终于决定学一下图了,图一直以为是一种蛮有意思的方法。
图G=(V,E),V表示顶点数,E表示边数,图可以分为有向图和无向图,有两种标准的方法,即邻接表和邻接矩阵。
邻接表有V个列表的Adj数组组成,Adj[u]包含图G中的所有和顶点u相连的顶点,在无向图中的顺序是任意的,在有向图中和图的方向有关。邻接矩阵在无向图中为顶点的点为1,其余为零,有向图中则和方向有关,如下图所示。
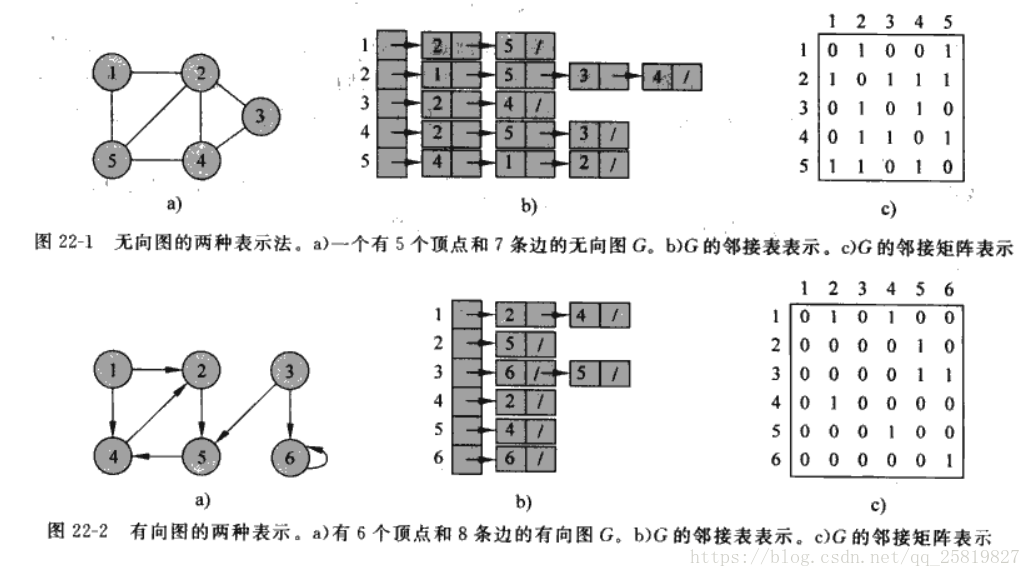
邻接表无论是有向图还是无向图的存储空间都为O(V+E),但有潜在的不足及,要搜索边(u,v)是否存在只能在Adj[u]数组中搜索v;邻接矩阵的存储空间为
,所需的存储空间较大,但搜索边(u,v)的速度较快。对于无向图的邻接矩阵,如上图所示为一个对称矩阵,存储空空间可以再缩小一半。
图搜索算法主要分为两种:广度优先算法和深度优先算法
广度优先算法(BFS)中:
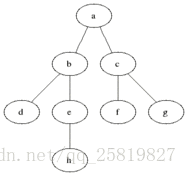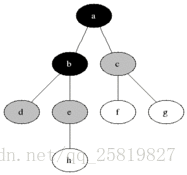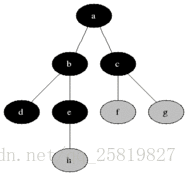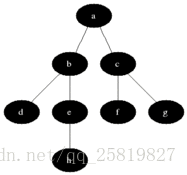
对于给定的图G和源顶点s,优先对s的相邻边进行搜索,以求发现所有s可以到达的顶点,同时还能生成一颗根为s,包含所有s能到达的广度优先树,适用于无向图和有向图。广度优先算法先发现与发现点与未发现的点之间的边界,沿其广度方向向外扩展,即会先发现1所有距离为k的点然后发现距离为k+1的点。
如下图所示:
代码(来自维基百科):
def breadth_first_search(problem):
# a FIFO open_set
open_set = Queue()
# an empty set to maintain visited nodes
closed_set = set()
# a dictionary to maintain meta information (used for path formation)
# key -> (parent state, action to reach child)
meta = dict()
# initialize
root = problem.get_root()
meta[root] = (None, None)
open_set.enqueue(root)
# For each node on the current level expand and process, if no children
# (leaf) then unwind
while not open_set.is_empty():
subtree_root = open_set.dequeue()
