根据Java程序员面试宝典、网上相关技术博客以及自己相关笔记做的整理,其他部分还在陆续整理,后续会发出。希望对大家有帮助。祝大家都能拿到心仪的Offer,加油^_^^_^
-
Java面向对象三大特征--继承、封装、多态
面向对象基本概念:
对象是同类事物的一种抽象表现形式,而实例是对象的具体化,一个对象可以实例化很多实例,对象就是一个模型,实例是照着这个模型生产的最终产品。
不需要实例化:静态方法是为类提供的公共方法,也就是这个方法对所有属于这个类的对象适用。
需要实例化:具体到了某个具体的事物,就需要进行实例化,例如:每个人的身高、体重,当要查询指定那个人的体重,这个过程就相当于实例化,即具体到了个人。
-
继承
继承:是子类继承父类的特征和行为,使得子类对象(实例)具有父类的实例域和方法,或子类从父类继承方法,使得子类具有父类相同的行为。
需要注意的是 Java 不支持多继承,但支持多重继承。

继承的特性:
子类拥有父类非private的属性,方法。
子类可以拥有自己的属性和方法,即子类可以对父类进行扩展。
子类可以用自己的方式实现父类的方法。
Java的继承是单继承,但是可以多重继承,单继承就是一个子类只能继承一个父类,多重继承就是,例如A类继承B类,B类继承C类,所以按照关系就是C类是B类的父类,B类是A类的父类,这是java继承区别于C++继承的一个特性。
提高了类之间的耦合性(继承的缺点,耦合度高就会造成代码之间的联系越紧密,代码独立性越差)。
补充:在继承结构中,父类的内部细节对于子类是可见的。所以,通过继承的代码复用是一种“白盒式代码复用”。
组合是指通过对现有的对象进行拼装(组合)产生新的更复杂的功能。因为在对象之间,各自的内部细节是不可见的,所以,我们也说这种方式的代码复用是“黑盒式代码复用”。
继承关键字
继承可以使用 extends 和 implements 这两个关键字来实现继承,而且所有的类都是继承于 java.lang.Object,当一个类没有继承的两个关键字,则默认继承object(这个类在 java.lang 包中,所以不需要 import)祖先类。
extends关键字:在 Java 中,类的继承是单一继承,也就是说,一个子类只能拥有一个父类,所以 extends 只能继承一个类。
extends 关键字
public class Animal {
private String name;
private int id;
public Animal(String myName, String maid)
{ //初始化属性值 }
public void eat()
{ //吃东西方法的具体实现 }
public void sleep()
{ //睡觉方法的具体实现 }
}
public class Penguin extends Animal{ }implements关键字
使用 implements 关键字可以变相的使java具有多继承的特性,使用范围为类继承接口的情况,可以同时继承多个接口(接口跟接口之间采用逗号分隔)。
public interface A {
public void eat();
public void sleep();
}
public interface B {
public void show();
}
public class C implements A,B {}super 与 this 关键字
super关键字:我们可以通过super关键字来实现对父类成员的访问,用来引用当前对象的父类。
this关键字:指向自己的引用。
class Animal {
void eat() {
System.out.println("animal : eat");
}
}
class Dog extends Animal {
void eat() {
System.out.println("dog : eat");
}
void eatTest() {
this.eat(); // this 调用自己本类的方法
super.eat(); // super 调用父类方法
}
}
public class Animal0904 {
public static void main(String[] args) {
Animal a = new Animal();
a.eat();
Dog d = new Dog();
d.eatTest();
}
}final关键字
final 关键字声明类可以把类定义为不能继承的,即最终类;或者用于修饰方法,该方法不能被子类重写:
声明类:final class 类名 {//类体}
声明方法:修饰符(public/private/default/protected) final 返回值类型 方法名(){//方法体}
注:实例变量也可以被定义为 final,被定义为 final 的变量不能被修改。被声明为final类的方法自动地声明为 final,但是实例变量并不是 final
构造器
子类不能继承父类的构造器(构造方法或者构造函数),如果父类的构造器带有参数,则必须在子类的构造器中显式地通过 super 关键字调用父类的构造器并配以适当的参数列表。
如果父类构造器没有参数,则在子类的构造器中不需要使用 super 关键字调用父类构造器,系统会自动调用父类的无参构造器。
class SuperClass {
private int n;
SuperClass(){
System.out.println("SuperClass()");
}
SuperClass(int n) {
System.out.println("SuperClass(int n)");
this.n = n;
}
}
class SubClass extends SuperClass{
private int n;
SubClass(){
super(300);
System.out.println("SubClass");
}
public SubClass(int n){
System.out.println("SubClass(int n):"+n);
this.n = n;
}
}
public class SuperClass0904{
public static void main (String args[]){
SubClass sc = new SubClass();
SubClass sc2 = new SubClass(200);
}
}
输出结果:
SuperClass(int n)
SubClass
SuperClass()
SubClass(int n):2002.Java 多态
多态是同一个行为具有多个不同表现形式或形态的能力。
多态就是同一个接口,使用不同的实例而执行不同操作。
多态的优点:
1). 消除类型之间的耦合关系
2). 可替换性
3). 可扩充性
4). 接口性
5). 灵活性
6). 简化性
多态存在的三个必要条件:继承、重写、父类引用指向子类对象(Parent p = new Child();)
多态的三种实现方式
方式一:重写
重写是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。即外壳不变,核心重写!
重写的好处在于子类可以根据需要,定义特定于自己的行为。 也就是说子类能够根据需要实现父类的方法。
重写方法不能抛出新的检查异常或者比被重写方法申明更加宽泛的异常。例如: 父类的一个方法申明了一个检查异常 IOException,但是在重写这个方法的时候不能抛出 Exception 异常,因为 Exception 是 IOException 的父类,只能抛出 IOException 的子类异常。
在面向对象原则里,重写意味着可以重写任何现有方法。
方法的重写规则
* 参数列表必须完全与被重写方法的相同;
* 返回类型必须完全与被重写方法的返回类型相同;
* 访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为public,那么在子类中重写该方法就不能声明为protected。
* 父类的成员方法只能被它的子类重写。
* 声明为final的方法不能被重写。
* 声明为static的方法不能被重写,但是能够被再次声明。
* 子类和父类在同一个包中,那么子类可以重写父类所有方法,除了声明为private和final的方法。
* 子类和父类不在同一个包中,那么子类只能够重写父类的声明为public和protected的非final方法。
* 重写的方法能够抛出任何非强制异常,无论被重写的方法是否抛出异常。但是,重写的方法不能抛出新的强制性异常,或者比被重写方法声明的更广泛的强制性异常,反之则可以。
* 构造方法不能被重写。
* 如果不能继承一个方法,则不能重写这个方法。
方式二:接口
1. 生活中的接口最具代表性的就是插座,例如一个三接头的插头都能接在三孔插座中,因为这个是每个国家都有各自规定的接口规则,有可能到国外就不行,那是因为国外自己定义的接口类型。
2. java中的接口类似于生活中的接口,就是一些方法特征的集合,但没有方法的实现。具体可以看 java接口这一章节的内容。
方式三:抽象类和抽象方法
抽象方法是一种特殊的方法:它只有声明,而没有具体的实现。抽象方法的声明格式为:abstract void fun();
如果一个类含有抽象方法,则称这个类为抽象类,抽象类必须在类前用abstract关键字修饰。因为抽象类中含有无具体实现的方法,所以不能用抽象类创建对象。
《JAVA编程思想》一书中,将抽象类定义为“包含抽象方法的类”,但是后面发现如果一个类不包含抽象方法,只是用abstract修饰的话也是抽象类。也就是说抽象类不一定必须含有抽象方法。
[public] abstract class ClassName {
abstract void fun();
}从这里可以看出,抽象类就是为了继承而存在的,如果你定义了一个抽象类,却不去继承它,那么等于白白创建了这个抽象类,因为你不能用它来做任何事情。对于一个父类,如果它的某个方法在父类中实现出来没有任何意义,必须根据子类的实际需求来进行不同的实现,那么就可以将这个方法声明为abstract方法,此时这个类也就成为abstract类了。
包含抽象方法的类称为抽象类,但并不意味着抽象类中只能有抽象方法,它和普通类一样,同样可以拥有成员变量和普通的成员方法。注意,抽象类和普通类主要有三点区别:
1)抽象方法必须为public或者protected(因为如果为private,则不能被子类继承,子类便无法实现该方法),缺省情况下默认为public。
2)抽象类不能用来创建对象;
3)如果一个类继承于一个抽象类,则子类必须实现父类的抽象方法。如果子类没有实现父类的抽象方法,则必须将子类也定义为为abstract类。
在其他方面,抽象类和普通的类并没有区别。
接口
在软件工程中,接口泛指供别人调用的方法或者函数。从这里,我们可以体会到Java语言设计者的初衷,它是对行为的抽象。在Java中,定一个接口的形式如下:
[public] interface InterfaceName {}
