今天上午爬b站,下午头条,晚上优酷,头条的视频和优酷爬取差不多,都是在播放页面中给出连接,只需要获取到那个连接就行,根据下午爬取头条的经验,我们直接上selenium来爬取
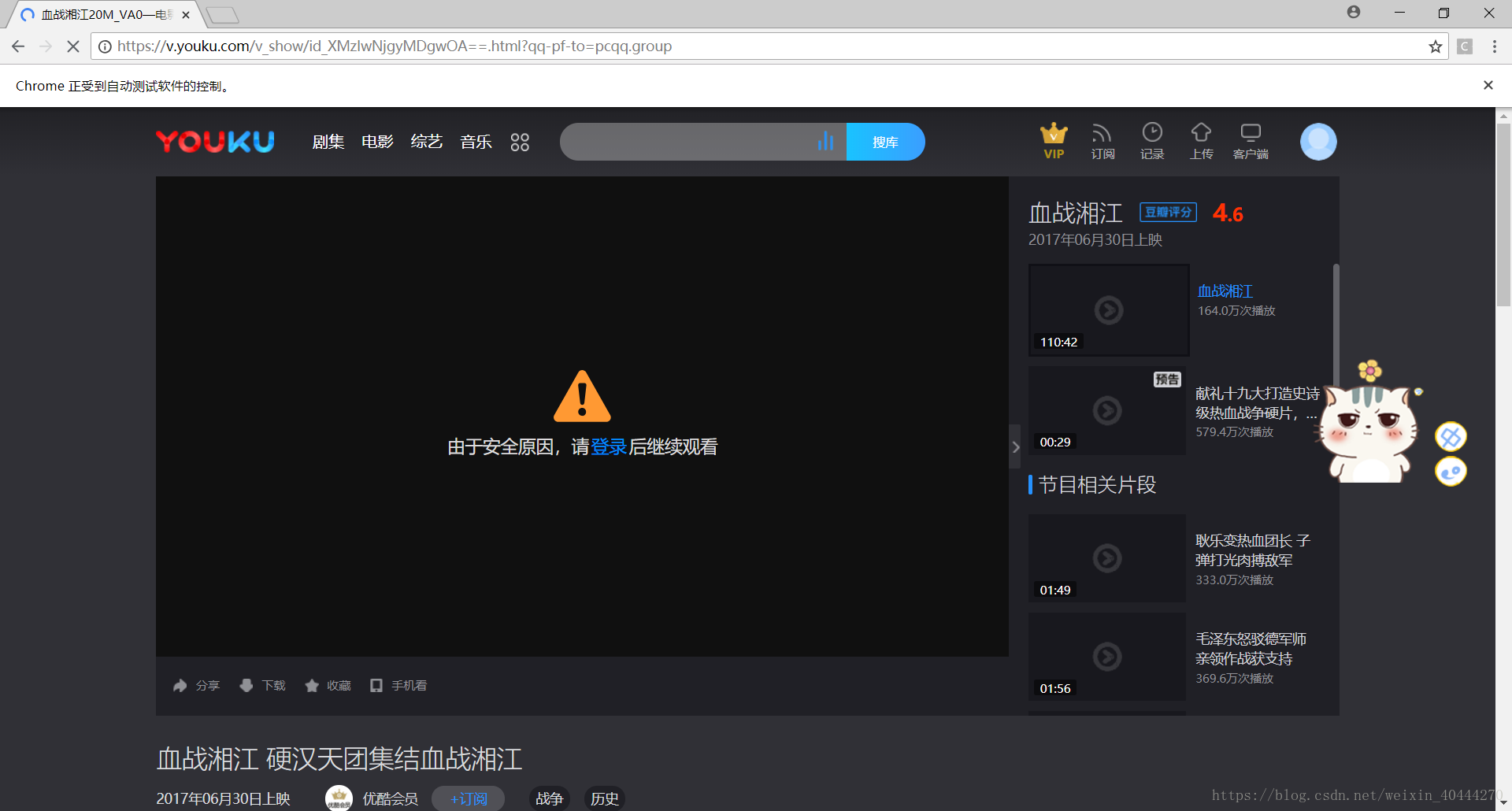
他尽然要进行登录才可以,那就开始模拟登录,点击右上角头像,出现这个登录框,基础的操作不多说了,登录成功保存cookie,这样下次模拟登录就不用这样输入密码账号了,我在模拟登录的时候,不知道为啥,登录按钮找不到,就手动点击按钮让它登录,然后保存cookie
这样cookie保存下来
import json
import time
from selenium import webdriver
driver=webdriver.Chrome()
driver.maximize_window()
driver.get('https://v.youku.com/v_show/id_XMzIwNjgyMDgwOA==.html?qq-pf-to=pcqq.group')
login=driver.find_element_by_id('qheader_login')
login.click()
time.sleep(3)
user=driver.find_element_by_id('YT-ytaccount')
user.send_keys(你的账号)
password=driver.find_element_by_id('YT-ytpassword')
password.send_keys(你的密码)
time.sleep(10)
在这个期间点击按钮进行登录
driver.refresh()
time.sleep(5)
cookie = driver.get_cookies()
print(cookie)
jsonCookies = json.dumps(cookie)
with open('qqhomepage.json', 'w') as f:
f.write(jsonCookies)
print(driver.page_source)获得cookie之后进行cookie模拟登录,这就可以了,输出的连接可以直接下载使用
import json
import re
import time
from selenium import webdriver
def getHtml():
driver=webdriver.Chrome()
driver.maximize_window()
