Put操作:
1. 实例化Configuration类
Configuration conf = HbaseConfiguration.create();
同Get操作。
2、 实例化HTable类
HTable hTable = new HTable(conf,tableName);
同Get操作。
3、 实例化Put类
Put p = new Put(Bytes.toBytes(“row1”));
在Put类中的第110行,对传入的参数Row进行了行键长度的检查。之后,给属性赋了初值。
4、 插入数据
p.add(Bytes.toBytes(“column family”),Bytes.toBytes(“columnname”),Bytes.toBytes(“value”))
源码在Put类中的202行,在207行将要添加的值封装为KeyValue对象(KeyValue实现了Cell接口),之后加入List,然后将其加入familyMap中。(familyMap为抽象类Mutation中的属性成员,Put类继承了Mutation类,该成员在定义时已经实例化了。)
5、 保存数据到表中。
hTable.put(p);
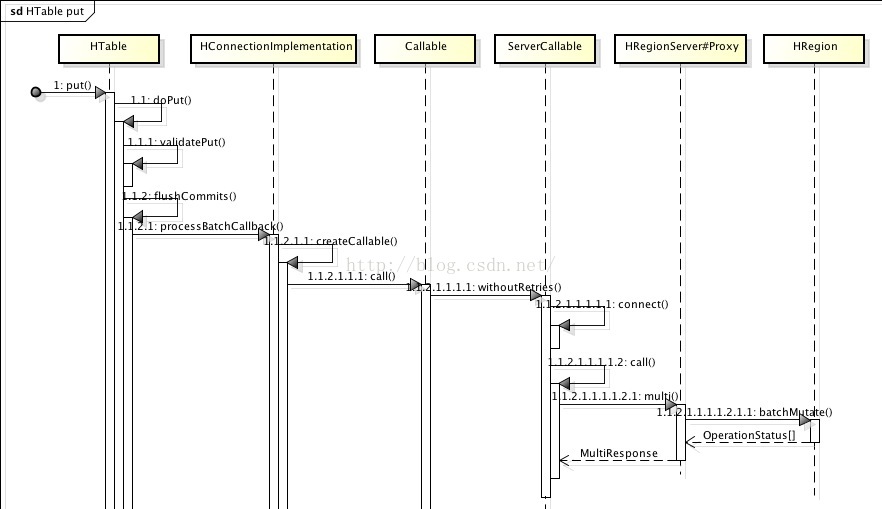
该方法的源码在HTable类中的第988行。
989行:getBufferedMutator().mutate(put)主要做的操作:
1) 验证传入的put的合法性。(在HTable类中的1459行的validatePut方法中)
2) 将put操作加入写的缓冲池中。
刷新缓冲池:991行:flushCommits()
1) 在BufferedMutatorImpl中的201行的backgroundFlushCommits中,如果之前的ap异步提交到有问题,就先进行后台提交,不过这次是同步的,如果没有错误,就把put添加到队列当中,然后检查一下当前的 buffer的大小,超过我们设置的内容的时候,就flush掉。
2) 定位locs:在AsyncProcess类中的第374行中,
3) RegionLoactions locs =connection.locateRegion(….)就是根据表名和行键来定位region的。
4) 之后在400行的addAction中将任务加入到actionByServer中(actionByServer是Map<ServerName,MultiAction<Row>>)。
5) 提交任务:第412行的submitMultiActions方法
Put操作总结:
(1)把put操作添加到writeAsyncBuffer队列里面,符合条件(自动flush或者超过了阀值writeBufferSize)就通过AsyncProcess异步批量提交。
(2)在提交之前,我们要根据每个rowkey找到它们归属的region server,这个定位的过程是通过HConnection的locateRegion方法获得的,然后再把这些rowkey按照HRegionLocation分组。
(3)通过多线程,一个HRegionLocation构造MultiServerCallable<Row>,然后通过rpcCallerFactory.<MultiResponse> newCaller()执行调用,忽略掉失败重新提交和错误处理,客户端的提交操作到此结束。
等待写入的数据超过配置的writeBufferSize(通过hbase.client.write.buffer配置,默认为2M)时才提交写数据请求,如果最后的写入数据没有超过2M,则在调用close方法时会进行最后的提交,当然,如果使用批量的put方法时,自己控制flushCommits则效果不同,比如每隔1000条进行一次提交,如果1000条数据的总大小超过了2M,则实际上会发生多次提交,导致最终的提交次数多过只由writeBufferSize控制的提交次数,因此在实际的项目中,如果对写性能的要求比对数据的实时可查询和不可丢失的要求更高则可以设置autoFlush为false并采用单条写的put(final Put put)API,这样即可以简化写操作数据的程序代码,写入效率也更优,需要注意的是如果对数据的实时可查询和不可丢失有较高的要求则应该设置autoFlush为true并采用单条写的API,这样可以确保写一条即提交一条。
关于多线程写
在0.94.12这个版本中,对于写操作,HBase内部就是多线程,线程数量与批量提交的数据涉及的region个数相同,通常情况下不需要再自己写多线程代码,自己写的多线程代码主要是解决数据到HTable的put这个过程中的性能问题,数据进入put的缓存,当达到writeBufferSize设定的大小后才会真正发起写操作(如果不是自己控制flush),这个过程的线程数与这批数据涉及的region个数相同,会并行写入所有相关region,一般不会出现性能问题,当涉及的region个数过多时会导致创建过多的线程,消耗大量的内存,甚至会出现线程把内存耗尽而导致OutOfMemory的情况,比较理想的写入场景是调大writeBufferSize,并且一次写入适量的不同regionserver的region,这样可以充分把写压力分摊到多个服务器。
参考资料: http://www.chinacloud.cn/show.aspx?id=14551&cid=14