接口中可以含有 变量和方法。但是要注意,接口中的变量会被隐式地指定为public static final变量(并且只能是public static final变量,用private修饰会报编译错误),而方法会被隐式地指定为public abstract方法且只能是public abstract方法(用其他关键字,比如private、protected、static、 final等修饰会报编译错误),并且接口中所有的方法不能有具体的实现,也就是说,接口中的方法必须都是抽象方法。从这里可以隐约看出接口和抽象类的区别,接口是一种极度抽象的类型,它比抽象类更加“抽象”,并且一般情况下不在接口中定义变量。
要让一个类遵循某组特地的接口需要使用implements关键字,具体格式如下:
class ClassName implements Interface1,Interface2,[....]{}
3.封装
在面向对象程式设计方法中,封装(英语:Encapsulation)是指一种将抽象性函式接口的实现细节部分包装、隐藏起来的方法。
封装可以被认为是一个保护屏障,防止该类的代码和数据被外部类定义的代码随机访问。
要访问该类的代码和数据,必须通过严格的接口控制。
封装最主要的功能在于我们能修改自己的实现代码,而不用修改那些调用我们代码的程序片段。
适当的封装可以让程式码更容易理解与维护,也加强了程式码的安全性。
封装的优点
1). 良好的封装能够减少耦合。
2). 类内部的结构可以自由修改。
3). 可以对成员变量进行更精确的控制。
4). 隐藏信息,实现细节。
实现Java封装的步骤
1). 修改属性的可见性来限制对属性的访问(一般限制为private),例如:
public class Person {
private String name;
private int age;
}这段代码中,将 name 和 age 属性设置为私有的,只能本类才能访问,其他类都访问不了,如此就对信息进行了隐藏。
2). 对每个值属性提供对外的公共方法访问,也就是创建一对赋取值方法,用于对私有属性的访问,例如:
public class Person{
private String name;
private int age;
public int getAge(){
return age;
}
public String getName(){
return name;
}
public void setAge(int age){
this.age = age;
}
public void setName(String name){
this.name = name;
}
}采用 this 关键字是为了解决实例变量(private String name)和局部变量(setName(String name)中的name变量)之间发生的同名的冲突。
抽象类和接口的区别
(1).语法层面上的区别
1)抽象类可以提供成员方法的实现细节,而接口中只能存在public abstract 方法;
2)抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的;
3)接口中不能含有静态代码块以及静态方法,而抽象类可以有静态代码块和静态方法;
4)一个类只能继承一个抽象类,而一个类却可以实现多个接口。
(2).设计层面上的区别
1)抽象类是对一种事物的抽象,即对类抽象,而接口是对行为的抽象。抽象类是对整个类整体进行抽象,包括属性、行为,但是接口却是对类局部(行为)进行抽象。
举个简单的例子,飞机和鸟是不同类的事物,但是它们都有一个共性,就是都会飞。那么在设计的时候,可以将飞机设计为一个类Airplane,将鸟设计为一个类Bird,但是不能将 飞行 这个特性也设计为类,因此它只是一个行为特性,并不是对一类事物的抽象描述。此时可以将 飞行 设计为一个接口Fly,包含方法fly( ),然后Airplane和Bird分别根据自己的需要实现Fly这个接口。然后至于有不同种类的飞机,比如战斗机、民用飞机等直接继承Airplane即可,对于鸟也是类似的,不同种类的鸟直接继承Bird类即可。从这里可以看出,继承是一个 "是不是"的关系,而 接口 实现则是 "有没有"的关系。如果一个类继承了某个抽象类,则子类必定是抽象类的种类,而接口实现则是有没有、具备不具备的关系,比如鸟是否能飞(或者是否具备飞行这个特点),能飞行则可以实现这个接口,不能飞行就不实现这个接口。
2)设计层面不同,抽象类作为很多子类的父类,它是一种模板式设计。而接口是一种行为规范,它是一种辐射式设计。什么是模板式设计?最简单例子,大家都用过ppt里面的模板,如果用模板A设计了ppt B和ppt C,ppt B和ppt C公共的部分就是模板A了,如果它们的公共部分需要改动,则只需要改动模板A就可以了,不需要重新对ppt B和ppt C进行改动。
而辐射式设计,比如某个电梯都装了某种报警器,一旦要更新报警器,就必须全部更新。也就是说对于抽象类,如果需要添加新的方法,可以直接在抽象类中添加具体的实现,子类可以不进行变更;而对于接口则不行,如果接口进行了变更,则所有实现这个接口的类都必须进行相应的改动。
门和警报的例子:门都有open( )和close( )两个动作,此时我们可以定义通过抽象类和接口来定义这个抽象概念:
abstract class Door {
public abstract void open();
public abstract void close();
}
//或者
interface Door {
public abstract void open();
public abstract void close();
}但是现在如果我们需要门具有报警alarm( )的功能,那么该如何实现?下面提供两种思路:
1)将这三个功能都放在抽象类里面,但是这样一来所有继承于这个抽象类的子类都具备了报警功能,但是有的门并不一定具备报警功能;
2)将这三个功能都放在接口里面,需要用到报警功能的类就需要实现这个接口中的open( )和close( ),也许这个类根本就不具备open( )和close( )这两个功能,比如火灾报警器。
从这里可以看出, Door的open() 、close()和alarm()根本就属于两个不同范畴内的行为,open()和close()属于门本身固有的行为特性,而alarm()属于延伸的附加行为。因此最好的解决办法是单独将报警设计为一个接口,包含alarm()行为,Door设计为单独的一个抽象类,包含open和close两种行为。再设计一个报警门继承Door类和实现Alarm接口。
interface Alram {
void alarm();
}
abstract class Door {
void open();
void close();
}
class AlarmDoor extends Door implements Alarm {
void oepn() {
//....
}
void close() {
//....
}
void alarm() {
//....
}
}
-
Java 类加载ClassLoad
1.什么是ClassLoader?
大家都知道,当我们写好一个Java程序之后,不管是CS还是BS应用,都是由若干个.class文件组织而成的一个完整的Java应用程序,当程序在运行时,即会调用该程序的一个入口函数来调用系统的相关功能,而这些功能都被封装在不同的class文件当中,所以经常要从这个class文件中调用另外一个class文件中的方法,如果另外一个文件不存在的,则会引发系统异常。而程序在启动的时候,并不会一次性加载程序所要用的所有class文件,而是根据程序的需要,通过Java的类加载机制(ClassLoader)来动态加载某个class文件到内存当中的,从而只有class文件被载入到了内存之后,才能被其它class所引用。所以ClassLoader就是用来动态加载class文件到内存当中用的。
2.Java默认提供的三个ClassLoader
1)BootStrap ClassLoader:称为启动类加载器,是Java类加载层次中最顶层的类加载器,负责加载JDK中的核心类库,如:rt.jar、resources.jar、charsets.jar等,可通过如下程序获得该类加载器从哪些地方加载了相关的jar或class文件:
URL[] urls = sun.misc.Launcher.getBootstrapClassPath().getURLs();
for (int i = 0; i < urls.length; i++) {
System.out.println(urls[i].toExternalForm());
}2)Extension ClassLoader:称为扩展类加载器,负责加载Java的扩展类库,默认加载JAVA_HOME/jre/lib/ext/目下的所有jar。
3)App ClassLoader:称为系统类加载器,负责加载应用程序classpath目录下的所有jar和class文件。
注意: 除了Java默认提供的三个ClassLoader之外,用户还可以根据需要定义自已的ClassLoader,而这些自定义的ClassLoader都必须继承自java.lang.ClassLoader类,也包括Java提供的另外二个ClassLoader(Extension ClassLoader和App ClassLoader)在内,但是Bootstrap ClassLoader不继承自ClassLoader,因为它不是一个普通的Java类,底层由C++编写,已嵌入到了JVM内核当中,当JVM启动后,Bootstrap ClassLoader也随着启动,负责加载完核心类库后,并构造Extension ClassLoader和App ClassLoader类加载器。
3.ClassLoader加载类的原理
1)原理介绍
ClassLoader使用的是双亲委托模型来搜索类的,每个ClassLoader实例都有一个父类加载器的引用(不是继承的关系,是一个包含的关系),虚拟机内置的类加载器(Bootstrap ClassLoader)本身没有父类加载器,但可以用作其它ClassLoader实例的的父类加载器。当一个ClassLoader实例需要加载某个类时,它会试图亲自搜索某个类之前,先把这个任务委托给它的父类加载器,这个过程是由上至下依次检查的,首先由最顶层的类加载器Bootstrap ClassLoader试图加载,如果没加载到,则把任务转交给Extension ClassLoader试图加载,如果也没加载到,则转交给App ClassLoader 进行加载,如果它也没有加载得到的话,则返回给委托的发起者,由它到指定的文件系统或网络等URL中加载该类。如果它们都没有加载到这个类时,则抛出ClassNotFoundException异常。否则将这个找到的类生成一个类的定义,并将它加载到内存当中,最后返回这个类在内存中的Class实例对象。
2)为什么要使用双亲委托这种模型呢?
