一、项目源代码地址
本人Gitee项目地址:https://gitee.com/yuliu10/WordCount
二、PSP表格
| psp阶段 | 预估耗时 (分钟) |
实际耗时 (分钟) |
| 计划 | 30 | 10 |
| 估计这个任务需要多少时间 | 20 | 20 |
| 开发 | 600 | 660 |
| 需求分析 (包括学习新技术) | 40 | 60 |
| 生成设计文档 | 60 | 30 |
| 设计复审 (和同事审核设计文档) | 30 | 20 |
| 代码规范 | 10 | 0 |
| 具体设计 | 50 | 30 |
| 具体编码 | 500 | 600 |
| 基本功能实现 | 150 | 200 |
| 扩展功能实现 | 350 | 400 |
| 测试(自我测试,修改代码,提交修改) | 60 | 50 |
| 报告 | 300 | 300 |
| 代码复审 | 30 | 20 |
| 测试报告 | 60 | 120 |
| 计算工作量 | 5 | 5 |
| 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | ||
三、解题思路
在拿到题目之后,自己仔细阅读了老师给的任务,一开始觉得文本的行数、字数、单词数的统计没多大问题,后来在写代码的过程中,才发现难点在于命令行,因为自己以前并没有做过此类的练习,所以一片茫然,在搜集过很多资料以后才又继续开始了。
总结了一下自己在编程之前的思考以及解决方案:
♦用什么语言好呢?
自己学过C#,java,C,但是在涉及到命令行的解释是一大盲区,之前看到过某同学写的有关C语言main函数两个参数argc、argv的文章,于是就参考着用C语言写了。
♦如何获取命令行一长串的字符呢?
argc是指从命令行输入的参数个数,包括固定的本文件的路径argv[0],char* argv[]是一个指针数组,index是从0开始的,0存的是本文件的绝对路径,1存的是控制台输入的第一个参数,以此类推,因此控制台输入的命令就存在argv里面。
♦如何对获取到的命令行进行解析呢(即对哪个文件进行操作、有哪些不同的选项)?
根据习惯,命令行的格式是 wc.exe [para] <filename>,有三个选项可供选择,如何将不同数量的选择与相应的文件对应起来呢,最后想到的是用结构体(struct Node)来标注每一个file的各个状态(是否有-l选项、是否有-w选项、是否有-c选项、输入文件的名字、行数row、字符数characters、字数words),这样一来,节点Node里面包含了要处理的文件的所有信息,要处理某个选项就调用对应的写好的函数即可。
♦何处理多文件呢?
根据习惯,命令行的格式是wc.exe [para] <filename> [para] <filename>,用链表将不同的file节点串起来,每个文件是独立的,因此可以将文件名和文件要执行的操作封装在结构体里面。
参考链接:
有关main函数的两个命令行参数argc、argv详细解释参见:
https://blog.csdn.net/theLostLamb/article/details/79304203
原本以为在把基础功能做好以后,还能把扩展功能做一做,后来发现自己还是太年轻了,一个基础功能就快要了我的小命(我滴中秋啊啊啊)。
四、程序设计过程
大致思路就是先实现统计行数、单词数、字符数各个模块的功能,封装在每一个函数里面。这个比较简单,使用简单的累加就可以实现。后来碰到命令行的解释,就将之前的全部推翻了,用上了结构体。先获取命令行的参数,用 strcat函数对字符串进行拼接成commandStr,这个过程在main函数里面直接实现,其次是对commandStr进行解析,将文件的名字以及对应的选项提取出来放在一个Node里面,每一个文件为一个单独的Node,每个Node用链表串起来。Node有了以后,就可以根据里面保存的信息对文件进行相应的操作了!
