Evaluating Fast Algorithms for Convolutional Neural Networks on FPGAs
- Liqiang Lu 北京大学高能效计算与运用中心,商汤科技
- 梁云 北京大学高能效计算与运用中心
- 肖倾城 北京大学高能效计算与运用中心
- Shengen Yan 香港中文大学信息工程系,商汤科技
摘要 近年来,卷积神经网络(CNNs)已被广泛用于计算机视觉任务。由于其高性能,高能效和可重新配置性,FPGA已被充分探索为CNN的有前途的硬件加速器。然而,基于传统卷积算法的现有FPGA解决方案通常受到FPGA的计算能力(例如,DSP的数量)的限制。在本文中,我们证明了快速Winograd算法可以显着降低算术复杂度,并提高CNN在FPGA上的性能。我们首先提出了一种用于在FPGA上实现Winograd算法的新颖架构。我们的设计采用行缓冲结构,有效地重用不同tiles之间的feature map数据。我们还有效地pipeline Winograd PE engine, 并通过并行化启动多个PE。同时,还有一个复杂的设计空间可探索。我们提出了一种分析模型来预测资源使用情况和性能原因。然后,我们使用该模型来指导快速设计空间探索。使用最先进的CNN的实验证明了FPGA的最佳性能和能效。在Xilinx ZCU102平台上,我们实现了卷积层平均1006.4 GOP / s,整个AlexNet平均达到854.6 GOP / s,卷积层平均达到3044.7 GOP / s,整体VGG16平均达到2940.7 GOP / s。
1. INTRODUNCTION
深度卷积神经网络(CNN)已经在各种计算机视觉任务中取得了优秀的表现,包括图像分类,目标检测和语义分割。 CNN的重大精度提高是以巨大的计算复杂性为代价的,因为它需要对feature map中的所有区域进行全面评估。 面对如此巨大的计算压力,已采用GPU,FPGA和ASIC等硬件加速器来加速CNN。 在这些加速器中,由于其高性能,高能效和可重新编程,FPGA已成为一种很有前景的解决方案。 更重要的是,使用C或C ++的高级综合(HLS)极大地降低了FPGA的编程难度,并提高了生产率。
