Redis 数据类型 - zset (有序集合)
有序集合每个元素都是一个字符串对象,每个元素都有一个分值为 double 类型的浮点数,底层数据结构是 ziplist 和 skiplist(跳跃表)+ dict 字典。
- *dict:保存一个从成员到分数的映射,通过该字典可以用O(1)的复杂度查找给定成员的分值。
- *zsl: 按照分值从小到大保存了所有集合元素,每个跳跃表节点都保存了一个元素。可以通过它对 zset 进行范围型操作,例如 ZRANK、ZRANGE。
- 同时使用字典和跳跃表并不会产生重复成员和分值,因为通过指针进行共享相同元素的成员和分值,也不会浪费内存。
typedef struct zset {
// 字典结构:保存一个从成员到分数的映射
dict *dict;
// 跳跃表指针
zskiplist *zsl;
} zset;
1 zset 中的 ziplist
当使用 ziplist 存储时,类似上面使用 ziplist 存储 hash 对象的结构,根据分值从小到大排序,分值较小的元素放置为靠近表头的位置,分值较大的则靠经表尾的位置。而元素的成员和分值存储,则是第一个节点为成员,第二个为分值,结构如下。
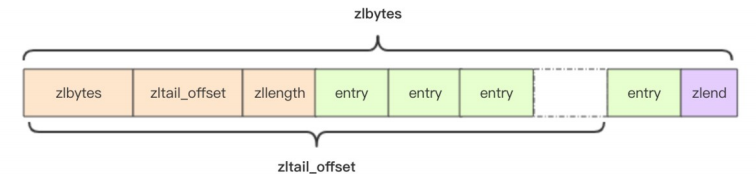

因为 ziplist 都是紧凑存储,没有冗余空间,意味着插入一个元素就需要调用 realloc 扩展内存,取决于内存分配器算法和当前的 ziplist 内存大小, realloc 可能会重新分配新的内存空间,并将之前的内容一次性拷贝到新的地址,当 ziplist 占据内存太大,重新分配内存和拷贝内存就会有很大的消耗。所以 ziplist 不适合存储大型字符串,存储的元素也不宜过多。
当 zset 对象可以同时满足以下条件,则为 ziplist 编码:
- zset 对象保存的元素数量小于 128个;
- zset 对象保存的所有元素成员的长度都小于64字节;
不满足上述情况,则使用 skiplist 编码。
2 skiplist(跳跃表)
跳表skipList在Redis中的运用场景只有一个,那就是作为有序列表zset的底层实现。跳表可以保证增、删、查等操作时的时间复杂度为O(logN),这个性能可以与平衡树相媲美,但实现方式上却更加简单,唯一美中不足的就是跳表占用的空间比较大,其实就是一种空间换时间的思想。跳表的结构如下所示:

图中只画了四层,Redis 的跳跃表共有 64 层,意 味着最多可以容纳 2^64 次方个元素。每一个 kv 块对应的结构如下面的代码中 的 zskiplistNode 结构,kv header 也是这个结构,只不过 value 字段是 null 值——无效的,score 是 Double.MIN_VALUE,用来垫底的。kv 之间使用指针串起来形成了双向链表结构,它们是有序排列的,从小到大。不同的 kv 层高可能不一样,层数越高的 kv 越少。同一层的 kv 会使用指针串起来。每一个层元素的遍历都是从 kv header 出发。
typedf struct zskiplist{
//头节点
struct zskiplistNode *header;
//尾节点
struct zskiplistNode *tail;
// 跳表中元素个数
unsigned long length;
//目前表内节点的最大层数
int level;
}zskiplist;
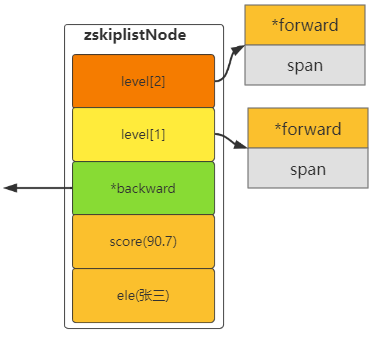
typedef struct zskiplistNode {
// 元素成员值
sds ele;
// 分值
double score;
// 回退指针
struct zskiplistNode *backward;
struct zskiplistLevel {
// 前进指针forward
struct zskiplistNode *forward;
// 跨度span
unsigned long span;
} level[]; //层级数组 最大32
} zskiplistNode;
2.1 增加节点过程
单个节点结构如下
- 初始状态假定如下图,需要添加值为赵六,分数为101的元素,大致的步骤包括找到要插入的位置,新建一个数据节点,然后调整与之相关的头尾指针的level数组。