设计模块包括:
- init():对Node节点进行初始化
- analysis():对获取的命令行字符串进行解析
- counLine():统计行数
- countWords():统计单词个数
- countChars():统计字符数
五、代码说明
根据我的开发过程,逐步阐述我的代码:
struct Node { //可供选择的三个选项 bool _l; bool _c; bool _w; char inputFile[100]; //作为输入的文件名 int row; int words; int character; struct Node *next;//指向下一个结点的指针 }; void init(struct Node *node) { node->_l = false; node->_c = false; node->_w = false; //将inputfile变为空(全0) memset(node->inputFile, 0, sizeof(node->inputFile)); node->row = 0; node->words = 0; node->character = 0; node->next = NULL; }
以上代码段为节点的定义和初始化,用一个节点来存放一个文件的所有信息,为每个节点的信息赋默认初值,以便于后面对命令行解析以后更新其中的状态。
void analysis(struct Node *Head, char commandStr[]) { init(Head); struct Node *cur; cur = Head; // 对这个字符串进行遍历,依次分析 for (int i = 0;; i++) { char c = commandStr[i]; // c是当前遍历到哪个字符了 if (c == 0) { // 读到'\0'代表读到了字符串末尾 return; } else if (c == ' ') { continue; } else if (c == '-') { // 如果读到了- // 就说明这是一个选项 // 那么我应该解析它后面的那一个字符,判断是哪种选项,是l,w还是c i++; // 先让i往后移一位,代表i指向-后面的参数 c = commandStr[i]; // 现在将选项读取出来了 // 接下来就是判断是哪种操作 if (c == 'l') { // 这里判断出了有统计行数这个选项 // 接下来应该是指定当前文件有这一操作 cur->_l = true; continue; } else if (c == 'w') { cur->_w = true; continue; } else if (c == 'c') { cur->_c = true; continue; } else if (c == 'o') { // 如果-后面是o,则表示要将结果保存在指定文件里面 // 根据规则,-o后面要紧跟一个输出的文件名 // -o res.txt -l i += 2; char path[100] = ""; for (int j = 0;; j++) { char ch = commandStr[i++]; if (ch == ' ') { break; } path[j] = ch; } // 把原来的result.txt擦出掉 memset(outputFile, 0, sizeof(outputFile)); // 把新的文件名放进去 strcpy(outputFile, path); } else { printf("after - must a para"); exit(-1); } } else { // 如果既不是0,又不是-, 也不是空格 // 那么就认为它是文件的开头 char path[100] = ""; // 遍历每一个字符,存放在path里面 for (int j = 0;; j++) { char ch = commandStr[i++]; if (ch == ' ') { break; } path[j] = ch; } // 将path复制到当前文件的输入文件中 strcpy(cur->inputFile, path); // 这一步结束以后 // 我已经得到了当前的文件名和这个文件要执行哪些操作 // 因此这个文件统计完毕,进行下一个文件的统计 // wc.exe -l -w -c file1.c -l -w file2.c -o res.txt if (commandStr[i] != 0) { if (commandStr[i + 1] != 'o') { // 如果字符串还没有结束,就new一个新的结点 // 并让当前节点指向行的节点 struct Node *node; node = (struct Node *)malloc(sizeof(struct Node)); init(node); cur->next = node; cur = node; } i--; } } } }
以上代码段是对命令行进行解释,是整个项目最核心的代码部分,对传进来的commandStr参数的每个字符一个一个进行遍历,如果遍历到‘\0’这个字符时,代表解析完毕,如果读到‘ ’空格继续解析,如果读到‘-’这个字符,判断下一个字符是‘l’、‘c’、‘w’中的哪一个选项,则对应给结构体中的响应变量做上标记,如若之后是‘o’字符,则后面要紧跟一个指定的输出文件,若后面没有指定文件,或指定文件不在当前文件下,就会报错“write file failure”,btw,如果没有“-o”选项,就默认输出到result.txt。如果遍历到的 字符既不是‘\0’,也不是‘ ’,也不是‘-’,就说明遍历到文件名了,将文件名保存下来,并将默认的输出文件更改成保存下来的文件名。继续往后遍历,还未碰到‘\0’字符表明还有其他文件,则创建新的节点,继续以上同样的操作。