因为这样可以避免重复加载,当父亲已经加载了该类的时候,就没有必要子ClassLoader再加载一次。考虑到安全因素,我们试想一下,如果不使用这种委托模式,那我们就可以随时使用自定义的String来动态替代java核心api中定义的类型,这样会存在非常大的安全隐患,而双亲委托的方式,就可以避免这种情况,因为String已经在启动时就被引导类加载器(Bootstrcp ClassLoader)加载,所以用户自定义的ClassLoader永远也无法加载一个自己写的String,除非你改变JDK中ClassLoader搜索类的默认算法。
3) 但是JVM在搜索类的时候,又是如何判定两个class是相同的呢?
JVM在判定两个class是否相同时,不仅要判断两个类名是否相同,而且要判断是否由同一个类加载器实例加载的。只有两者同时满足的情况下,JVM才认为这两个class是相同的。
4.ClassLoad体系结构

Class类中有一个静态方法forName,这个方法和ClassLoader中的loadClass方法目的一样,都是用来加载class的,但两者作用有所区别。使用forName加载的时候会将Class进行解释和初始化。loadClass加载类时并不对该类进行解释。
-
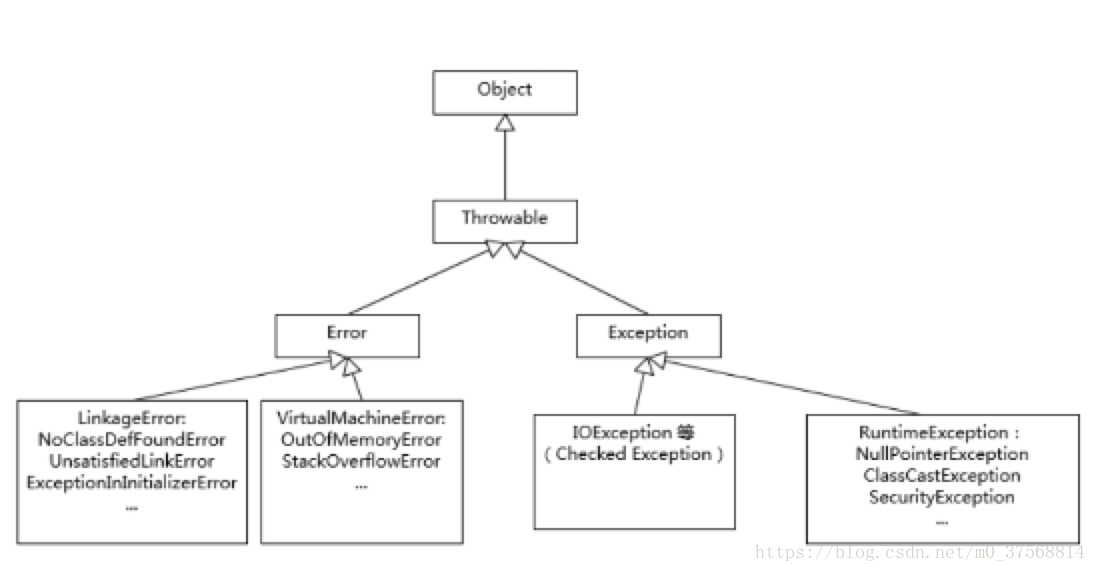
Exception和Error区别
Exception和Error都是继承了Throwable类,在java中只有Throwable类型的实例才可以被抛出(throw)或者捕获(catch),它是异常处理机制的基本组成类型。
Exception和Error体现了Java平台设计者对不同异常情况的分类。Exception是程序正常运行中,可以预料的意外情况,可能并且应该被捕获,进行相应处理。Error是指在正常情况下,不大可能出现的情况,绝大部分的Error都会导致程序(比如JVM自身)处于非正常、不可恢复状态。既然是非正常情况,所以不便于也不需要捕获,常见的比如OutOfMemoryError之类,都是Error子类。
Exception又分为检查型(checked)异常和非检查异常,可检查异常在源代码里必须显式地进行捕获处理,这是编译期检查的一部分。Error是Throwable不是Exception。
Java异常处理中,一般有两类异常。其一,通过throw语句,程序员在代码中人为抛出的异常;另一个是系统运行时异常,例如:被零除,空字符串,无效句柄等,对于这类异常,程序员可以避免它。为了彻底解决这种隐患,提高程序整体可靠性使用RuntimeException异常就是为了实现这样的功能。
非检查异常就是所谓的运行时异常,类似NullPointerException、ArrayIndexOutOfBoundsException之类,通常是可以编码避免的逻辑错误,具体根据需要来判断是否需要捕获,并不会在编译期强制要求。
java.lang.NoClassDefFoundError:出现这个异常,并不是说这个.class类文件不存在,而是类加载器试图加载类的定义时却找不到这个类的定义,实际上.class文件是存在的。Java虚拟机在编译时能找到合适的类,而在运行时不能找到合适的类导致的错误。
java.lang.ClassNotFoundException:根本原因是类文件找不到,缺少了 .class 文件,比如少引了某个 jar,解决方法通常需要检查一下 classpath 下能不能找到包含缺失 .class 文件的 jar。在编译的时候在classpath中找不到对应的类而发生的错误
异常处理两个基本原则:
1)尽量不要捕获类似Exception这样通用的异常,而是应该捕获特定异常,Thread.sleep()抛出的为InterruptedExcetption.
2)不要生吞(swallow)异常。生吞异常往往是基于假设这段代码可能不会发生,或者感觉忽略异常是无所谓的。如果我们不把异常抛出来,或者没有输出到日志之类,程序可能在后续代码以不可控的方式结束。没人能够轻易判断究竟是哪里抛出了异常,以及是什么原因产生了异常。
根据需要自定义异常,两点考虑:
1)是否需要定义成Checked Exception,因为这种类型设计的初衷是为了从异常情况恢复,作为异常设计者,我们往往有充足信息进行分类
2)在保证诊断信息足够的同时,也要考虑避免包含敏感信息,因为那样可能导致安全问题。如果我们看java的标准类库,可能注意到类似java.net.ConnectException,出错信息是类似“Connection refused”,而不包含具体的机器名,IP,端口等,一个重要考量就是信息安全。类似的情况在日志中也有。用户数据一般是不可以输出到日志里面的。
问题:对于反应式编程的异常该如何处理?
