转载自:【分布式】Zookeeper的Leader选举;ZooKeeper机制架构;谈谈对CAP定理的理解
一、Leader选举
1.1 Leader选举概述
Leader选举是保证分布式数据一致性的关键所在。当Zookeeper集群中的一台服务器出现以下两种情况之一时,需要进入Leader选举。
(1) 服务器初始化启动。
(2) 服务器运行期间无法和Leader保持连接。
下面就两种情况进行分析讲解。
1. 服务器启动时期的Leader选举
若进行Leader选举,则至少需要两台机器,这里选取3台机器组成的服务器集群为例。在集群初始化阶段,当有一台服务器Server1启动时,其单独无法进行和完成Leader选举,当第二台服务器Server2启动时,此时两台机器可以相互通信,每台机器都试图找到Leader,于是进入Leader选举过程。选举过程如下
(1) 每个Server发出一个投票。由于是初始情况,Server1和Server2都会将自己作为Leader服务器来进行投票,每次投票会包含所推举的服务器的myid和ZXID,使用(myid, ZXID)来表示,此时Server1的投票为(1, 0),Server2的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
(2) 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自LOOKING状态的服务器。
(3) 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行PK,PK规则如下
· 优先检查ZXID。ZXID比较大的服务器优先作为Leader。
· 如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器。
对于Server1而言,它的投票是(1, 0),接收Server2的投票为(2, 0),首先会比较两者的ZXID,均为0,再比较myid,此时Server2的myid最大,于是更新自己的投票为(2, 0),然后重新投票,对于Server2而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可。
(4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于Server1、Server2而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出了Leader。
(5) 改变服务器状态。一旦确定了Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING。
2. 服务器运行时期的Leader选举
在Zookeeper运行期间,Leader与非Leader服务器各司其职,即便当有非Leader服务器宕机或新加入,此时也不会影响Leader,但是一旦Leader服务器挂了,那么整个集群将暂停对外服务,进入新一轮Leader选举,其过程和启动时期的Leader选举过程基本一致。假设正在运行的有Server1、Server2、Server3三台服务器,当前Leader是Server2,若某一时刻Leader挂了,此时便开始Leader选举。选举过程如下
(1) 变更状态。Leader挂后,余下的非Observer服务器都会讲自己的服务器状态变更为LOOKING,然后开始进入Leader选举过程。
(2) 每个Server会发出一个投票。在运行期间,每个服务器上的ZXID可能不同,此时假定Server1的ZXID为123,Server3的ZXID为122;在第一轮投票中,Server1和Server3都会投自己,产生投票(1, 123),(3, 122),然后各自将投票发送给集群中所有机器。
(3) 接收来自各个服务器的投票。与启动时过程相同。
(4) 处理投票。与启动时过程相同,此时,Server1将会成为Leader。
(5) 统计投票。与启动时过程相同。
(6) 改变服务器的状态。与启动时过程相同。
1.2 Leader选举算法分析
在3.4.0后的Zookeeper的版本只保留了TCP版本的FastLeaderElection选举算法。当一台机器进入Leader选举时,当前集群可能会处于以下两种状态
· 集群中已经存在Leader。
· 集群中不存在Leader。
对于集群中已经存在Leader而言,此种情况一般都是某台机器启动得较晚,在其启动之前,集群已经在正常工作,对这种情况,该机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器而言,仅仅需要和Leader机器建立起连接,并进行状态同步即可。而在集群中不存在Leader情况下则会相对复杂,其步骤如下
