版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_32635069/article/details/81259537
- offset的保存位置
在Kafka0.9版本之前消费者保存的偏移量是在zookeeper中/consumers/GROUP.ID/offsets/TOPIC.NAME/PARTITION.ID。新版消费者不再保存偏移量到zookeeper中,而是保存在Kafka的一个内部主题中“__consumer_offsets”,该主题默认有50个分区,每个分区3个副本,分区数量有参数offset.topic.num.partition设置。通过消费者组ID的哈希值和该参数取模的方式来确定某个消费者组已消费的偏移量保存到__consumer_offsets主题的哪个分区中 - 为什么要自助管理offset
如果是使用spark-streaming-kafka-0-10,那么我们建议将enable.auto.commit设为false。这个配置只是在这个版本生效,enable.auto.commit如果设为true的话,那么意味着offsets会按照auto.commit.interval.ms中所配置的间隔来周期性自动提交到Kafka中。在Spark Streaming中,将这个选项设置为true的话会使得Spark应用从kafka中读取数据之后就自动提交,而不是数据处理之后提交,这不是我们想要的。所以为了更好地控制offsets的提交,我们建议将enable.auto.commit设为false。 - 如何自主管理
自主管理offset,就是选取第三方存储系统(HDFS、HBase、zookeeper等)
HDFS:有官方提供,checkpoint(),有一个重要的弊端:在HDFS备份后发生产品升级或代码改动操作,将无法还原已备份的offset,所以正式产品没人用它
HBase和zookeeper比较常用,保存对应topic下每个分区的offset,但是要注意当topic的新增分区的可能 - 新版本的方法
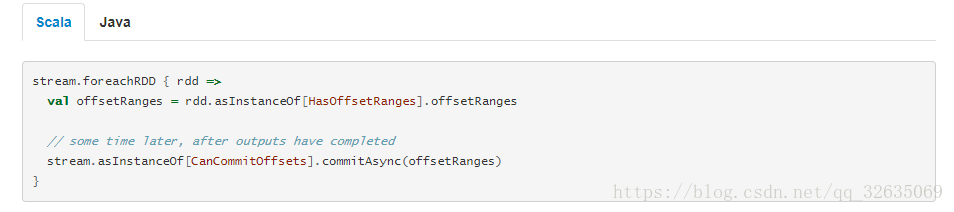
由kafka自身保存,这个方法也是官方推荐的
- 应用
使用第三方管理offset适用于需要对消息消费,offset的值有严格监控的场景 - 参考
http://blog.51cto.com/littledevil/2148207?source=dra
https://www.jianshu.com/p/ef3f15cf400d
http://spark.apache.org/docs/2.2.0/streaming-kafka-0-10-integration.html