# We found the node we wanted so stop and emit a path.
if problem.is_goal(subtree_root):
return construct_path(subtree_root, meta)
# For each child of the current tree process
for (child, action) in problem.get_successors(subtree_root):
# The node has already been processed, so skip over it
if child in closed_set:
continue
# The child is not enqueued to be processed, so enqueue this level of
# children to be expanded
if child not in open_set:
meta[child] = (subtree_root, action) # create metadata for these nodes
open_set.enqueue(child) # enqueue these nodes
# We finished processing the root of this subtree, so add it to the closed
# set
closed_set.add(subtree_root)
# Produce a backtrace of the actions taken to find the goal node, using the
# recorded meta dictionary
def construct_path(state, meta):
action_list = list()
# Continue until you reach root meta data (i.e. (None, None))
while meta[state][0] is not None:
state, action = meta[state]
action_list.append(action)
action_list.reverse()
return action_list深度优先算法(DSF):
在算法的搜索过程中,对于发现的新的顶点,如果它还有以此为起点而未探测到的边,就研此边搜索下去。当顶点v的所有边都被搜索后回到发现v顶点那边开始搜索其他边,直到所有的顶点都被搜索完。
下面是深度优先算法的伪代码:
这里设置两个时间戳d[v],f[v],d[v]表示发现点v,f[v]表示结束发现点v,这里设置未发现点v为白色,发现后变灰色,结束搜索点v所在的支路后为黑色;
DFS(G)
for each vertes u∈V[G]
do color[u]<- WHITE
π[u]<-NIL
time<-0
for each vertex u∈V[G]
do if color[u]=WHITE
then DFS-VISIT(u)
DFS-VISIT(u)
color[u]<-GRAY
time<-time+1
d[u]<-time+1
for each v∈Adj[u]
do if color[v]=WHITE
then π[v]<-u
DFS-VISIT(v)
color[u]<-BLACK
f[u]<-time<-time+1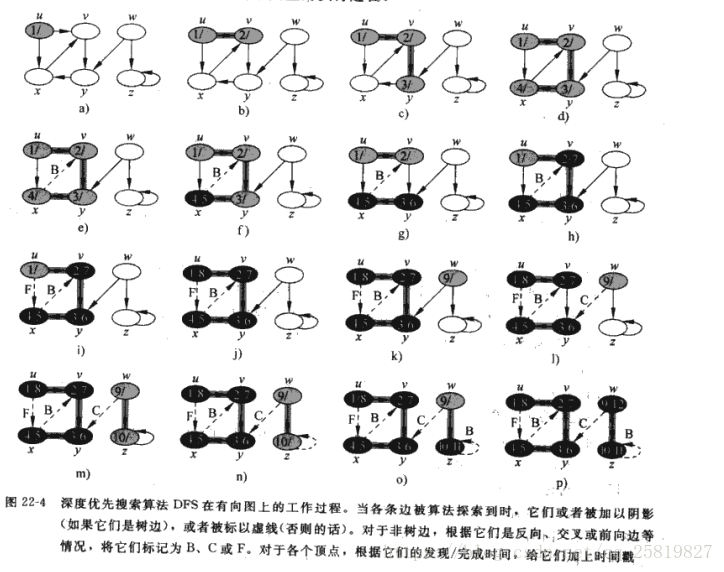
先初始化整个图为白色,π域为NIL,置定时器为0,再依次检索V中的顶点,当发现白色顶点时调用DFS-VISIT访问。
调用DFS-VISIT时置u为灰色,增加time的值,记录发现u的值,再检查和u相邻的顶点v如果为白色则递归调用DFS-VISIT,当以u为起点的所有边都被搜索后值u为黑色,并记录时间在f[u].
