版权声明:转载注明出处 https://blog.csdn.net/york1996/article/details/82776704
动漫头像数据集下载地址:动漫头像数据集_百度云连接,DCGAN论文下载地址: https://arxiv.org/abs/1511.06434
数据集里面的图片是这个样子的:

这是DCGAN的主要改进地方:

下面是所有代码:
第一个模块:
import torch
import torch.nn as nn
import numpy as np
import torch.nn.init as init
import data_helper
from torchvision import transforms
trans=transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize((.5,.5,.5),(.5,.5,.5))
]
)
G_LR=0.0002
D_LR=0.0002
BATCHSIZE=50
EPOCHES=3000
def init_ws_bs(m):
if isinstance(m,nn.ConvTranspose2d):
init.normal_(m.weight.data,std=0.2)
init.normal_(m.bias.data,std=0.2)
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.deconv1=nn.Sequential(
nn.ConvTranspose2d(#stride(input_w-1)+k-2*Padding
in_channels=100,
out_channels=64*8,
kernel_size=4,
stride=1,
padding=0,
bias=False,
),
nn.BatchNorm2d(64*8),
nn.ReLU(inplace=True),
)
self.deconv2=nn.Sequential(
nn.ConvTranspose2d(#stride(input_w-1)+k-2*Padding
in_channels=64*8,
out_channels=64*4,
kernel_size=4,
stride=2,
padding=1,
bias=False,
),
nn.BatchNorm2d(64*4),
nn.ReLU(inplace=True),
)
self.deconv3 = nn.Sequential(
nn.ConvTranspose2d( # stride(input_w-1)+k-2*Padding
in_channels=64*4,
out_channels=64*2,
kernel_size=4,
stride=2,
padding=1,
bias=False,
),
nn.BatchNorm2d(64*2),
nn.ReLU(inplace=True),
self.deconv4 = nn.Sequential(
nn.ConvTranspose2d( # stride(input_w-1)+k-2*Padding
in_channels=64*2,
out_channels=64*1,
kernel_size=4,
stride=2,
padding=1,
bias=False,
),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
)
self.deconv5=nn.Sequential(
nn.ConvTranspose2d(64,3,5,3,1,bias=False),
nn.Tanh(),
)
def forward(self, x):
x=self.deconv1(x)
x=self.deconv2(x)
x=self.deconv3(x)
x=self.deconv4(x)
x=self.deconv5(x)
return x
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(#batchsize,3,96,96
in_channels=3,
out_channels=64,
kernel_size=5,
padding=1,
stride=3,
bias=False,
),
nn.BatchNorm2d(64),
nn.LeakyReLU(.2,inplace=True),
)
self.conv2=nn.Sequential(