反应式编程是异步的,基于事件的,所以异常不能直接抛出,否则会引起程序崩溃,直接影响到对后续事件处理。
-
JAVA反射机制
反射:Java中的反射是一种强大的工具,它能够创建灵活的代码,这些代码可以在运行时装配,无须在组件之间进行链接。反射允许在编写与执行时,使程序代码能够介入装载到JVM中的类的内部信息,而不是源代码中选定的类协作的代码。
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
要想解剖一个类,必须先要获取到该类的字节码文件对象。而解剖使用的就是Class类中的方法.所以先要获取到每一个字节码文件对应的Class类型的对象。
详情参考:https://blog.csdn.net/sinat_38259539/article/details/71799078
-
Java传值与传引用
Java变量分两类:
1)基本类型变量(int,double,float,byte,boolean,char),Java是传值的副本
2)对于一切对象型变量,Java都是传引用的副本。
注意:String类型也是对象型变量,所以它必然是传引用副本。
StringBuffer是产生一块内存空间,相关的增删改操作都在其中进行。
引用副本指向的是对象的地址。通过引用副本找到地址并修改地址中的值,也就是修改了对象。
-
Java IO流

常用的方法如下:
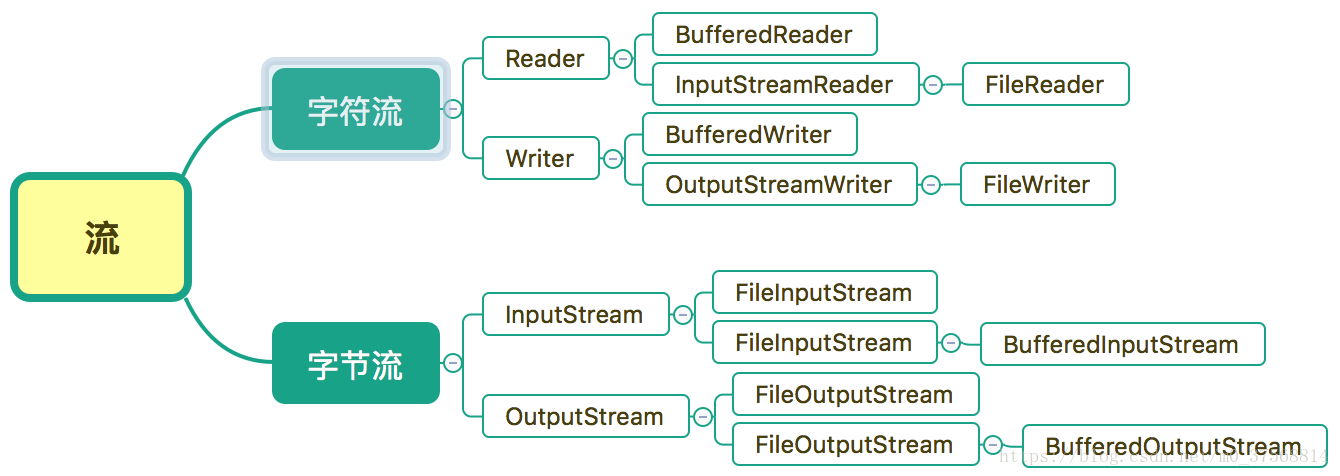
Java中的流,可以从不同的角度进行分类。
按照数据流的方向不同可以分为:输入流和输出流。
按照处理数据单位不同可以分为:字节流和字符流。
按照实现功能不同可以分为:节点流和处理流。
-
字节流
1:字节输入流
字节输入流的抽象基类是InputStream,常用的子类是 FileInputStream和BufferedInputStream。
1)FileInputStream
文件字节输入流:一切文件在系统中都是以字节的形式保存的,无论你是文档文件、视频文件、音频文件...,需要读取这些文件都可以用FileInputStream去读取其保存在存储介质(磁盘等)上的字节序列。
FileInputStream在创建时通过把文件名作为构造参数连接到该文件的字节内容,建立起字节流传输通道。
然后通过 read()、read(byte[])、read(byte[],int begin,int len) 三种方法从字节流中读取 一个字节、一组字节。
2)BufferedInputStream
带缓冲的字节输入流:上面我们知道文件字节输入流的读取时,是直接从字节流中读取的。由于字节流是与硬件(存储介质)进行的读取,所以速度较慢。而CPU需要使用数据时通过read()、read(byte[])读取数据时就要受到硬件IO的慢速度限制。我们又知道,CPU与内存发生的读写速度比硬件IO快10倍不止,所以优化读写的思路就有了:在内存中建立缓存区,先把存储介质中的字节读取到缓存区中。CPU需要数据时直接从缓冲区读就行了,缓冲区要足够大,在被读完后又触发fill()函数自动从存储介质的文件字节内容中读取字节存储到缓冲区数组。
BufferedInputStream 内部有一个缓冲区,默认大小为8M,每次调用read方法的时候,它首先尝试从缓冲区里读取数据,若读取失败(缓冲区无可读数据),则选择从物理数据源 (譬如文件)读取新数据(这里会尝试尽可能读取多的字节)放入到缓冲区中,最后再将缓冲区中的内容返回给用户.由于从缓冲区里读取数据远比直接从存储介质读取速度快,所以BufferedInputStream的效率很高。
2:字节输出流
字节输出流的抽象基类是OutputStream,常用的子类是 FileOutputStream和BufferedOutputStream。
-
字符流
*字符流中的对象融合了编码表,也就是系统默认的编码表。我们的系统一般都是GBK编码。
*字符流只用来处理文本数据,字节流用来处理媒体数据。
*数据最常见的表现方式是文件,字符流用于操作文件的子类一般是FileReader和FileWriter。
注意事项:
*写入文件后必须要用flush()刷新。
*用完流后记得要关闭流
*使用流对象要抛出IO异常
-
缓冲区
字符流的缓冲区:BufferedReader和BufferedWriter
* 缓冲区的出现是为了提高流的操作效率而出现的.
* 需要被提高效率的流作为参数传递给缓冲区的构造函数
* 在缓冲区中封装了一个数组,存入数据后一次取出
BufferedReader示例:
读取流缓冲区提供了一个一次读一行的方法readline,方便对文本数据的获取。
readline()只返回回车符前面的字符,不返回回车符。如果是复制的话,必须加入newLine(),写入回车符
newLine()是java提供的多平台换行符写入方法。
System.out: 对应的标准输出设备:控制台 //它是PrintStream对象,(PrintStream:打印流。OutputStream的子类)
System.in: 对应的标准输入设备:键盘 //它是InputStream对象
-
Java序列化
Java序列化是指把Java对象保存为二进制字节码的过程,Java反序列化是指把二进制码重新转换成Java对象的过程。序列化就是一种用来处理对象流的机制,所谓对象流也就是将对象的内容进行流化(将对象转换成二进制)。可以对流化后的对象进行读写操作,也可将流化后的对象传输于网络之间。序列化是为了解决在对对象流进行读写操作时所引发的问题。
那么为什么需要序列化呢?
第一种情况是:一般情况下Java对象的声明周期都比Java虚拟机的要短,实际应用中我们希望在JVM停止运行之后能够持久化指定的对象,这时候就需要把对象进行序列化之后保存。
class Parent implements Serializable {
private static final long serialVersionUID = -4963266899668807475L;
//serialVersionUID是源类的哈希值。如果类更新,例如域的改变,SUID会变化,这里有4个步骤:
//1.忽略SUID,相当于运行期间类的版本上的序列化和反序列上面没有差异。
//2.写一个默认的SUID,这就好像线程头部。告诉JVM所有版本中有着同样SUID的都是同一个版本。
//3.复制之前版本类的SUID。运行期间这个版本和之前版本是一样的版本。
//4.使用类每个版本生成的SUID。如果SUID与新版本的类不同,那么运行期间两个版本是不同的,并且老版本类序列化后的实例并不可以反序列成新的类的实例。
public int parentValue = 100;
}
class InnerObject implements Serializable {
private static final long serialVersionUID = 5704957411985783570L;
public int innerValue = 200;
}