- 从表头的level即3开始,首先到张三的L3,发现分数70,比目标分数101小跳过,根据其前指针找到赵六的L3,发现分数102,比目标分数101大,将赵六L3记录在待更新数组update中,同时记录跨度span为4。接着到下一层,张三的L2层,发现分数70比目标分数101小跳过,根据前指针找到王五的L2,发现分数90,比目标分数101小跳过,根据前指针找到赵六的L2,发现分数102比目标分数101大,将赵六的L2记录到待更新数组update中,同时记录跨度span为2。最后到下一层,张三的L1层,逻辑和刚才一样的,也是记录赵六的L1层和跨度span为1。
- 为新节点随机生成层级数level(通过位运算),如果生成的level大于目前level最大值3,则将将大于部分挨个遍历,并将跨度等信息记录到上面update表中。比如,新节点生成的level为5,目前level最大值为3,说明这个节点只会有一个,并且跨越了之前的所有节点,那么我们将从第四层和第五层都遍历下,记录到待更新数组update中。
- 准备工作都做好了,找到了该节点将插入到哪一位置,处于哪一层,每层对应的跨度是多少,下面就要新增数据节点了。把上两步的信息都添加到新节点上,并且调整位置前后指针即可。4.最后就是一些收尾工作,比如修改表头的层级level,节点大小length和尾指针tail等属性。
3 为什么不使用平衡树而选择跳跃表
- skiplist和各种平衡树(如AVL、红黑树等)的元素是有序排列的,而哈希表不是有序的。因此,在哈希表上只能做单个key的查找,不适宜做范围查找。所谓范围查找,指的是查找那些大小在指定的两个值之间的所有节点。
- 在做范围查找的时候,平衡树比skiplist操作要复杂。在平衡树上,我们找到指定范围的小值之后,还需要以中序遍历的顺序继续寻找其它不超过大值的节点。如果不对平衡树进行一定的改造,这里的中序遍历并不容易实现。而在skiplist上进行范围查找就非常简单,只需要在找到小值之后,对第1层链表进行若干步的遍历就可以实现。
- 平衡树的插入和删除操作可能引发子树的调整,逻辑复杂,而skiplist的插入和删除只需要修改相邻节点的指针,操作简单又快速。
- 从内存占用上来说,skiplist比平衡树更灵活一些。一般来说,平衡树每个节点包含2个指针(分别指向左右子树),而skiplist每个节点包含的指针数目平均为1/(1-p),具体取决于参数p的大小。如果像Redis里的实现一样,取p=1/4,那么平均每个节点包含1.33个指针,比平衡树更有优势。
- 查找单个key,skiplist和平衡树的时间复杂度都为O(log n),大体相当;而哈希表在保持较低的哈希值冲突概率的前提下,查找时间复杂度接近O(1),性能更高一些。所以我们平常使用的各种Map或dictionary结构,大都是基于哈希表实现的。
- 从算法实现难度上来比较,skiplist比平衡树要简单得多。
4 紧凑列表
对 ziplist 结构的改进,节省了存储空间。但是还未进行替换,只是增加了。首先这个 listpack 跟 ziplist 的结构几乎一摸一样,只是少了一个 zltail_offset 字段。ziplist 通过这个字段来定位出最后一个元素的位置,用于 逆序遍历。不过 listpack 可以通过其它方式来定位出最后一个元素的位置,所以 zltail_offset 字段就省掉了。
struct listpack {
int32 total_bytes; // 占用的总字节数
int16 size; // 元素个数
T[] entries; // 紧凑排列的元素列表
int8 end; // 同 zlend 一样,恒为 0xFF
}
设置 zset 中 ziplist 的参数,主要是为了配置转换 skiplist 的参数。例如当待新加的新的字符串长度超过zset_max_ziplist_value(默认值64)时或者 ziplist 保存的节点数量超过 zset_max_ziplist_entries (默认值128)时使用skiplist。
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
https://juejin.cn/post/6844904194952921101#heading-17