driver.get('https://v.youku.com/v_show/id_XMzIwNjgyMDgwOA==.html?qq-pf-to=pcqq.group')
# 删除第一次建立连接时的cookie
driver.delete_all_cookies()
# 读取登录时存储到本地的cookie
with open('youku.json', 'r', encoding='utf-8') as f:
listCookies = json.loads(f.read())
for cookie in listCookies:
driver.add_cookie({
'domain': 'v.youku.com', # 此处xxx.com前,需要带点
'name': cookie['name'],
'value': cookie['value'],
'path': '/',
'expires': None
})
# 再次访问页面,便可实现免登陆访问
driver.get('https://v.youku.com/v_show/id_XMzIwNjgyMDgwOA==.html?qq-pf-to=pcqq.group')
cookie = driver.get_cookies()
print(cookie)
jsonCookies = json.dumps(cookie)
with open('youku.json', 'w') as f:
f.write(jsonCookies)
txt=driver.page_source
return txt
def parseHtml(txt):
pattern =re.compile(r'<video preload="metadata" src="(.*?)".*?>',re.S)
con=re.findall(pattern,txt)
url=con[0].replace('amp;','')
print(url)
start=time.time()
t=getHtml()
parseHtml(t)
end=time.time()
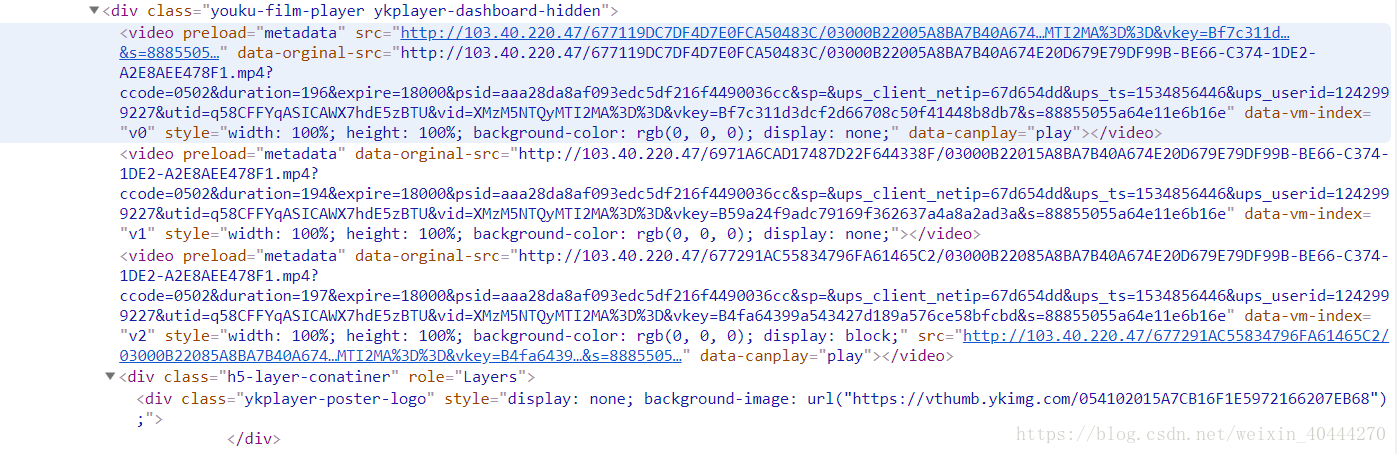
print("花费时间",end-start)于是我尝试爬取电影,发现这个不简单,有三个video,每个大约6分钟,然后我搜索一个关键字vkey,全局搜索
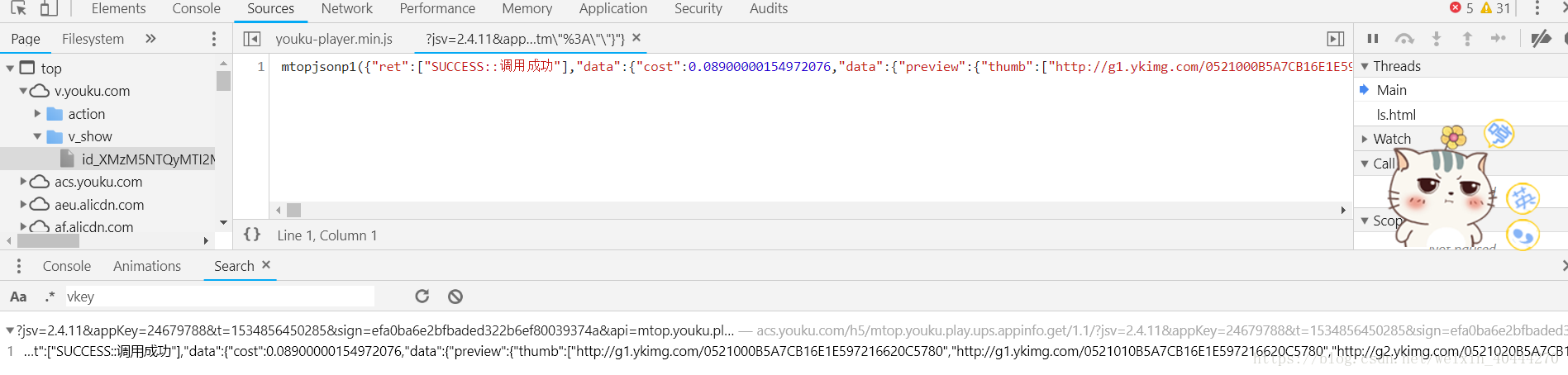
全局搜索找到這個js,裡面的內容就是許多視頻的片斷,調用這個需要特定的客戶端和key,我也就沒弄
知道模擬登錄怎麼尋找button,麻煩在評論里寫一下,謝謝