CNN通常涉及多层,其中一个层的输出feature map是下一层的输入feature map。先前的研究表明,优秀的CNN的计算主要由卷积层决定。使用传统的卷积算法,通过使用多个乘法累加运算来单独计算输出feature map中的每个元素。虽然使用这种算法的CNN的先前FPGA解决方案已经证明了初步成功,但是当算法本身可以更高效时,可以实现更高的效率。在本文中,我们展示了使用Winograd算法的卷积如何能够显着降低算术复杂度,并提高CNN在FPGA上的性能。使用Winograd算法,通过利用它们之间的结构相似性,一起生成输出特征映射中的元素块。这有助于通过减少所需的乘法次数来减少算术复杂性。已经证明,快速Winograd算法可用于推导具有小滤波器的CNN的有效算法。
更重要的是,CNN的当前趋势是采用小型滤波器的更深层拓扑。 例如,除了第一层外,Alexnet的所有卷积层都采用3×3和5×5滤波器; VGG16仅使用3×3滤波器。 这开启了使用Winograd算法有效实现CNN的机会。 然而,尽管在FPGA上使用Winograd算法很有吸引力,但仍存在一些问题。 首先,设计不仅要最小化内存带宽要求,还要使内存吞吐量与计算引擎相匹配,这一点至关重要。 其次,将Winograd算法映射到FPGA时存在很大的设计空间。 很难推断哪些设计会改善或损害性能。
在本文中,我们设计了一个行缓冲结构来缓存Winograd算法的feature map。 这允许不同tiles在卷积操作进行时重用数据。 Winograd算法的计算涉及通用矩阵乘法(general purpose matrix multiple, GEMM)和逐元乘法(element-wise multiplication, EWMM)的混合矩阵变换。 然后,我们设计了一个高效的Winograd PE,并通过并行化启动多个PE。 最后,我们开发分析模型来估计资源使用情况,并预测性能。 我们使用这些模型来探索设计空间,并确定最佳设计参数。