class TestObject extends Parent implements Serializable {
private static final long serialVersionUID = -3186721026267206914L;
public int testValue = 300;
public InnerObject innerObject = new InnerObject();
}第二种情况是:需要把Java对象通过网络进行传输的时候。因为数据只能够以二进制的形式在网络中进行传输,因此当把对象通过网络发送出去之前需要先序列化成二进制数据,在接收端读到二进制数据之后反序列化成Java对象。
其实序列化的作用是能转化成Byte流,然后又能反序列化成原始的类。能在网络进行传输,也可以保存在磁盘中,有了SUID之后,那么如果序列化的类已经保存在本地中,中途你更改了类后,SUID变了,那么反序列化的时候就不会变成原始的类了,还会抛异常,主要就是用于版本控制。
序列化的实现:将需要被序列化的类实现Serializable接口,该接口没有需要实现的方法,implements Serializable只是为了标注该对象是可被序列化的,然后使用一个输出流(如:FileOutputStream)来构造一个ObjectOutputStream(对象流)对象,接着,使用ObjectOutputStream对象的writeObject(Object obj)方法就可以将参数为obj的对象写出(即保存其状态),要恢复的话则用输入流。
序列化操作一般用在网络传输的时候。表明这个被序列化的对象可以被“打碎”。为什么要“打碎”,就像把大的物体拆成小的更方便运输一个道理。
-
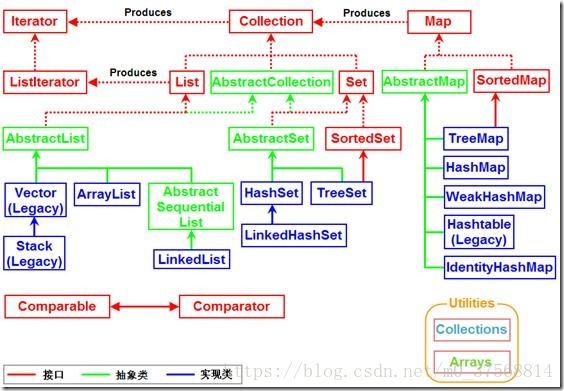
Java集合
Vector是Java早期提供的线程安全的动态数组,如果不需要线程安全,并不建议选择,毕竟同步需要额外的开销。Vector内部是使用对象数组来保存数据,可以根据需要自动的增加容量,当数组已满时,会创建新的数组,并拷贝原有数组数据。
ArrayList是应用更加广泛的动态数组实现,本身不是线程安全的,所以性能要好很多。与Vector近似,ArrayList也是可以根据需要调整容量,不过两者的调整逻辑不通,Vector在扩容时会提高1倍,而ArrayList增加50%。
LinkedList是Java提供的双向链表,不需要像上面两种那样调整容量,它也不是线程安全的。
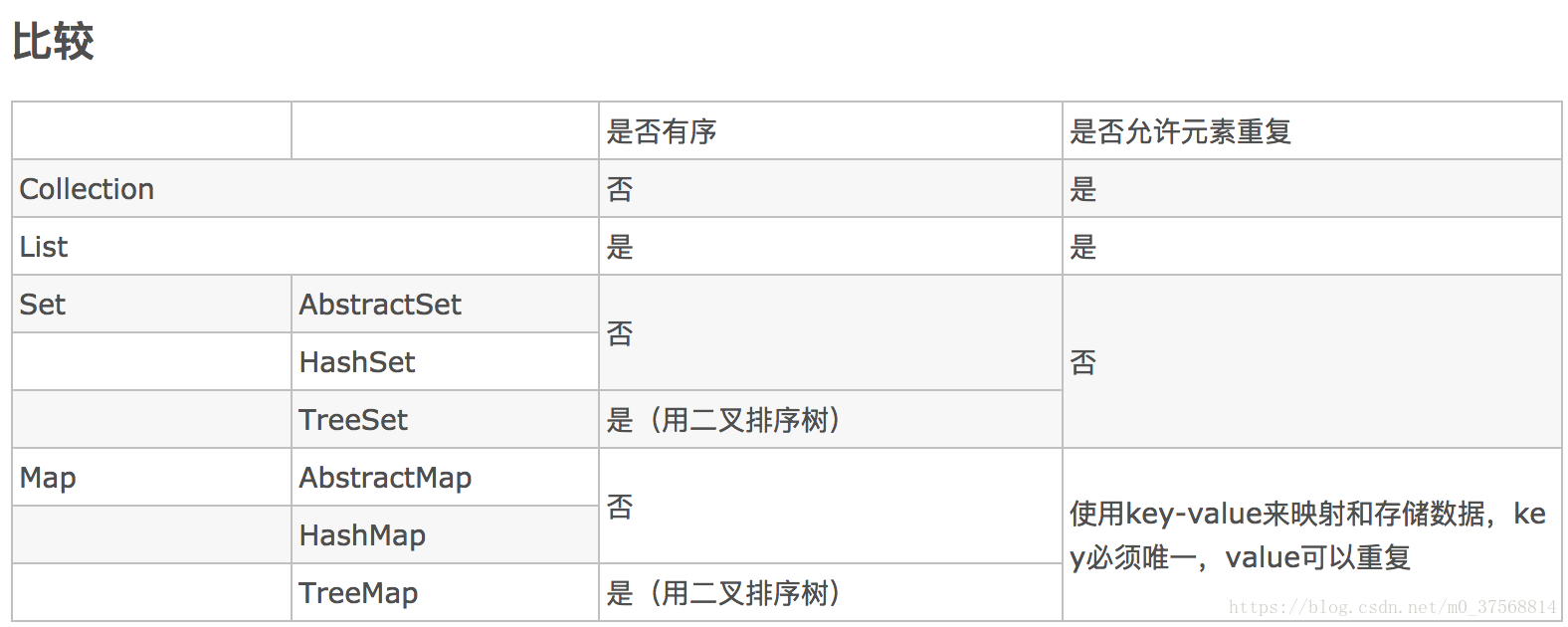
List,也就是我们前面介绍最多的有序集合,它提供了方便的访问、插入、删除等操作。
Set,Set是不允许重复元素的,这是和List最明显的区别,也就是不存在两个对象equals返回true。
Queue/Deque,则是Java提供的标准队列结构的实现,除了集合的基本功能,它还支持类似先入先出(FIFO)或者后入先出(LIFO)等特定行为。
TreeSet支持自然顺序访问,但是添加、删除、包含等操作要相对低效(logn).
HashSet则是利用hash算法,理想情况下,如果hash散列正常,可以提供常数时间的添加、删除、包含等操作,但是它不保证有序。
LinkedHashSet,内部构建了一个记录插入顺序的双向链表,因此提供了按照插入顺序遍历的能力,与此同时,也保证了常数时间的添加、删除、包含等操作,这些操作性能略低于HashSet,因此需要维护链表的开销。
以上的集合类,都不是线程安全的,但这并不代表这些集合完全不能支持并发编程的场景,在Collections工具类中,提供了一系列synchronized方法。比如:
static <T> List <T> synchronizedList(List<T> list)
我们完全可以利用类似方法来实现基本的线程安全集合:
List list = Collections.synchronized(new ArrayList());
它的实现,基本就是将每个基本方法,比如get、set、add之类,都通过synchronized添加基本的同步支持。注意这些方法创建的线程安全集合,都符合迭代时failfast行为,当发生意外的并发修改时,尽早抛出ConcurrentModificationException异常,以避免不可预计的行为。
对于原始数据类型,目前使用的是所谓双轴快速排序,是一种改进的快速排序算法
对于对象数据类型,目前则是使用TimSort,思想上也是一种归并和二分插入排序结合的优化排序算法。TimSort并不是Java的独创,简答说它的思路是查找数据集中已经排好序的分区,然后合并这些分区来达到排序的目的。
问:针对VIP用户业务优先处理的情况,该如何实现,使用什么数据结构
答:使用阻塞队列PriorityBlockingQueue。这是一个无界有序的阻塞队列,排序规则和之前介绍的PriorityQueue(优先队列,作用是能保证每次取出的元素都是队列中权值最小的--Java的优先队列每次取最小元素。这里牵涉到了大小关系,元素大小的评判可以通过元素本身的自然顺序,也可以通过构造时传入的比较器。通过堆实现,具体说是通过完全二叉树(complete binary tree)实现的小顶堆(任意一个非叶子节点的权值,都不大于其左右子节点的权值),也就意味着可以通过数组来作为PriorityQueue的底层实现)一致,只是增加了阻塞操作。同样的该队列不支持插入null元素,同时不支持插入非comparable的对象。它的迭代器并不保证队列保持任何特定的顺序,如果想要顺序遍历,考虑使用Arrays.sort(pq.toArray())。该类不保证同等优先级的元素顺序,如果你想要强制顺序,就需要考虑自定义顺序或者是Comparator使用第二个比较属性。
Map是广义Java集合框架中的另外一部分,HashMap是框架中使用频率最高的类型之一。
HashMap(不是线程安全的)是应用更加广泛的Hash表实现,不是同步的,支持null键和值等,通常情况下,HashMap进行put或者get操作,可以达到常数时间的性能,所以它是绝大部分利用键值对存取场景的首选,比如,实现一个用户ID和用户信息对应的运行时存储结构。
TreeMap则是基于红黑树的一种提供顺序访问的Map,和HashMap不同,它的get、put、remove之类操作都是O(logn)时间复杂度,具体顺序可以由指定的Comparator来决定,或者根据键的自然顺序来判断。
HashMap:没有顺序要求,性能表现非常依赖于hash码的有效性。hashCode和equals的一些基本约定:
1)equals相等,hashCode一定要相等
2)重写hashCode也要重写equals
3)hashCode需要保持一致性,状态改变返回的hash值仍然要一致。
4)equals的对称、反射、传递等特性
因为多线程环境下,使用Hashmap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。
-
如何保证集合是线程安全的?ConcurrentHashMap如何实现高效地线程安全?
