首先一张图对爬虫有一个宏观的感性的认识

Table of Contents
1.2 爬取网页的通用框架代码以及Requests库的异常处理
1.requests库
- 安装方法:pip install requests
- 官方说明文档:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
- 导入 Requests 模块:import requests
- 说明:如果你想要从头开始系统的学习python网络爬虫,建议按照本文顺序阅读,本文按照各种工具的使用顺序,从基本到高级进行介绍。
1.1 基本使用说明
1.七大基本方法
| requests.request() | 构造一个请求,是支持以下各方法的基础方法 |
| requests.get() |
获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的主要方法,对应于HTTP的GET |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改的请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML网页提交删除请求,对应于HTTP的DELETE |
request方法原型为:requests.request(method, url, **kwargs),其中method可以填HTTP1.1支持的7中方法,url为请求地址,之后的参数为可选参数,根据需要添加。比如需要在url后面添加参数,可以使用params参数。
r = requests.get(”http://www.baidu.com“)
kv = {"key1" : "value1", "key2" : "value2"}
r = requests.request('GET', 'http://www.baidu.com', params=kv)
print(r.url) // http://www.baidu.com?key1=value1&key2=value22.encoding和apparent_encoding
>>> r = requests.get(”http://www.baidu.com“)
>>> r.encoding
'ISO-8859-1'
>>> r.apparent_encoding
'utf-8'在这里需要理解response(在上面的代码中我们把通过Requests解析后的response存在r中)的编码
| 属性 | 说明 |
| r.encoding | 从HTTP相应的Header中猜测的响应编码方式 |
| r.apparent_encoding | 从内容中分析出的响应的编码方式(作为备用编码方式) |
如果通过r.text打印出的中文是乱码,考虑是编码方式的问题。在python3中直接打印的baidu主页返回的中文乱码,通过设置r.encoding = 'utf-8'即可解决这一问题。
3.status_code
获取响应信息的状态码
>>> r = requests.get(”http://www.baidu.com“)
>>> r.status_code
2004.request.headers
通过r.request.headers可以查看我们通过爬虫向服务器提交请求时的头部信息。
>>> r.request.headers
{'User-Agent': 'python-requests/2.18.4', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
5.request.url / url
通过r.request.url可以查看我们通过爬虫向服务器提交请求时的完整url。
url = 'http://www.baidu.com/s'
kv = {'wd' : 'Python'}
>>> r = requests.get(url, params = kv)
>>> r.url
'http://www.baidu.com/s?wd=Python'
>>> r.request.url
'http://www.baidu.com/s?wd=Python'1.2 爬取网页的通用框架代码以及Requests库的异常处理
| 异常 | 说明 |
| requests.ConnectionError | 网络连接错误异常,如DNS查询失败、拒绝连接等 |
| requests.HTTPError | HTTP错误异常 |
| requests.URLRequired | URL缺失异常 |
| requests.TooManyRedirects | 超过最大重定向次数,产生重定向异常 |
| requests.ConnectTimeout | 连接远程服务器 超时异常 |
| requests.Timeout | 请求URL时超时,产生超时异常 |
1.raise_for_status()方法
如果 HTTP 请求返回了不成功的状态码, Response.raise_for_status() 会抛出一个 HTTPError 异常。
若请求超时,则抛出一个 Timeout 异常。
若请求超过了设定的最大重定向次数,则会抛出一个 TooManyRedirects 异常。
2.爬取网页的通用代码框架
爬取网页明明直接爬就完事了,为什么还需要通用代码框架呢?这样是为了系统的规范的实现代码,进一步提高代码的健壮性和应对各种错误异常的能力。一般的代码框架是这样滴:
# python spider v0.1
import requests
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "Exception."
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))1.3 使用Requests库的健壮的最终的爬虫框架
一般来说,部分网站会过滤通过爬虫程序提交的请求,因此需要将我们的爬虫伪装一下,人为的设置一下User-Agent字段的内容。
# python spider v0.2
import requests
def getHTMLText(url):
try:
headers = {'User-Agent' : 'Mozilla/5.0'}
r = requests.get(url, timeout = 30, headers = headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "Exception."
if __name__ == "__main__":
url = "http://www.baidu.com"
print(getHTMLText(url))1.4 使用Requests库爬取指定图片并存储的示例程序
在这里我们首先实现保存一个已知URL的静态图片,通过前面提到的get方法得到数据之后,使用content属性,将得到的二进制数据存储在本地,即实现了保存图片的功能。
首先,在浏览器中确定一张图片的url,比如下面这个可爱滴定春狗狗;
图片资源的url最后面要是以图片格式结尾的才能保存成功:

然后开始编写程序:
import requests
imgURL = 'https://gss0.bdstatic.com/94o3dSag_xI4khGkpoWK1HF6hhy/baike/c0%3Dbaike80%2C5%2C5%2C80%2C26/sign=61ef47b6b119ebc4d4757ecbe34fa499/b3119313b07eca807de64134932397dda0448305.jpg'
imgPath = '~/Desktop/spider/test.jpg'
r = requests.get(imgURL)
with open(imgPath, 'wb') as f:
f.write(r.content)
f.close()运行程序后,到指定文件夹下查看一下呗:
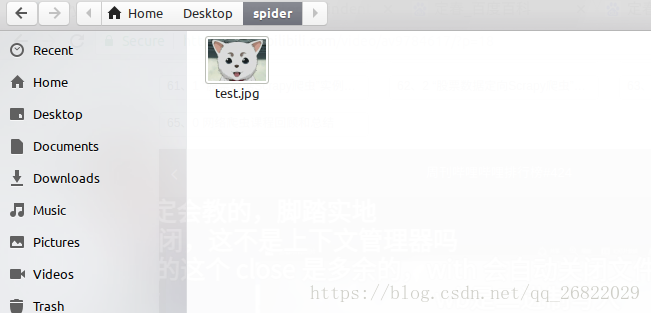
最后把上面的代码系统地重新写一下:
import os
import requests
imgURL = 'https://gss0.bdstatic.com/94o3dSag_xI4khGkpoWK1HF6hhy/baike/c0%3Dbaike80%2C5%2C5%2C80%2C26/sign=61ef47b6b119ebc4d4757ecbe34fa499/b3119313b07eca807de64134932397dda0448305.jpg'
imgRoot = '/home/howard/Desktop/spider/'
imgPath = imgRoot + imgURL.split('/')[-1]
try:
if not os.path.exists(imgRoot):
os.mkdir(imgRoot)
if not os.path.exists(imgPath):
r = requests.get(imgURL)
with open(imgPath, 'wb') as f:
f.write(r.content)
f.close()
print('文件保存成功')
else:
print('文件已存在')
except:
print('爬取失败')通过上面的代码,不仅仅可以下载图片,视频等资源都可以哦,老司机们有没有蠢蠢欲动啊~