本文作出以下贡献。
- 我们提出了一种在FPGA上使用Winograd算法有效实现CNN的架构。 这种架构采用行缓冲结构,Winograd PE的general purporse和element-wise矩阵乘法,以及PE并行化。
- 我们开发分析资源和性能模型,并使用模型探索设计空间来确定最佳参数。
- 我们对包括AlexNet和VGG16在内的最先进的CNN进行严格的技术验证。
使用最先进的CNN的实验证明了CNN在FPGA上的最佳性能和能量效率。 在Xilinx ZCU102平台上,我们实现了AlexNet卷积层平均1006.4 GOP / s和整体854.6 GOP / s;VGG16卷积层平均为3044.7 GOP / s,整体平均为2940.7 GOP / s。 这使得AlexNet的能效为36.2 GOP / s / W,VGG16的能效为124.6 GOP / s / W。
2. BACKGROUND
A. CNN Basics
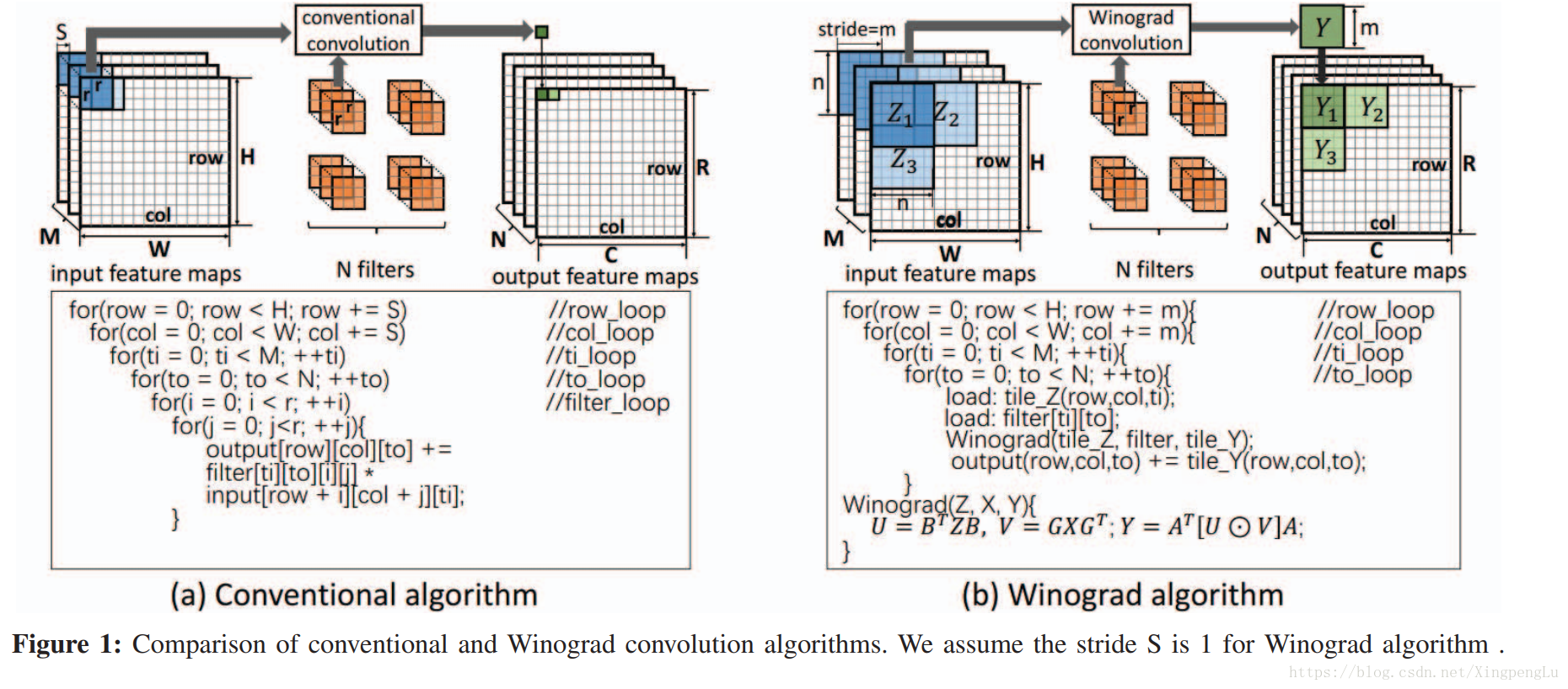
通常,CNN由一系列层组成,每层又由输入feature map,filters和输出feature map组成。 在这些层中,卷积层占主要计算量。 CNN是离线训练的,而FPGA主要用于加速推理阶段。 图1(a)给出了典型的卷积层及其使用传统算法的实现。 利用传统的卷积算法,output feature map的每个元素通过将相应的输入特征数据与filters相乘和累加来单独计算。
B. Winograd Algorithm
CNN的趋势正朝着更小的filters拓展。 传统的卷积算法是通用的,但效率较低。 作为替代方案,使用Winograd最小滤波算法可以更有效地实现卷积。
