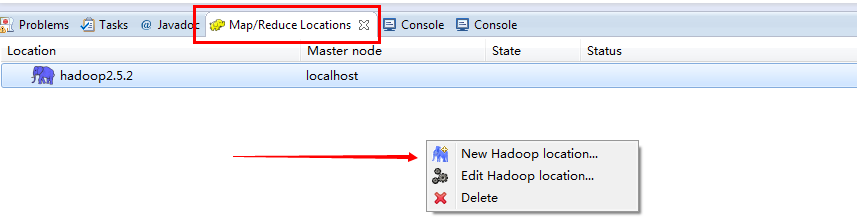
点击下方Map/Redure Locations 窗口,空白处右键New Hadoop location
填写参数,连接参数

连接成功后,如图所示。
三、 编写测试类,依旧是WordCount.java
- 创建Map/Redure Project,右键 –> New –> Other –> Map/Redure Project 。
WordCount.java
package test;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* Hadoop - 统计文件单词出现频次
* @author antgan
*
*/
public class WordCount {
public static class WordCountMap extends
Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCount.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
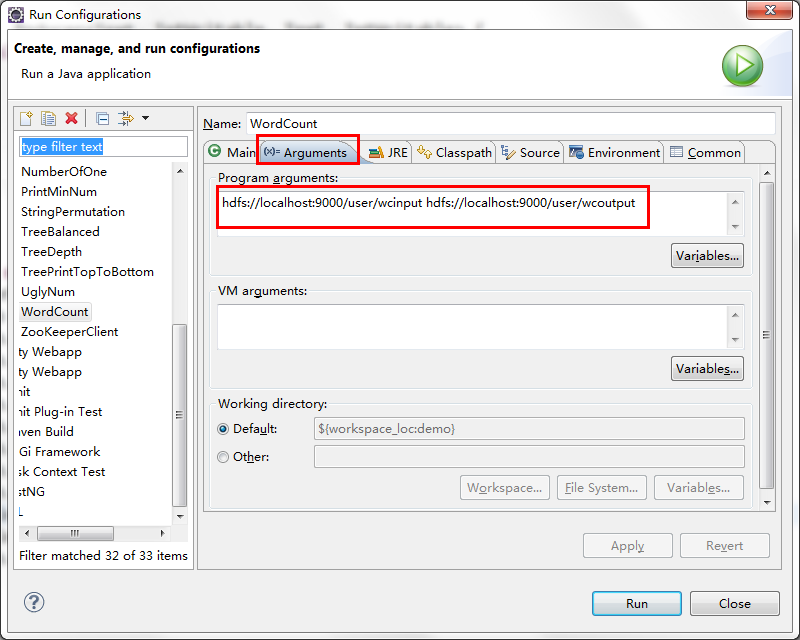
点击WordCount类,右键Run As –> Run Configurations ,点击Arguments,填写输入目录,输出目录参数。
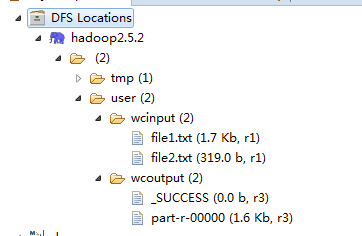
运行。Run,刷新Reflash,输出结果如下图。
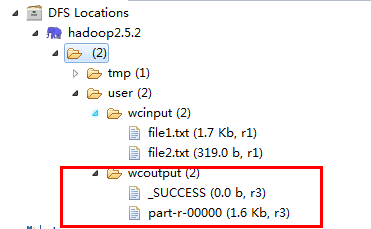
大功告成
我正在学习hadoop平台,如果你也是,可以评论留下QQ,我加你,一起交流下学习心得~