| ylbtech-Java-Zipkin:Zipkin 介绍 |
| 1.返回顶部 |
介绍
Zipkin 是一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于 Google Dapper 的论文设计而来,由 Twitter公司开发贡献。其主要功能是聚集来自各个异构系统的实时监控数据,用来追踪微服务架构下的系统延时问题。应用系统需要进行装备(instrument)以向 Zipkin 报告数据。Zipkin 的用户界面可以呈现一幅关联图表,以显示有多少被追踪的请求通过了每一层应用。Zipkin 以 Trace 结构表示对一次请求的追踪,又把每个 Trace 拆分为若干个有依赖关系的 Span。在微服务架构中,一次用户请求可能会由后台若干个服务负责处理,那么每个处理请求的服务就可以理解为一个 Span(可以包括 API 服务,缓存服务,数据库服务以及报表服务等)。当然这个服务也可能继续请求其他的服务,因此 Span 是一个树形结构,以体现服务之间的调用关系。Zipkin 的用户界面除了可以查看 Span 的依赖关系之外,还以瀑布图的形式显示了每个 Span 的耗时情况,可以一目了然的看到各个服务的性能状况。打开每个 Span,还有更详细的数据以键值对的形式呈现,而且这些数据可以在装备应用的时候自行添加。
架构
zipkin结构
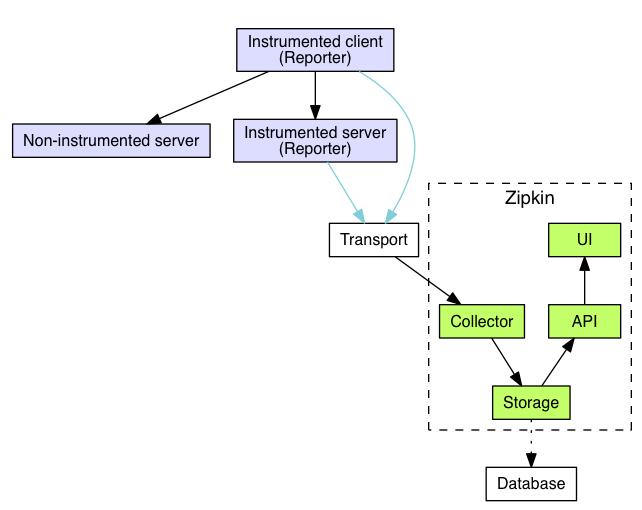
可以看到zipkin内部主要分为四部分:collector、storage、api、ui
collector:负责将各系统报告过来的追踪数据进行接收
storage:默认使用Cassandra存储数据,也可以替换为其他存储,例如mysql5.6-5.7,ElasticSearch 2.x和5.x,还有一些第三方的存储
api:查询服务用来向其他服务提供数据查询的能力,是以json api格式提供
ui:Web服务是官方默认提供的一个图形用户界面
transport
transport负责从运输从service收集来的spans,并把这些spans转化为zipkin的通用span,并将其传递到存储层,这种方法是模块化的,允许任何生产者接收任何类型的数据,zipkin配有HTTP、kafka、scribe三种类型的transport。instrumentations负责和transport进行交互。
instrumentations
官方维护
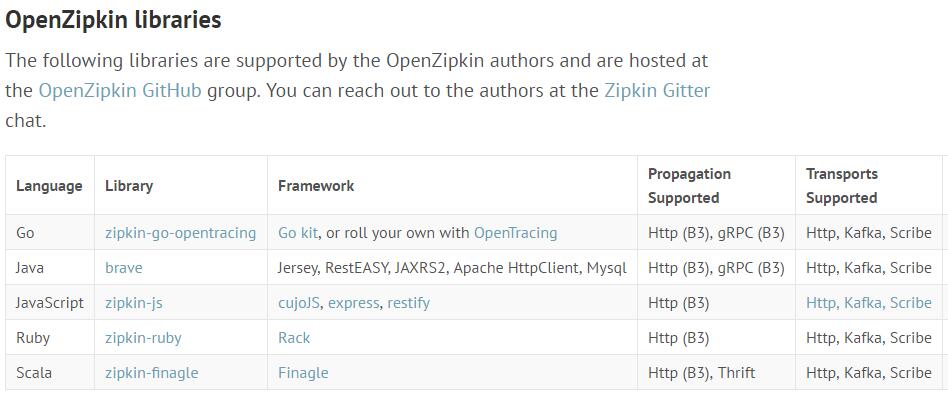
ps:支持go、scala,这个不错
第三方维护

ps:支持python,我就可以自己玩了,同时支持了四个Python库,最基础的是py_zipkin模块,pyramid_zipkin、swagger_zipkin、flask_zipkin三个都是基于py_zipkin再次封装的。
核心数据结构
traceId:全局跟踪ID,用它来标记一次完整服务调用,所以和一次服务调用相关的span中的traceId都是相同的,Zipkin将具有相同traceId的span组装成跟踪树来直观的将调用链路图展现在我们面前。
id:span的id,理论上来说,span的id只要做到一个traceId下唯一就可以
parentId:父span的id,调用有层级关系,所以span作为调用节点的存储结构,也有层级关系,就像图3所示,跟踪链是采用跟踪树的形式来展现的,树的根节点就是调用调用的顶点,从开发者的角度来说,顶级span是从接入了Zipkin的应用中最先接触到服务调用的应用中采集的。所以,顶级span是没有parentId字段的
name:span的名称,主要用于在界面上展示,一般是接口方法名,name的作用是让人知道它是哪里采集的span,不然某个span耗时高我都不知道是哪个服务节点耗时高
timestamp:span创建时的时间戳,用来记录采集的时刻。
duration:持续时间,即span的创建到span完成最终的采集所经历的时间,除去span自己逻辑处理的时间,该时间段可以理解成对于该跟踪埋点来说服务调用的总耗时
annotations:基本标注列表,一个标注可以理解成span生命周期中重要时刻的数据快照,比如一个标注中一般包含发生时刻(timestamp)、事件类型(value)、端点(endpoint)等信息
事件类型
cs:客户端/消费者发起请求
cr:客户端/消费者接收到应答
sr:服务端/生产者接收到请求
ss:服务端/生产者发送应答
PS:这四种事件类型的统计都应该是Zipkin提供客户端来做的,因为这些事件和业务无关,这也是为什么跟踪数据的采集适合放到中间件或者公共库来做的原因。
binaryAnnotations:业务标注列表,如果某些跟踪埋点需要带上部分业务数据(比如url地址、返回码和异常信息等),可以将需要的数据以键值对的形式放入到这个字段中。
参考
| 2.返回顶部 |
| 3.返回顶部 |
| 4.返回顶部 |
| 5.返回顶部 |
| 6.返回顶部 |
| 作者:ylbtech 出处:http://ylbtech.cnblogs.com/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。 |