(1) 第一次投票。无论哪种导致进行Leader选举,集群的所有机器都处于试图选举出一个Leader的状态,即LOOKING状态,LOOKING机器会向所有其他机器发送消息,该消息称为投票。投票中包含了SID(服务器的唯一标识)和ZXID(事务ID),(SID, ZXID)形式来标识一次投票信息。假定Zookeeper由5台机器组成,SID分别为1、2、3、4、5,ZXID分别为9、9、9、8、8,并且此时SID为2的机器是Leader机器,某一时刻,1、2所在机器出现故障,因此集群开始进行Leader选举。在第一次投票时,每台机器都会将自己作为投票对象,于是SID为3、4、5的机器投票情况分别为(3, 9),(4, 8), (5, 8)。
(2) 变更投票。每台机器发出投票后,也会收到其他机器的投票,每台机器会根据一定规则来处理收到的其他机器的投票,并以此来决定是否需要变更自己的投票,这个规则也是整个Leader选举算法的核心所在,其中术语描述如下
· vote_sid:接收到的投票中所推举Leader服务器的SID。
· vote_zxid:接收到的投票中所推举Leader服务器的ZXID。
· self_sid:当前服务器自己的SID。
· self_zxid:当前服务器自己的ZXID。
每次对收到的投票的处理,都是对(vote_sid, vote_zxid)和(self_sid, self_zxid)对比的过程。
规则一:如果vote_zxid大于self_zxid,就认可当前收到的投票,并再次将该投票发送出去。
规则二:如果vote_zxid小于self_zxid,那么坚持自己的投票,不做任何变更。
规则三:如果vote_zxid等于self_zxid,那么就对比两者的SID,如果vote_sid大于self_sid,那么就认可当前收到的投票,并再次将该投票发送出去。
规则四:如果vote_zxid等于self_zxid,并且vote_sid小于self_sid,那么坚持自己的投票,不做任何变更。
结合上面规则,给出下面的集群变更过程。

(3) 确定Leader。经过第二轮投票后,集群中的每台机器都会再次接收到其他机器的投票,然后开始统计投票,如果一台机器收到了超过半数的相同投票,那么这个投票对应的SID机器即为Leader。此时Server3将成为Leader。
由上面规则可知,通常那台服务器上的数据越新(ZXID会越大),其成为Leader的可能性越大,也就越能够保证数据的恢复。如果ZXID相同,则SID越大机会越大。
1.3 Leader选举实现细节
1. 服务器状态
服务器具有四种状态,分别是LOOKING、FOLLOWING、LEADING、OBSERVING。
LOOKING:寻找Leader状态。当服务器处于该状态时,它会认为当前集群中没有Leader,因此需要进入Leader选举状态。
FOLLOWING:跟随者状态。表明当前服务器角色是Follower。
LEADING:领导者状态。表明当前服务器角色是Leader。
OBSERVING:观察者状态。表明当前服务器角色是Observer。
二、ZooKeeper的保证
经过上面的分析,我们知道要保证ZooKeeper服务的高可用性就需要采用分布式模式,来冗余数据写多份,写多份带来一致性问题,一致性问题又会带来性能问题,那么就此陷入了无解的死循环。那么在这,就涉及到了我们分布式领域的著名的CAP理论,在这就简单的给大家介绍一下,关于CAP的详细内容大家可以网上查阅。
2.1 CAP理论
(1) 理论概述
分布式领域中存在CAP理论:
① C:Consistency,一致性,在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)。
② A:Availability,可用性,在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。系统具有好的响应性能。
③ P:Partition tolerance,分区容错性。以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择,也就是说无论任何消息丢失,系统都可用。
该理论已被证明:任何分布式系统只可同时满足两点,无法三者兼顾。 因此,将精力浪费在思考如何设计能满足三者的完美系统上是愚钝的,应该根据应用场景进行适当取舍。
(2) 一致性分类
一致性是指从系统外部读取系统内部的数据时,在一定约束条件下相同,即数据变动在系统内部各节点应该是同步的。根据一致性的强弱程度不同,可以将一致性级别分为如下几种:
① 强一致性(strong consistency)。任何时刻,任何用户都能读取到最近一次成功更新的数据。
② 单调一致性(monotonic consistency)。任何时刻,任何用户一旦读到某个数据在某次更新后的值,那么就不会再读到比这个值更旧的值。也就是说,可获取的数据顺序必是单调递增的。
