在求解区间第k个数的问题,除了划分树以外我们还可以使用另一种高效的方法 ------ 归并树。
1、算法描述
所谓归并树,就是利用线段树的建树过程,将归并排序的过程保存。(不会线段树:here,不会归并排序:here)。在说明归并树之前我们先看看这样的一个问题:
给定一个序列A[1...n],现在对该序列能够进行一个操作:Query(left, right, k):表示查询区间[left, right]的第k大树。一共进行m次的查询,要求你尽可能快的实现该操作一看到这个问题,我们可以立马得到一个朴素的算法:每次对区间[left, right]进行从小到大排序,直接输出第k大的值。我们稍稍分析一下这种朴素的算法所需的时间复杂度。首先每次对区间[left, right]进行排序所需的时间为O(nlogn)。一共进行m次查询,那么其总的时间复杂度为O(mnlogn)。第一眼看上去感觉这个算法貌似还不错,仔细分析就能发现,一旦m和n同时很大,那么这个算法就会很慢。那么此时,我们应该思考有么有更快的算法。显然是有的,他就是今天我们要讲的归并树(当然还有其他方法,下次再介绍)。
归并树简单来说就是线段树加归并排序,那么他们是怎么结合在一起的呢?假定现在A[1...7] = {7,6,....,1},我们先看看这个该序列归并排序的过程把:

我们在文章前也提到我们是利用线段树的存储结构来保存归并排序的过程,所以我们对照的看一下线段树的结构:
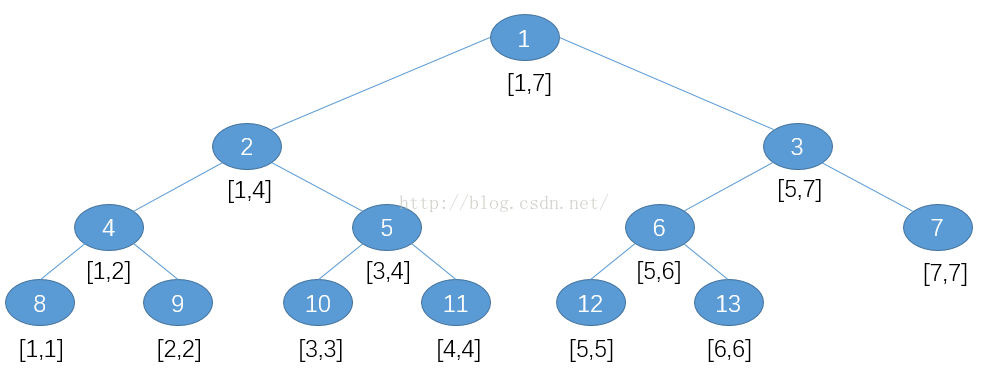
这么一对比我们会发现线段树的存储结构与归并排序的过程高度的一致,于是我们将两者合并:

通过上边的分析,我们不难得出归并树的建树过程,代码如下:
#define MAXN (1<<18)
#define DEEP 20
//sorted用来保存归并树的树体,a为输入序列
int sorted[DEEP][MAXN], a[MAXN];
void build(int deep, int lft, int rht){
if(lft == rht){
sorted[deep][lft] = a[lft];
return ;
}
int mid = (lft + rht) >> 1;
build(deep+1, lft, mid);
build(deep+1, mid+1, rht);
//进行归并
int i = lft, j = mid+1, k = lft;
while(i <= mid && j <= rht){
if(sorted[deep+1][i] <= sorted[deep+1][j])
sorted[deep][k++] = sorted[deep+1][i++];
else sorted[deep][k++] = sorted[deep+1][j++];
}
while(i <= mid) sorted[deep][k++] = sorted[deep+1][i++];
while(j <= rht) sorted[deep][k++] = sorted[deep+1][j++];
}通过代码我们发现,归并树采用层状结构了。原因很简单,因为要将归并排序的整个过程完完整整的保存下来,使用以前的树状结构显然不能满足。因为此时每一层都具有n个元素。现在我们已经完成了建树的工作,现在还有一个大问题就是查询。那么我们应该怎么查呢?一个区间的第k个数就是答案吗?只要稍微一思考就能发现这个思路不对。其实这时候我们可以使用一个比较“笨”的方法 --- 试一下呗。那么怎么试呢?我们用可以把[1,n]区间内的所有数都带入区间[left,right]中,看看那个数满足是这个区间的第k大数。显然我们这么做的话,我们可能会得到很多个数,假定我们从[1,n]区间内找到了n1个数且按照从小到大的顺序保存在key[n1]数组中。
那么此时我们怎么确定这n1个数,哪一个在区间[left,right]之中呢?一眼望去好像没什么方法貌似。那么作为笨的人,我们就采用一种比较笨的方法吧。假设x为区间内的第k大的数从key[n1]内任取一个数y。那么我们分类讨论:
①当y > x时,如果存在这种情况,那么y为区间[left,right]内第k+1大的数,显然y不可能出现在这n1个数。
②当y <= x时,这时候y都满足情况,那么根据①的分析,我们可以发现x是这n1个数中最大的那一个。
综上所述,当区间[1,n]内有多个数满足为区间[left,right]的第k大数时,值最大的那一个为目标值,即区间的第k大数。
经过上述分析,我们可以得到如下的代码:
//查询小于key的个数
//[qlft,qrht]为查询区间
//[lft, rht]为归并树上的区间
int query(int deep, int lft, int rht, int qlft, int qrht, int key){
if(qrht < lft || qlft > rht) return 0;
if(qlft <= lft && rht <= qrht)
return std::lower_bound(&sorted[deep][lft], &sorted[deep][rht]+1, key) - &sorted[deep][lft];
int mid = (lft + rht) >> 1;