nn.Conv2d(64,64*2,4,2,1,bias=False,),#batchsize,16,32,32
nn.BatchNorm2d(64*2),
nn.LeakyReLU(.2,inplace=True),
)
self.conv3=nn.Sequential(
nn.Conv2d(64*2,64*4,4,2,1,bias=False),
nn.BatchNorm2d(64*4),
nn.LeakyReLU(.2,inplace=True),
)
self.conv4=nn.Sequential(
nn.Conv2d(64*4,64*8,4,2,1,bias=False),
nn.BatchNorm2d(64*8),
nn.LeakyReLU(.2,inplace=True),
)
self.output=nn.Sequential(
nn.Conv2d(64*8,1,4,1,0,bias=False),
nn.Sigmoid()#
)
def forward(self, x):
x=self.conv1(x)
x=self.conv2(x)
x=self.conv3(x)
x=self.conv4(x)
x=self.output(x)
return x
g=Generator().cuda()
d=Discriminator().cuda()
init_ws_bs(g),init_ws_bs(d)
g_optimizer=torch.optim.Adam(g.parameters(),betas=(.5,0.999),lr=G_LR)
d_optimizer=torch.optim.Adam(d.parameters(),betas=(.5,0.999),lr=D_LR)
g_loss_func=nn.BCELoss()
d_loss_func=nn.BCELoss()
label_real = torch.ones(BATCHSIZE).cuda()
label_fake = torch.zeros(BATCHSIZE).cuda()
real_img=data_helper.get_imgs()
batch_imgs=[]
for epoch in range(EPOCHES):
np.random.shuffle(real_img)
count=0
for i in range(len(real_img)):
count=count+1
batch_imgs.append(trans(real_img[i]).numpy())#tensor类型#这里经过trans操作通道维度从第四个到第二个了
if count==BATCHSIZE:
count=0
batch_real=torch.Tensor(batch_imgs).cuda()
batch_imgs.clear()
d_optimizer.zero_grad()
pre_real=d(batch_real).squeeze()
d_real_loss=d_loss_func(pre_real,label_real)
d_real_loss.backward()
batch_fake=torch.randn(BATCHSIZE,100,1,1).cuda()
img_fake=g(batch_fake)
pre_fake=d(img_fake).squeeze()
d_fake_loss=d_loss_func(pre_fake,label_fake)
d_fake_loss.backward()
d_optimizer.step()
g_optimizer.zero_grad()
batch_fake=torch.randn(BATCHSIZE,100,1,1).cuda()
img_fake=g(batch_fake)
pre_fake=d(img_fake).squeeze()
g_loss=g_loss_func(pre_fake,label_real)
g_loss.backward()
g_optimizer.step()
print(i,(d_real_loss+d_fake_loss).detach().cpu().numpy(),g_loss.detach().cpu().numpy())
torch.save(g,"pkl/"+str(epoch)+"g.pkl")
以上网络结构和参数,是从另一个博客找来的Pytorch实战3:DCGAN深度卷积对抗生成网络生成动漫头像