让我们用 r-tap FIR滤波器表示计算m输出的结果为 F(m, r) 。F(2, 3) 的传统算法需要2×3 = 6次乘法。 Winograd算法以下列方式计算 F(2, 3) :
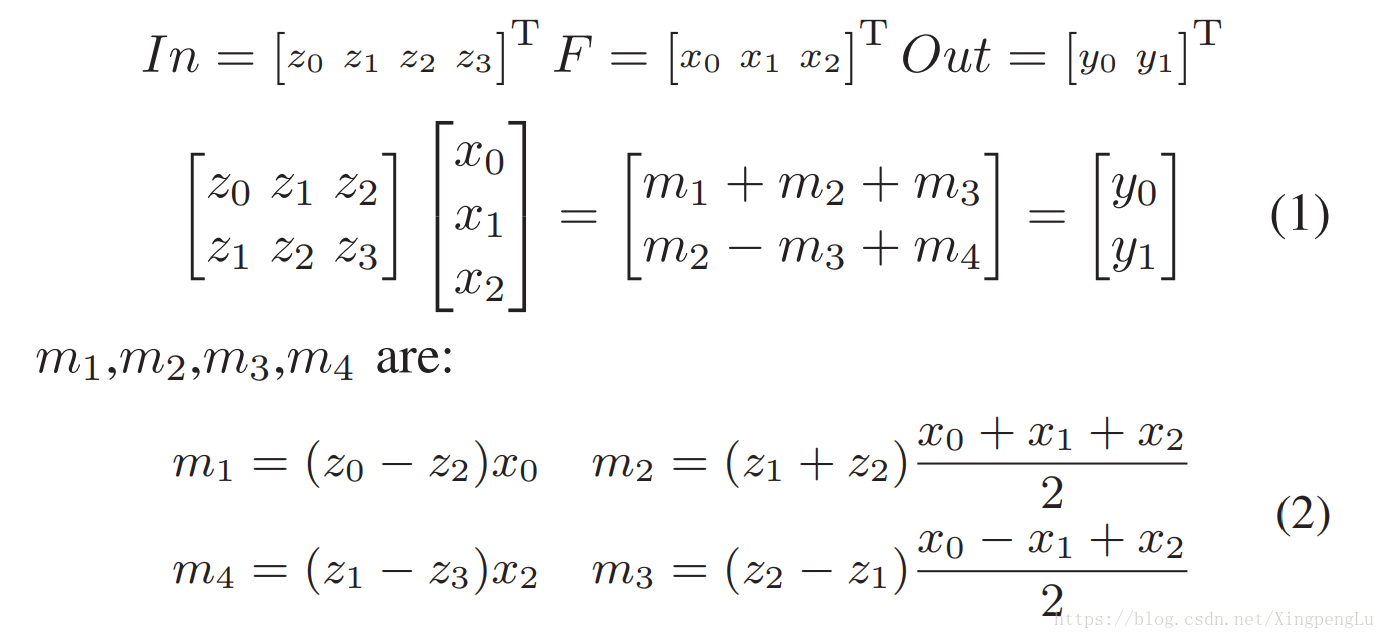
计算m1-m4只需要4次乘法。使用Winograd算法的一维卷积可以使用如下的变换矩阵A,B和G来表示。
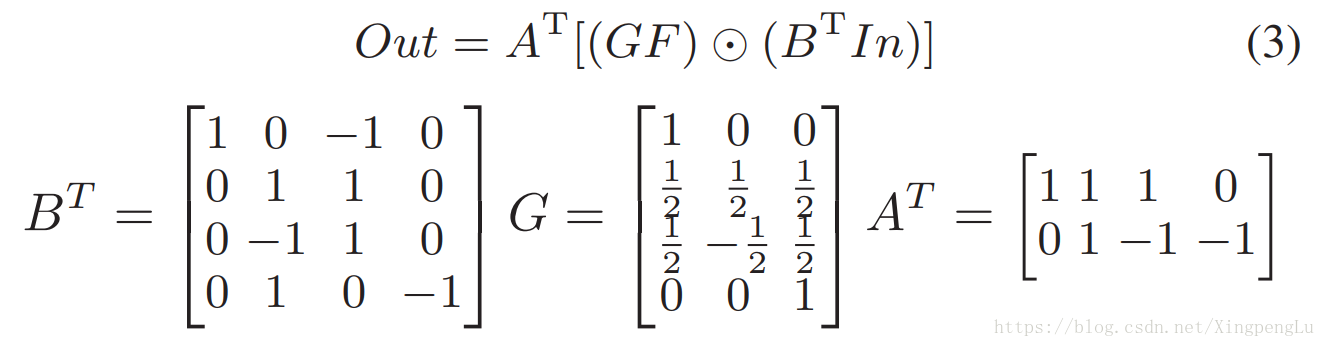

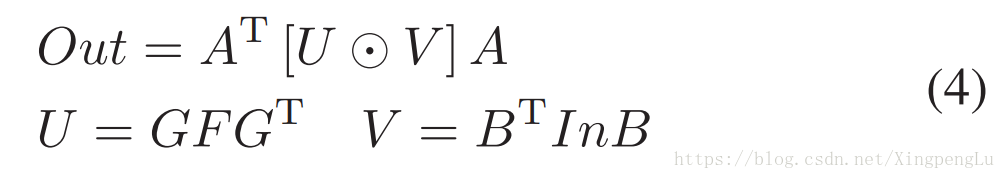
通过定义变换矩阵A,B和G,我们可以将2-D Winograd算法表示为mixed general purpose和element-wise矩阵乘法,如图1(b)所示。 一旦确定了 n 和 r ,就离线生成变换矩阵。在我们的实现中,与变换矩阵中的常数的乘法被转换为移位操作(如×1/2),这更有效率,并且仅在FPGA上使用LUT和触发器(Flip Flops)。
如图1(b)所示,每次调用Winograd算法时,它都会生成一个大小为m×m的tile。 乘法次数由等式4中
3. ARCHITETURE DESIGN
在本文中,我们提出了一种基于二维Winograd算法的CNN的FPGA加速器设计。通过利用传统卷积算法,其中输出feature map中的每个元素被单独计算,Winograd算法可以通过利用输入feature map的相同tile中的元素之间的结构相似性来一起生成输出feature map的tile。 更清楚的是,给定 n×n 大小的输入tile和 r×r 的filter,我们采用Winograd算法生成大小为 m×m(n = m + r-1) 的输出feature map。 为了导出输出feature map的下一个 m×m tile ,我们只需要将输入 tile 滑动 m ,并执行相同的Winograd计算,如图1(b)所示。