return query(deep+1, lft, mid, qlft, qrht, key) + query(deep+1, mid+1, rht, qlft, qrht, key);
}
//二分查找在区间[qlft, qrht]上满足是第k大的数
//换而言之,即满足和比key小的有k个数的key
int solve(int n, int qlft, int qrht, int k){
int low = 0, high = n;
while(low+1 < high){
int mid= (low + high) >> 1;
//cnt 为小于 sorted[0][mid]的个数
int cnt = query(0, 0, n-1, qlft, qrht, sorted[0][mid]);
if(cnt <= k) low = mid; //[mid, high)
else high = mid; //[low, mid)
}
return sorted[0][low];
}2、时间复杂度
通过上述代码我们可以发现,影响归并树的时间复杂度的地方只有两处①建树②查询。且这两处的时间复杂度相互独立。我们先分析建树过程的时间复杂度吧,每一层都对n个数进行了操作,一用logn + 1层。于是建树的时间复杂度为O(nlogn)。我们再分析每一次查询操作的时间复杂度,①二分的对[1,n]内的数进行试,找出满足第k大的数②递归的对归并树上的区间进行进行查询③在每一个区间上查找比key小的元素个数。于是我们可以发现我们一共进行上次操作且每一次操作均为logn,故时间复杂度为O(logn*logn*logn)。一共进行m次查询那么总的时间复杂度为O(m*logn*logn*logn)。故归并树的最终时间复杂度为O(max(n*logn, m*logn*logn*logn))。
文章的最后,附上一道模板题POJ2104K-th Number。最后的最后附上解题代码,如下:
#include <cstdio>
#include <algorithm>
#define MAXN (100000)
#define DEEP (20)
using namespace std;
int sorted[DEEP][MAXN], a[MAXN];
void build(int deep, int lft, int rht){
if(lft == rht){
sorted[deep][lft] = a[lft];
return ;
}
int mid = (lft + rht) >> 1;
build(deep+1, lft, mid);
build(deep+1, mid+1, rht);
int p = lft, q = mid+1, k = lft;
while(p <= mid && q <= rht){
if(sorted[deep+1][p] <= sorted[deep+1][q])
sorted[deep][k++] = sorted[deep+1][p++];
else sorted[deep][k++] = sorted[deep+1][q++];
}
while(p <= mid) sorted[deep][k++] = sorted[deep+1][p++];
while(q <= rht) sorted[deep][k++] = sorted[deep+1][q++];
}
int query(int deep, int lft, int rht, int qlft, int qrht, int key){
if(qrht < lft || qlft > rht) return 0;
if(qlft <= lft && rht <= qrht)
return lower_bound(&sorted[deep][lft], &sorted[deep][rht]+1, key) - &sorted[deep][lft];
int mid = (lft + rht) >> 1;
return query(deep+1, lft, mid, qlft, qrht, key) + query(deep+1, mid+1, rht, qlft, qrht, key);
}
int solve(int n, int qlft, int qrht, int k){
int low = 1, high = n+1;
while(low+1 < high){
int mid= (low + high) >> 1;
int cnt = query(0, 1, n, qlft, qrht, sorted[0][mid]);
if(cnt <= k) low = mid;
else high = mid;
}
return sorted[0][low];
}
int main(){
int n, m;
scanf("%d%d", &n, &m);
for(int i = 1; i <= n; i++){
scanf("%d", &a[i]);
}
build(0, 1, n);
while(m--){
int qlft, qrht, k;
scanf("%d%d%d", &qlft, &qrht, &k);
printf("%d\n", solve(n, qlft, qrht, k-1));
}
return 0;
}