Java提供了不同层面的线程安全支持。在传统集合框架内部,除了HashTable等同步容器,还提供了所谓的同步包装器(Synchronized Wrapper),我们可以调用Collections工具类提供的包装方法来获取一个同步包装器(如 Collections.SynchronizedMap),但是它们都是利用非常粗粒度的同步方式,在高并发情况下,性能比较低下。
更加普遍的选择是利用并发包提供的线程安全容器类,提供了:
1)各种并发容器,比如:ConcurrentHashMap、CopyOnWriteArrayList。
2)各种线程安全队列(Queue/Deque),如:ArrayBlockingQueue。SynchronousQueue
3)各种有序容器的线程安全版本等
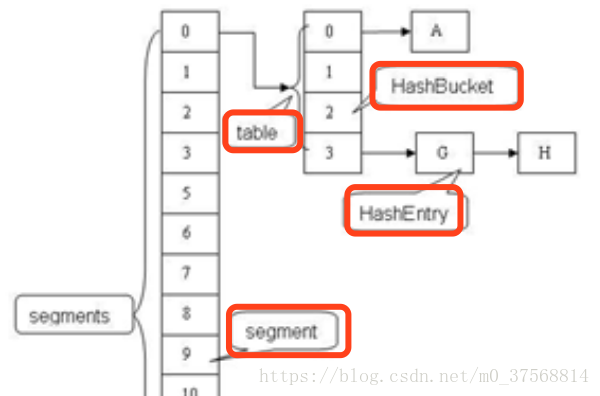
ConcurrentHashMap采用了分段锁(Segment)的设计,只有在同一个分段内才存在竞态关系,不同的分段锁之间没有锁竞争。相比于对整个Map加锁的设计,分段锁大大的提高了高并发环境下的处理能力。但同时,由于不是对整个Map加锁,导致一些需要扫描整个Map的方法(如size(), containsValue())需要使用特殊的实现,另外一些方法(如clear())甚至放弃了对一致性的要求。
ConcurrentHashMap中的分段锁个数,即Segment[]的数组长度。ConcurrentHashMap默认的并发度为16,但用户也可以在构造函数中设置并发度。当用户设置并发度时,ConcurrentHashMap会使用大于等于该值的最小2幂指数作为实际并发度(假如用户设置并发度为17,实际并发度则为32)。运行时通过将key的高n位(n = 32 – segmentShift)和并发度减1(segmentMask)作为与运算定位到所在的Segment。segmentShift与segmentMask都是在构造过程中根据concurrency level被相应的计算出来。
-
Java线程安全与并发
要保证线程安全,必须保证两点:共享变量的可见性、临界区代码访问的顺序性。
分析代码:
import java.util.concurrent.CountDownLatch;
public class Add {
private int count = 0;
public static void main(String[] args) {
CountDownLatch countDownLatch = new CountDownLatch(4);
Add add = new Add();
add.doAdd(countDownLatch);
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(add.getCount());
}
public void doAdd(final CountDownLatch countDownLatch) {
for (int i = 0; i < 4; i++) {
new Thread(new Runnable() {
public void run() {
for (int j = 0; j < 25; j++) {
count++;
}
countDownLatch.countDown();
}
}).start();
}
}
public int getCount() {
return count;
}
}1)给共享变量加上volatile关键字,就保证了可见性。
private volatile int count = 0;
volatile关键字,会在最终编译出来的指令上加上lock前缀,lock前缀的指令做三件事情
(1)防止指令重排序(这里对本问题的分析不重要,后面会详细来讲)
(2)锁住总线或者使用锁定缓存来保证执行的原子性,早期的处理可能用锁定总线的方式,这样其他处理器没办法通过总线访问内存,开销比较大,现在的处理器都是用锁定缓存的方式,在配合缓存一致性来解决。
(3)把缓冲区的所有数据都写回主内存,并保证其他处理器缓存的该变量失效。
既然保证了可见性,加上了volatile关键词,为什么还是无法得到正确的结果,原因是count++,并非原子操作,count++等效于如下步骤:
(1)从主内存中读取count赋值给线程副本变量:temp=count
(2)线程副本变量加1:temp=temp+1
(3)线程副本变量写回主内存:count=temp
就算是真的严苛的给总线加锁,导致同一时刻,只能有一个处理器访问到count变量,但是在执行第(2)步操作时,其他cpu已经可以访问count变量,此时最新运算结果还没刷回主内存,造成了错误的结果,所以必须保证顺序性。
那么保证顺序性的本质,就是保证同一时刻只有一个CPU可以执行临界区代码。这时候做法通常是加锁,锁本质是分两种:悲观锁和乐观锁。如典型的悲观锁synchronized、JUC包下面典型的乐观锁ReentrantLock。
-
垃圾收集
Java中使用被称为垃圾收集器的技术来监视Java程序的运行,当对象不再使用时,就自动释放对象所使用的内存。垃圾收集器是自动运行的,一般情况下,无须显式地请求垃圾收集器。程序运行时,垃圾收集器会不时检查对象的各个引用,并回收无引用对象所占用的内存。调用System类中的静态gc()方法可以运行垃圾收集器,但这样并不能保证立即回收指定对象。
对于频繁申请内存和释放内存的操作,还是自己控制一下比较好,但是System.gc()方法不一定适用,最好使用finalize强制执行或者写自己的finalize方法。
gc清理时的引用计数方式:当引用连接至新对象时,引用计数+1;当某个引用离开作用域或被设置为null时,引用计数-1,GC发现这个计数为0时,就回收其占用的内存。这个开销会在引用程序的整个生命周期发生,并且不能处理循环引用的情况。所以这种方式只是用来说明GC的工作方式,而不会被任何一种Java虚拟机应用。
-
内存管理
Java的内存管理就是对象的分配和释放问题。在Java中,程序员需要通过 new为每个对象申请内存空间(基本类型除外),所有的对象都在堆中分配空间。另外,对象释放由GC决定和执行的。在Java中内存的分配由程序完成,而内存的释放由GC完成。这种收支两条线的方法确实简化了程序员的工作。但同时,也加重了JVM的工作。这也是Java程序运行速度较慢的原因之一。因为GC为了能够正确释放对象,必须监控每一个对象的运行状态,包括对象的申请、引用、被引用、赋值等,GC都需要监控。
监视对象状态是为了更加准确、及时地释放对象,而释放对象的根本原则就是对象不再被引用。
补充:GC日志分析
监控GC在于判断JVM是否在良好高效地工作并且是否需要投入性能调优(主要包括应用程序优化与JVM参数优化),关注的数据大概有:
1. Mirror GC频率、持续时间以及回收内存量。
2. Major GC频率、持续时间、回收内存量以及 stop-the-world 耗时。
3. Heap 对象分配(导出.hprof文件分析,通常比较大)
加入-XX:+PrintGCDetails 参数则可以打印详细GC信息至控制台。参数-verbose:gc也是可以,但不够详细。
通过加入 -XX:+PrintGCDateStamps则可以记录GC发生的详细时间。
通过加入 -Xloggc:/home/XX/gc/app_gc.log 可以把GC输出至文件,这对长时间服务器GC监控很有帮助。以下列出一些参数大致打印的信息如下:
1)-verbose:gc: [GC 72104K->9650K(317952K), 0.0130635 secs]
2)-XX:+PrintGCDetails: [GC [PSYoungGen: 142826K->10751K(274944K)] 162800K->54759K(450048K), 0.0609952 secs] [Times: user=0.13 sys=0.02, real=0.06 secs]
3)-XX:+PrintGCDetails 加上-XX:+PrintGCDateStamps 参数则打印如下:
2015-12-06T12:32:02.890+0800: [GC [PSYoungGen: 142833K->10728K(142848K)] 166113K->59145K(317952K), 0.0792023 secs] [Times: user=0.22 sys=0.00, real=0.08 secs]可以看出,如果是想监控详细信息与GC发生时间,加上-XX:+PrintGCDateStamps -XX:+PrintGCDetails 参数会是一个比较好的选择。
首先来说明一段在各个GC中通用的字段含义说明:
1)142826K->10751K(274944K) 分别代表回收前、回收后以及总内存大小。
2)Times: user=0.46 sys=0.05, real=0.07 secs: user代表GC 需要的各个CPU总时间(各个CPU时间相加),sys代表回收器自身的行为所占用CPU时间,real则代表本次GC所耗费的真正耗时(在多核CPU中并行回收,它通常小于user) 。
1. Serial GC (-XX:+UseSerialGC)
下面是一段的Serial GC日志含义依次分解:
---------------------------
[GC[DefNew: 78656K->8704K(78656K), 0.0487492 secs] 135584K->80553K(253440K), 0.0488309 secs] [Times: user=0.05 sys=0.00, real=0.05 secs]
[Full GC[Tenured: 62546K->60809K(174784K), 0.1600120 secs] 85931K->60809K(253440K), [Perm : 38404K->38404K(65536K)], 0.1600814 secs] [Times: user=0.16 sys=0.00, real=0.16 secs]
---------------------------
1)其中的DefNew代表单线程回收yong generation。
2)紧跟后面的 78656K->8704K(78656K) 中的 78656K 代表young generation 回收前大小,8704K 代表回收后大小,括号中的78656K 代表young generation总大小(包含2个survivor)。
3)135584K->80553K(253440K) 则代表整个Heap(young+old)的变化与总量,含义参照前面所述(Perm也一样)。
4)Full GC 即代表 major GC, Tenured: 62546K->60809K(174784K)则表示 old generation变化及总量
2.Parallel GC 通过加入参数 -XX:+UseParallelGC 来指定
[GC [PSYoungGen: 88524K->10728K(274944K)] 133505K->61187K(450048K), 0.0374438 secs] [Times: user=0.08 sys=0.00, real=0.04 secs]
[Full GC [PSYoungGen: 10728K->0K(274944K)] [ParOldGen: 50459K->50210K(175104K)] 61187K->50210K(450048K) [PSPermGen: 38656K->38643K(77312K)], 0.3787131 secs] [Times: user=0.98 sys=0.02, real=0.38 secs]