void countLine(struct Node *node) { // 将当前正在处理的文件节点传进来,进行统计行数 // 如果没有读到文件末尾 // 就一直执行 while (!feof(rp)) { // 读取文件中的一个字符 if (fgetc(rp) == '\n') { node->row++; } } node->row++; rewind(rp); fprintf(wp, "%s,row:%d\n", node->inputFile, node->row); }
以上代码段是对文本的行数进行统计,并将统计到的数据输出在指定文件。
void countWords(struct Node *node) { // 统计单词个数 char c; int flag = 1; while (!feof(rp)) { c = fgetc(rp); if (flag == 1) { if (c != ' ') { node->words++; flag = 0; } } else if (c == ' ' || c == '\n') { flag = 1; } } rewind(rp); fprintf(wp, "%s,words:%d\n", node->inputFile, node->words); }
以上代码段是对文本的单词个数进行统计,并将统计到的数据输出在指定文件。
void countChars(struct Node *node) { //统计字符数 while (!feof(rp)) { if (fgetc(rp)) { node->character++; } } node->character--; rewind(rp); fprintf(wp, "%s,character:%d\n", node->inputFile, node->character); }
以上代码段是对文本的字符数进行统计,并将统计到的数据输出在指定文件。
int main(int argc, char *argv[]) { // 命令刚开始是在argv数组里面的 // 可以将命令拼接成一个字符串 // 把这个字符串传到一个解析函数里面解析一下 // 将解析的对应结果放在结构体里面 char commandStr[100] = ""; for (int i = 1; i < argc; i++) { strcat(commandStr, argv[i]); strcat(commandStr, " "); } // 将拼接好的字符串传到分析函数里面进行分析 // 分析函数需要接受命令字符串作为参数 // 另外还需要接受一个头结点 struct Node Head; analysis(&Head, commandStr); // 接下来要做的是打开文件 if ((wp = fopen(outputFile, "w+")) == NULL) { printf("write file failure"); exit(-1); } struct Node *cur; cur = &Head; while (cur != NULL) { if ((rp = fopen(cur->inputFile, "r")) == NULL) { printf("read file failure"); exit(-1); } if (cur->_l) { countLine(cur); } if (cur->_w) { countWords(cur); } if (cur->_c) { countChars(cur); } cur = cur->next; } return 0; }
以上代码段是整个代码的入口main函数,先获取命令行参数commandStr,创建一个当前节点cur,再调用analysis()函数对传进去的命令行commandStr进行解析,用节点进行标注,通过标注的信息打开对应的文件,根据不同的选项进行不同的统计操作,最后将数据输出到指定文件中。
以上是对各个代码段的解释说明,完整的代码链接:
https://gitee.com/yuliu10/WordCount
六、测试设计过程
在此次的项目中,我写了一个批处理文件对饿哦的项目进行测试,这样可以确保每个功能函数能够正常运行。众所周知,测试的高风险点包括代码中包含分支判定及循环的位置,因此,在测试中采用的覆盖方法覆盖到了所有程序代码语句,用以应对高风险点。以下是代码展示:
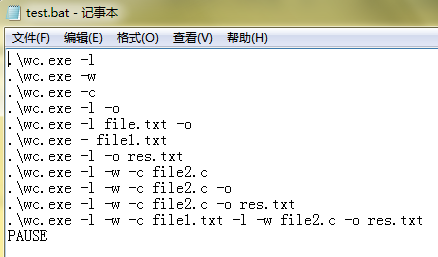
测试后的结果截图如下:
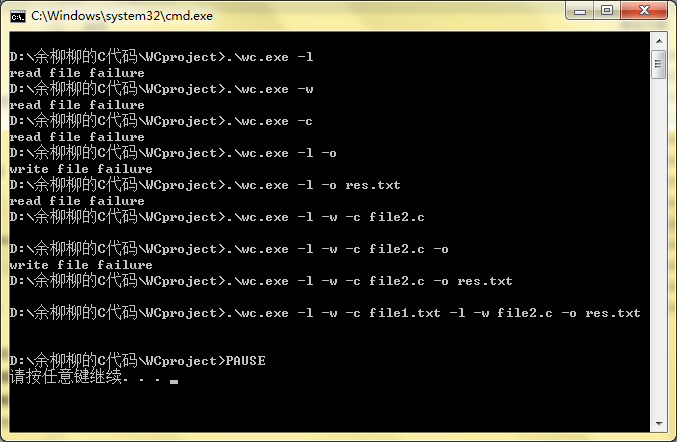
这里注明一下:我是用VC++6.0进行调试的,因为这个祖传的编译器太老了,在运行的之后不能从控制台输入参数。若要进行调试,具体在vc6.0中按如下步骤: 工程->设置->调试->程序变量,在此输入参数。
七、参考文献链接
有关博客的使用和排版,范飞龙老师的这篇博客:http://www.cnblogs.com/math/p/se-tools-001.html
邹欣老师在《构建之法》中设计的第一项个人作业:http://www.cnblogs.com/xinz/p/7426280.html
有关main函数的两个命令行参数argc、argv详细解释参见:https://blog.csdn.net/theLostLamb/article/details/79304203
如何在VC++6.0环境中运行带参main函数:https://blog.csdn.net/weiqiang_huang/article/details/17124255