③ 会话一致性(session consistency)。任何用户在某次会话中,一旦读到某个数据在某次更新后的值,那么在本次会话中就不会再读到比这个值更旧的值。会话一致性是在单调一致性的基础上进一步放松约束,只保证单个用户单个会话内的单调性,在不同用户或同一用户不同会话间则没有保障。
④ 最终一致性(eventual consistency)。用户只能读到某次更新后的值,但系统保证数据将最终达到完全一致的状态,只是所需时间不能保障。
⑤ 弱一致性(weak consistency)。用户无法在确定时间内读到最新更新的值。
(3)例子
假设我们用一台服务器A对外提供存储服务,为了避免这台服务器宕机导致服务不可用,我们又在另外一台服务器B上运行了同样的存储服务。每次用户在往服务器A写入数据的时候,A都往服务器B上写一份,然后再返回客户端。一切都运行得很好,用户的每份数据都存了两份,分别在A和B上,用户访问任意一台机器都能读取到最新的数据。
这时不幸的事情发生,A和B之间的网络断了导致A和B无法通信,也就是说网络出现了分区,那么用户在往服务器A写入数据的时候,服务器A无法将该数据写入到服务器B。这时,服务器A就必须要做出一个艰难的选择:
- 要么选择一致性(C)而牺牲可用性(A):为了保证服务器A和B上的数据是一致的,服务器A决定暂停对外提供数据写入服务,从而保证了服务器A和B上的数据是一致,但是牺牲了可用性。
注意:这里的可用性不是我们通常所说的高可用性(比如,服务器宕机导致服务不可用),而是指服务器虽然活着,但是却不能对外提供写入服务。 - 要么选择可用性(A)而牺牲一致性(C):为了保证服务不中断,服务器A先把数据写入到了本地,然后返回客户端,从而让客户端感觉数据已经写入了。这导致了服务器A和B上的数据就不一致了。
2.2 ZooKeeper与CAP理论
我们知道ZooKeeper也是一种分布式系统,它在一致性上有人认为它提供的是一种强一致性的服务(通过sync操作),也有人认为是单调一致性(更新时的大多说概念),还有人为是最终一致性(顺序一致性),反正各有各的道理这里就不在争辩了。然后它在分区容错性和可用性上做了一定折中,这和CAP理论是吻合的。ZooKeeper从以下几点保证了数据的一致性
① 顺序一致性
来自任意特定客户端的更新都会按其发送顺序被提交。也就是说,如果一个客户端将Znode z的值更新为a,在之后的操作中,它又将z的值更新为b,则没有客户端能够在看到z的值是b之后再看到值a(如果没有其他对z的更新)。
② 原子性
每个更新要么成功,要么失败。这意味着如果一个更新失败,则不会有客户端会看到这个更新的结果。
③ 单一系统映像
一 个客户端无论连接到哪一台服务器,它看到的都是同样的系统视图。这意味着,如果一个客户端在同一个会话中连接到一台新的服务器,它所看到的系统状态不会比 在之前服务器上所看到的更老。当一台服务器出现故障,导致它的一个客户端需要尝试连接集合体中其他的服务器时,所有滞后于故障服务器的服务器都不会接受该 连接请求,除非这些服务器赶上故障服务器。
④ 持久性
一个更新一旦成功,其结果就会持久存在并且不会被撤销。这表明更新不会受到服务器故障的影响。
三、ZooKeeper原理
3.1 原理概述
Zookeeper的核心是原子广播机制,这个机制保证了各个server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式和广播模式。
(1) 恢复模式
当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和server具有相同的系统状态。
(2) 广播模式
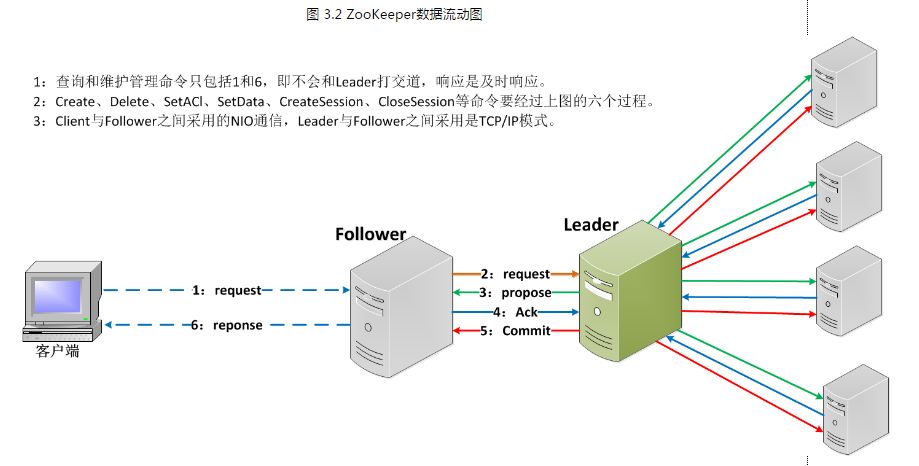
一旦Leader已经和多数的Follower进行了状态同步后,他就可以开始广播消息了,即进入广播状态。这时候当一个Server加入ZooKeeper服务中,它会在恢复模式下启动,发现Leader,并和Leader进行状态同步。待到同步结束,它也参与消息广播。ZooKeeper服务一直维持在Broadcast状态,直到Leader崩溃了或者Leader失去了大部分的Followers支持。
Broadcast模式极其类似于分布式事务中的2pc(two-phrase commit 两阶段提交):即Leader提起一个决议,由Followers进行投票,Leader对投票结果进行计算决定是否通过该决议,如果通过执行该决议(事务),否则什么也不做。

在广播模式ZooKeeper Server会接受Client请求,所有的写请求都被转发给领导者,再由领导者将更新广播给跟随者。当半数以上的跟随者已经将修改持久化之后,领导者才会提交这个更新,然后客户端才会收到一个更新成功的响应。这个用来达成共识的协议被设计成具有原子性,因此每个修改要么成功要么失败。