--------------------------
1. PSYoungGen 代表并行回收 young generation
2. ParOldGen 代表并行回收 old generation.
3. PSPermGen 代表并行回收 Permanent generation. 其他的参数与前面解释的类似。
GC 分析主要点在于:
1. Mirror & Major GC 情况
2. Heap 对象分配
注: jstack 命令可以查询当前应用线程状态,可用于判断是否存在死锁、线程等待原因等问题。
GC查看工具:GCViewer
该工具用于统计加上参数如-XX:+PrintGCDetails -Xloggc:/home/xx.log 形成的LOG文件,从服务器上拿到文件后启动GCViewer打开
-
Java中的内存泄漏
内存泄漏就是存在一些被分配的对象,这些对象有两个特点:
1)对象是可达的,即在有向图中,存在通路可以与其相连;
2)对象是无用的,即程序以后不会再使用这些对象。
达到以上两个条件的对象可以判定为Java中的内存泄漏,这些对象不会被GC所回收,然而它们却占用内存。
为了确保能回收对象占用的内存,编程人员必须确保该对象不能到达。这通常是通过将对象字段设置为null或者从集合(collection)中移除对象而完成的。
Java内存泄漏分类:
长生命周期的对象持有短生命周期对象的引用就很可能发生内存泄漏,尽管短生命周期对象已经不再需要,但是因为长生命周期持有它的引用而导致不能被回收,这就是Java中内存泄漏的发生场景。具体主要有如下几大类:
1、静态集合类引起内存泄漏:
像HashMap、Vector等的使用最容易出现内存泄露,这些静态变量的生命周期和应用程序一致,他们所引用的所有的对象Object也不能被释放,因为他们也将一直被Vector等引用着。
示例:
Vector v = new Vector(10);
for (int i = 1; i < 100; i++) {
Object o = new Object();
v.add(o);
o = null;
}在这个例子中,我们循环申请Object对象,并将所申请的对象放入一个 Vector 中,如果我们仅仅释放引用本身(o=null),那么 Vector 仍然引用该对象,所以这个对象对 GC 来说是不可回收的。因此,如果对象加入到Vector 后,还必须从 Vector 中删除,最简单的方法就是将 Vector 对象设置为 null。
2、当集合里面的对象属性被修改后,再调用remove()方法时不起作用。
示例:
public static void main(String[] args)
{
Set<Person> set = new HashSet<Person>();
Person p1 = new Person("唐僧","pwd1",25);
Person p2 = new Person("孙悟空","pwd2",26);
Person p3 = new Person("猪八戒","pwd3",27);
set.add(p1);
set.add(p2);
set.add(p3);
System.out.println("总共有:"+set.size()+" 个元素!"); //结果:总共有:3 个元素!
p3.setAge(2); //修改p3的年龄,此时p3元素对应的hashcode值发生改变
set.remove(p3); //此时remove不掉,造成内存泄漏
set.add(p3); //重新添加,居然添加成功
System.out.println("总共有:"+set.size()+" 个元素!"); //结果:总共有:4 个元素!
for (Person person : set)
{
System.out.println(person);
}
}3、监听器
在java 编程中,我们都需要和监听器打交道,通常一个应用当中会用到很多监听器,我们会调用一个控件的诸如addXXXListener()等方法来增加监听器,但往往在释放对象的时候却没有记住去删除这些监听器,从而增加了内存泄漏的机会。
4、各种连接
比如数据库连接(dataSourse.getConnection()),网络连接(socket)和io连接,除非其显式的调用了其close()方法将其连接关闭,否则是不会自动被GC 回收的。对于Resultset 和Statement 对象可以不进行显式回收,但Connection 一定要显式回收,因为Connection 在任何时候都无法自动回收,而Connection一旦回收,Resultset 和Statement 对象就会立即为NULL。但是如果使用连接池,情况就不一样了,除了要显式地关闭连接,还必须显式地关闭Resultset Statement 对象(关闭其中一个,另外一个也会关闭),否则就会造成大量的Statement 对象无法释放,从而引起内存泄漏。这种情况下一般都会在try里面去的连接,在finally里面释放连接。
-
Java 内存分配策略
Java 程序运行时的内存分配策略有三种,分别是静态分配,栈式分配,和堆式分配,对应的,三种存储策略使用的内存空间主要分别是静态存储区(也称方法区)、栈区和堆区。
静态存储区(方法区):主要存放静态数据、全局 static 数据和常量。这块内存在程序编译时就已经分配好,并且在程序整个运行期间都存在。
栈区 :当方法被执行时,方法体内的局部变量(其中包括基础数据类型、对象的引用)都在栈上创建,并在方法执行结束时这些局部变量所持有的内存将会自动被释放。因为栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
堆区 : 又称动态内存分配,通常就是指在程序运行时直接 new 出来的内存,也就是对象的实例。这部分内存在不使用时将会由 Java 垃圾回收器来负责回收。
栈与堆的区别
在方法体内定义的(局部变量)一些基本类型的变量和对象的引用变量都是在方法的栈内存中分配的。当在一段方法块中定义一个变量时,Java 就会在栈中为该变量分配内存空间,当超过该变量的作用域后,该变量也就无效了,分配给它的内存空间也将被释放掉,该内存空间可以被重新使用。
堆内存用来存放所有由 new 创建的对象(包括该对象其中的所有成员变量)和数组。在堆中分配的内存,将由 Java 垃圾回收器来自动管理。在堆中产生了一个数组或者对象后,还可以在栈中定义一个特殊的变量,这个变量的取值等于数组或者对象在堆内存中的首地址,这个特殊的变量就是我们上面说的引用变量。我们可以通过这个引用变量来访问堆中的对象或者数组。
举例:
public class Sample {
int s1 = 0;
Sample mSample1 = new Sample();
public void method() {
int s2 = 1;
Sample mSample2 = new Sample();//s2和mSample2是方法体内的变量,存在于栈中
}
}
Sample mSample3 = new Sample();Sample 类的局部变量 s2 和引用变量 mSample2 都是存在于栈中,但 mSample2 指向的对象是存在于堆上的。
mSample3 指向的对象实体存放在堆上,包括这个对象的所有成员变量 s1 和 mSample1,而它自己存在于栈中。
结论
局部变量的基本数据类型和引用存储于栈中,引用的对象实体存储于堆中。—— 因为它们属于方法中的变量,生命周期随方法而结束。
成员变量全部存储于堆中(包括基本数据类型,引用和引用的对象实体)—— 因为它们属于类,类对象终究是要被new出来使用的。
Object基类方法:
1)clone()方法:创建并返回此对象的一个副本。
2)equals(Object obj)方法:指示某个其他对象是否与此对象“相等”。
3)finalize()方法:当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。
4)getClass()方法:返回一个对象的运行时类。
5)hashCode()方法:返回该对象的哈希值。
6)notify()方法:唤醒在此对象监视器上等待的单个线程。
7)notifyAll()方法:唤醒在此对象监视器上等待的所有线程。
8)toString()方法:返回该对象的字符串表示。
9)wait()方法:导致当前的线程等待,直到其他线程调用此对象的notify()方法或nitifyAll()方法。
10)wait(long timeout)方法:导致当前的线程等待,直到其他线程调用此对象的notify()方法或nitifyAll()方法或者超过指定的时间量。
11)wait(long timeout, int nanos)方法:导致当前的线程等待,直到其他线程调用此对象的notify()方法或nitifyAll()方法,或者其他某个线程中断当前线程,或者超过指定的时间量。
Java创建对象的几种方式:
1)用new语句创建对象,这是最常见的创建对象的方法
2)运用反射手段,调用java.lang.Class或者java.lang.reflect.Constructor类的newInstance()实例方法
3)调用对象的clone()方法
4)运用反序列化手段,调用java.io.ObjectInputStream对象的readObject()方法。
构造函数/构造代码块
构造方法作用:对对象进行初始化.