其中调用了一个同目录下的data_helper模块,用来从本地数据文件夹中获取图片(list of arrray),其中需要把文件夹改成自己的文件夹:
import cv2
import os
MAIN_PATH="E:/DataSets/faces/"
def get_imgs():
files = os.listdir(MAIN_PATH)
imgs = []
for file in files:
imgs.append(cv2.imread(MAIN_PATH + file))
print("get_imgs")
return imgs由于是对每个epoch都保存了网络结构,所以可以在训练完成后选择需要加载的本地网络文件,然后测试效果:
用下面的代码来测试:
import torch.nn as nn import torch import cv2 class Generator(nn.Module): def __init__(self): super(Generator, self).__init__() self.deconv1=nn.Sequential( nn.ConvTranspose2d(#stride(input_w-1)+k-2*Padding in_channels=100, out_channels=64*8, kernel_size=4, stride=1, padding=0, bias=False, ), nn.BatchNorm2d(64*8), nn.ReLU(inplace=True), )#14 self.deconv2=nn.Sequential( nn.ConvTranspose2d(#stride(input_w-1)+k-2*Padding in_channels=64*8, out_channels=64*4, kernel_size=4, stride=2, padding=1, bias=False, ), nn.BatchNorm2d(64*4), nn.ReLU(inplace=True), )#24 self.deconv3 = nn.Sequential( nn.ConvTranspose2d( # stride(input_w-1)+k-2*Padding in_channels=64*4, out_channels=64*2, kernel_size=4, stride=2, padding=1, bias=False, ), nn.BatchNorm2d(64*2), nn.ReLU(inplace=True), )#48 self.deconv4 = nn.Sequential( nn.ConvTranspose2d( # stride(input_w-1)+k-2*Padding in_channels=64*2, out_channels=64*1, kernel_size=4, stride=2, padding=1, bias=False, ), nn.BatchNorm2d(64), nn.ReLU(inplace=True), ) self.deconv5=nn.Sequential( nn.ConvTranspose2d(64,3,5,3,1,bias=False), nn.Tanh(), ) def forward(self, x): x=self.deconv1(x) x=self.deconv2(x) x=self.deconv3(x) x=self.deconv4(x) x=self.deconv5(x) return x g=torch.load("pkl/15g.pkl") imgs=g(torch.randn(100,100,1,1).cuda()) for i in range(len(imgs)): img=imgs[i].permute(1,2,0).cpu().detach().numpy()*255 cv2.imwrite("bitmaps/"+str(i)+".jpg",img,)#这里需要在同目录下建立一个bitmap文件夹 print("done")
接下来是运行的效果:
第一个epoch结束之后:
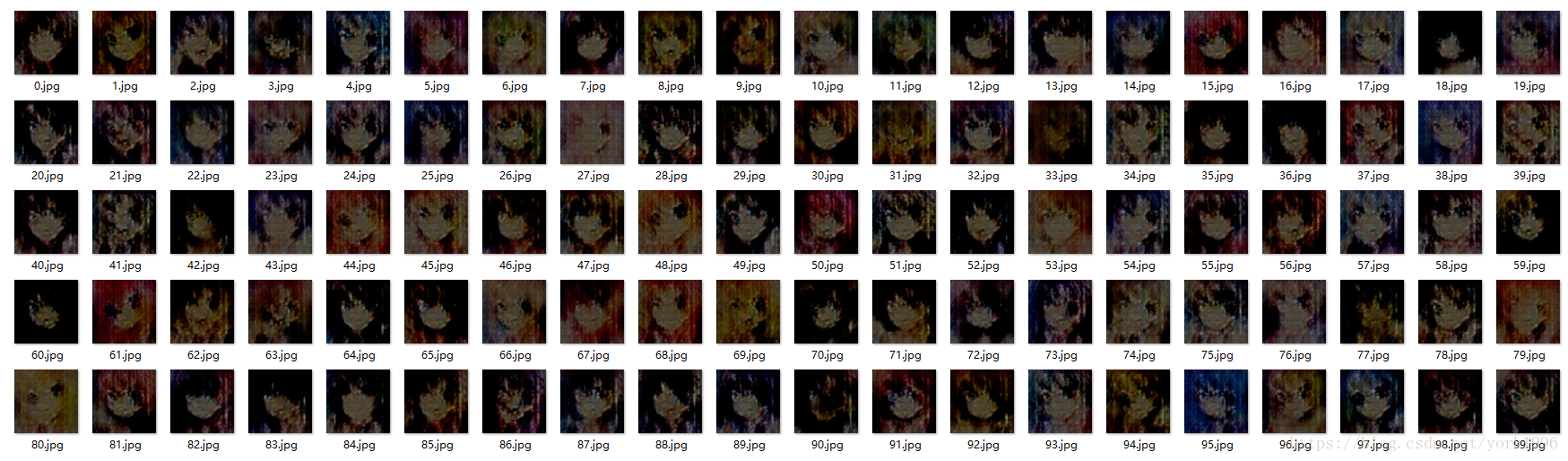
第15个epoch之后:
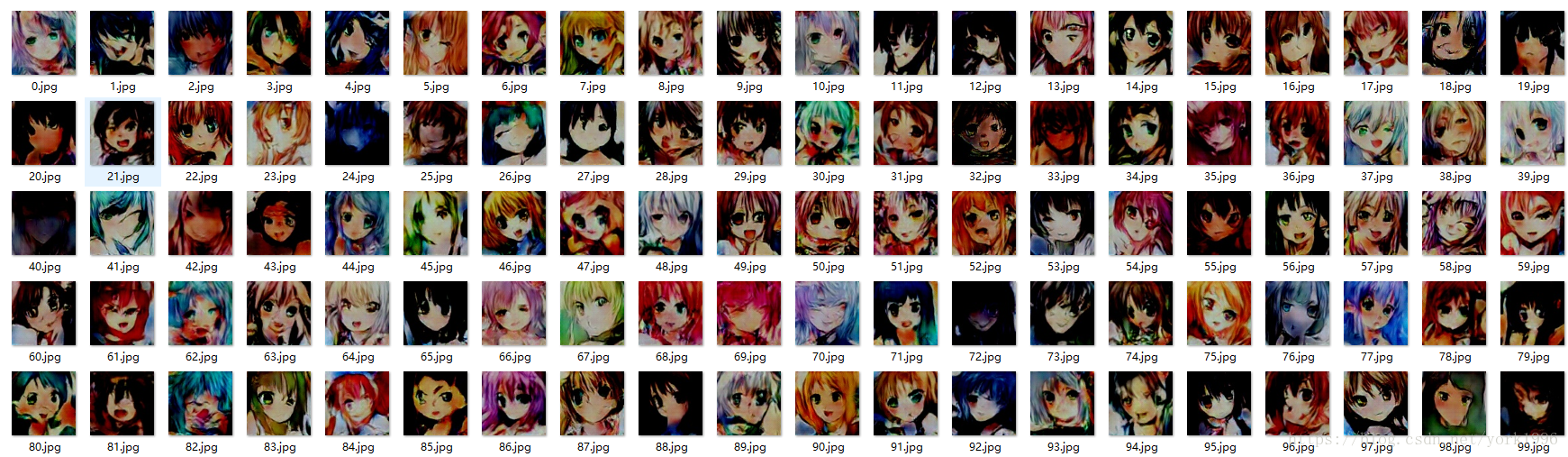
一共训练了67个epoch,最终的结果:

可以看到效果和15个迭代器的差别不大,说明网络的收敛速度还是可以的,但是效果也不算太好,没有原先数据集中的美观。