在FPGA上设计和实现基于Winograd算法的CNN加速器时会出现一些挑战。首先,卷积层具有高存储器带宽需求。我们观察到相邻的 tile 在水平和垂直方向上共享输入 feature map 数据。我们利用这一观察来设计行缓冲区以最大化数据重用(第3-B节)。其次,与传统的卷积算法不同,Winograd算法一次生成输出 feature map tile 。这要求输入 tiles 和 filters 中的所有元素在Winograd转换开始之前同时准备就绪。我们为Winograd算法设计了一个高效的PE engine(第3-C节),并通过并行化实例化多个PE(第3-D节)。第三,不同的实现参数( tile 大小,并行化程度)形成具有多维度资源和带宽约束的大型设计空间。我们提出了一种用于性能预测的分析模型,并利用它来有效地探索空间(第3-E节)。
A. Architecture Overview
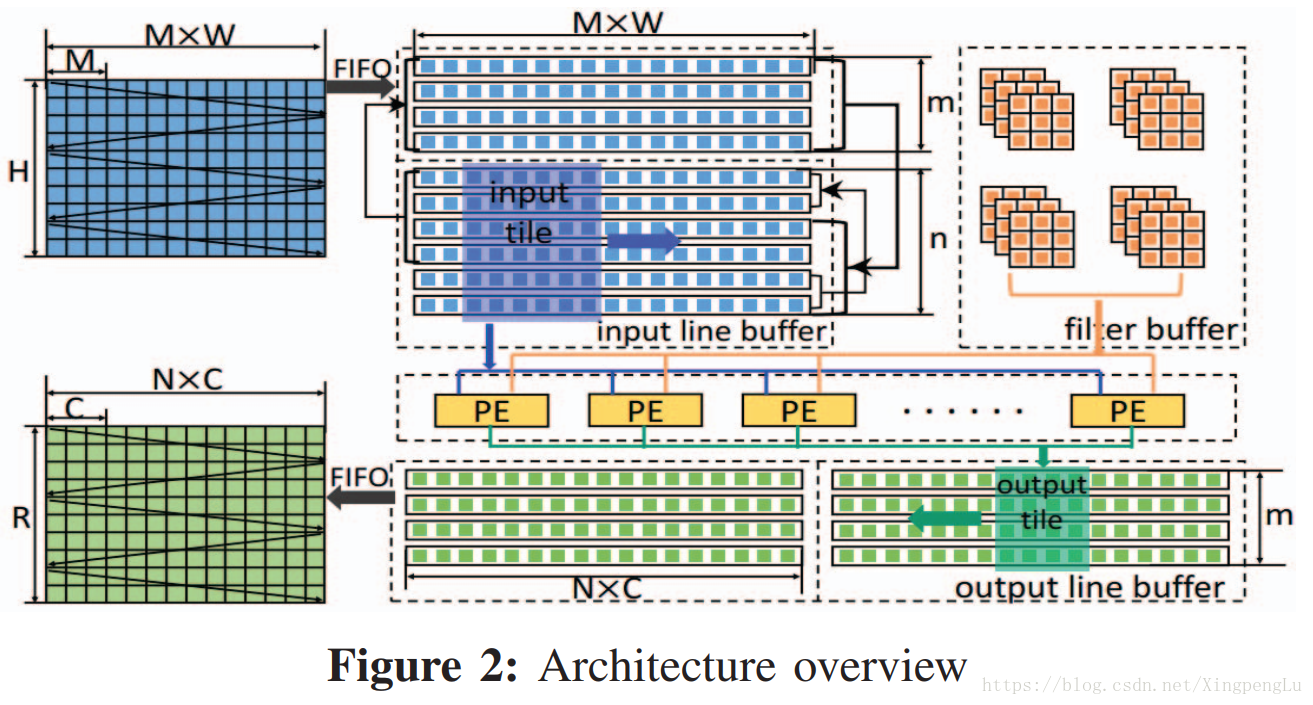
图2显示了基于FPGA上的Winograd算法的卷积层的体系结构概述。我们在相邻 tiles 的 feature map 中识别数据重用机会。为此,我们自然地实现行缓冲。存在多个输入 feature map 通道(M),如图1所示。行缓冲器的每一行在所有通道上存储相同的行。Winograd PE从行缓冲区中获取数据。具体地,给定 n×n 输入tile,Winograd PE将生成 m×m 输出tile。我们通过并行化多个通道的处理来启动一系列PE。最后,我们使用双缓冲区来重叠数据传输和计算。所有输入数据(例如, 输入 feature map ,filters)最初都存储在外部存储器中。输入和输出 feature map 通过FIFO传输到FPGA。但是,随着网络更深,过滤器的大小也会显着增加。将所有 filters 加载到片上存储器是不切实际的。在我们的设计中,我们将输入和输出通道分成几组。每个组仅包含一部分 filters 。我们在需要时按组加载 filters 。在下文中,为了易于说明我们假设只有一组。