构造函数与普通函数的区别:
(1)一般函数是用于定义对象应该具备的功能。而构造函数定义的是,对象在调用功能之前,在建立时,应该具备的一些内容。也就是对象的初始化内容。
(2)构造函数是在对象建立时由jvm调用, 给对象初始化。一般函数是对象建立后,当对象调用该功能时才会执行。
(3)普通函数可以使用对象多次调用,构造函数就在创建对象时调用。
(4)构造函数的函数名要与类名一样,而普通的函数只要符合标识符的命名规则即可。
(5)构造函数没有返回值类型。
构造函数要注意的细节:
(1)当类中没有定义构造函数时,系统会指定给该类加上一个空参数的构造函数。这个是类中默认的构造函数。当类中如果自定义了构造函数,这时默认的构造函数就没有了。备注:可以通过javap命令验证。
(2)在一个类中可以定义多个构造函数,以进行不同的初始化。多个构造函数存在于类中,是以重载的形式体现的。因为构造函数的名称都相同。
构造代码块:
构造代码块作用:给所有的对象进行统一的初始化。
具体作用:
1.给对象进行初始化。对象一建立就运行并且优先于构造函数。
2.与构造函数区别
1): 构造代码块和构造函数的区别,构造代码块是给所有对象进行统一初始化, 构造函数给对应的对象初始化。 2): 构造代码块的作用:它的作用就是将所有构造方法中公共的信息进行抽取。
例如孩子一出生统一哭
/**
* Created by ZhangAnmy on 18/9/5.
*/
public class Test090501 {
public static void main(String[] args)
{
Boy b = new Boy();
b.run();
Boy b1 = new Boy("Anmy",18,"Female");
b1.info();
}
}
class Boy {
String name;
int age;
String gender;
// 构造代码块,给所有对象进行初始化。
{
System.out.println("cry....");
}
Boy() {
System.out.println("无参构造");
}
Boy(String n, int a, String g) {
System.out.println("有参构造");
this.name = n;
this.age = a;
this.gender = g;
}
public void run() {
System.out.println("Run...");
}
public void info()
{
System.out.println(name+":"+age+":"+gender);
}
}
结果:
cry....
无参构造
Run...
cry....
有参构造
Anmy:18:Female-
派生类
在java的继承关系中,新的类称为子类,也叫派生类。
继承是从已有的类中派生出新的类,新的类能吸收已有类的数据属性和行为,并能扩展新的能力,是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。
举例:class A extends B{//这里B叫做父类或者基类,A叫做子类或者派生类}
在无参构造器时, java会自动在派生类的构造器中插入对基类的构造器的调用。
当构造器有参数时,那就必须使用关键字super现实地编写调用基类构造器的代码,并且匹配适当的参数列表。
/**
* Created by ZhangAnmy on 18/9/5.
*/
public class Test090502 {
public static void main(String args[]){
new Student("zhangAnmy");
}
}
class Humans {
private String name;
Humans(String name){
System.out.println("我是叫"+name+"的人");
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
class Student extends Humans{
private String name;
Student(String name){
super(name);
System.out.println("我是HNU学生!");
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
结果:
我是叫zhangAnmy的人
我是HNU学生!解析:如果注释掉上面的super(name);将会报错。原因是派生类必须调用基类构造器。因为实例化派生类时,基类也会被实例化,如果不调用基类的构造器,基类将不会被实例化,所以派生类没有调用基类构造器会报错。
如果基类有一个无参的构造器,就算派生类不用super显示调用基类的构造函数,编译器也会自动去调用基类的无参构造函数。
派生类继承了基类的所有public和protected属性和方法,对于private的属性,可以使用get方式去获取值。
如果派生类定义了和基类一样的属性或方法,将覆盖基类的属性和方法。
class Student extends Humans{
//派生类中定义了和基类中一样的属性,覆盖基类中的属性值。
public String sex;
protected int age ;
private String name;
Student(String name ,int age,String sex){
super(name,age,sex);
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
//此时main函数中获取的值为null null 0
public static void main(String args[]){
Student s = new Student("zhangsan",18,"Male");
System.out.println(s.sex);
System.out.println(s.getName());
System.out.println(s.age);
}只有当派生类的属性也被实例化时,才会得到属性的值。
上面Student方法中,将派生类的属性实例化。
Student(String name ,int age,String sex){
super(name,age,sex);
this.sex = sex;
this.name = name;
this.age = age;
}注意!super必须在构造器的最前面,不然会报错。
-
析构函数
析构函数(destructor)与构造函数相反,当对象结束其生命周期时(例如对象所在的函数已调用完毕),系统会执行析构函数。在java中,我们一般用不到它,因为 java 有自动内存回收机制,无须程序员手动释放。java 对象析构时会调用 finalize() 方法。
虚函数----java类中普通成员函数就是虚函数。
/**
* Created by ZhangAnmy on 18/9/5.
*/
class A
{
public void Anmy()
{
System.out.println("Anmy in A is called");
}
}
class B extends A
{
public void Anmy()
{
System.out.println("Anmy in B is called");
}
}
public class TestVirtual0905 {
public static void main(String[] args)
{
A a = new A();
B b = new B();
A c;
c=a;
c.Anmy();
c=b;
c.Anmy();
}
}同样定义了一个基类指针(在java中应该叫引用)去指向不同的对象,可以发现同样可以实现多态。也就是说,java的普通成员函数(没有被static、native等关键字修饰)就是虚函数,原因很简单,它本身就实现虚函数实现的功能------多态。
-
java字节码
TestVirtual0905.java代码,用javac编译之后,编译器会生成相应的class字节码文件。通过java自带字节码查看器查看:
javap -verbose TestVirtual0905,结果如下:

上面字节码中,有许多指令,如aload_2、invokespecial、invokevirtual(注:aload指令是用来将数据加载到栈,invokespecial用来调用类的构造函数,invokevirtual用来调用普通函数)。
可以发现,对于A.Anmy的调用,java虚拟机所采用的调用方式就是invokevirtual。这些字节码的调用指令,是由《java虚拟机规范》规定的,在制定规范之初,大牛们就直接用invokevirtual来命名调用普通函数的指令。从字节码指令的命名上也可以看出,java中的普通成员函数就是虚函数。
-
重写(Overriding)---覆盖
(1)父类与子类的多态性,对父类的函数进行重新定义。如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写。在java中,子类可继承父类的方法,则不需要重新编写相同的方法。但有时子类并不想原封不动继承父类的方法,而是想做一定的修改,这就采用方法重写。方法重写又称方法覆盖。
重写的函数必须有一致的参数表和返回值。
静态方法不能被覆盖。
(2)若子类中的方法与父类的中的某一方法具有相同的方法名、返回类型和参数表,则新方法覆盖原有的方法。如需要父类的原有方法,可以使用super关键字。
(3)子类函数访问权限大于父类。
-
重载(Overloading)—与多态没有直接关系
(1)方法重载是让类以统一的方法处理不同类型数据的一种手段。多个同名函数同时存在,具有不同的参数个数(类型)。
(2)java的方法重载,就是在类中可以创建多个方法,他们具有相同的名字,但具有不同参数和不同的定义。调用方法时通过传递给他们不同的参数个数和参数类型来决定具体使用哪个方法。
(3)重载的时候,方法名要一样,但是参数类型和个数不一样,返回值类型可以相同也可以不同。无法以返回类型来作为重载函数的区分标准。
小练习:
public class NULL {
public static void haha() //static方法的调用是和类名绑定的,不借助对象进行访问
{
System.out.println("haha...");
}
public static void main(String[] args)
{
// ((NULL) null).haha(); //null值可以强制转换为任何java类型,但null转换后是无效对象,其返回值还是null.
NULL.haha();
}
}