1.spark安装(本次启动一个worker)
首先安装spark
打开apache spark官网下载页点这里
选择spark版本下载,这里我选spark 2.0.2
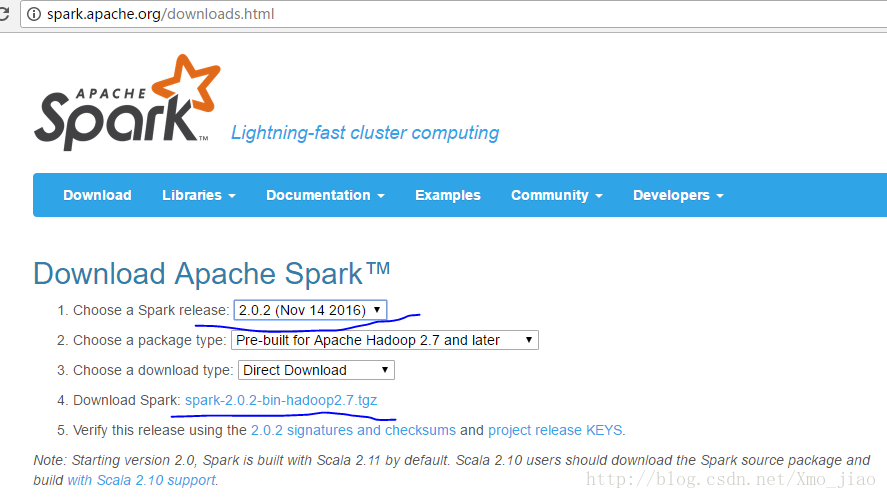
在linux系统中使用wget下载,wget是一种从网络上自动下载文件的自由工具,支持断点下载,很好用。没有此工具ubuntu,请使用一下语句安装
apt-get install wget
wget https://d3kbcqa49mib13.cloudfront.net/spark-2.0.2-bin-hadoop2.7.tgz然后解压在安装目录
tar -axvf spark-2.0.2-bin-hadoop2.7.tgz重新命名安装目录文件名,便于记忆使用
mv spark-2.0.2-bin-hadoop2.7 spark
cd /root/spark/sbin接着启动spark master 和一个slave(work).一下第一条指令在安装目录启动spark master,第二条指令是进入启动日志中,为了找到spark UI中的地址,截图如下:
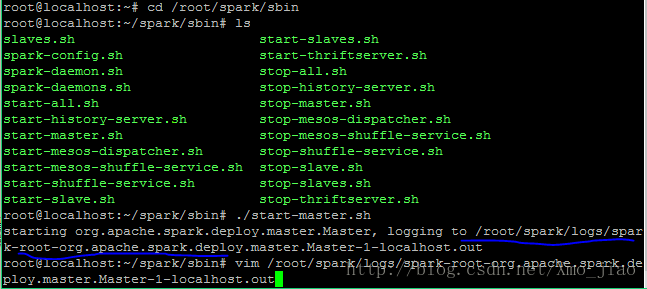
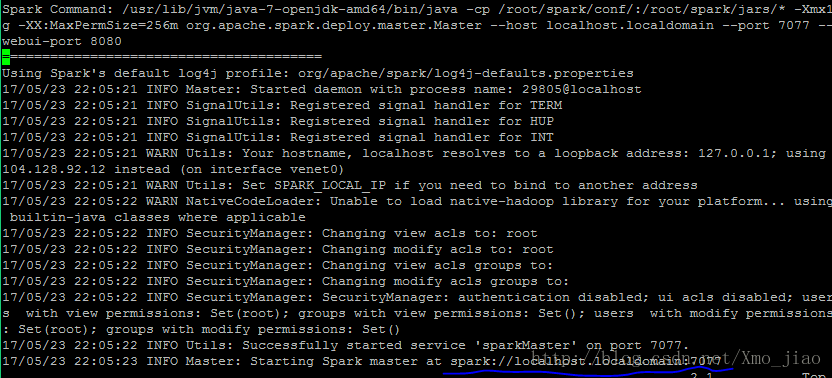
./start-master.sh
vim /root/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-localhost.out
./start-slave.sh spark://localhost.localdomain:7077
查看是否启动成功
ps -ef|grep spark截图如下,说明启动spark和一个worker成功

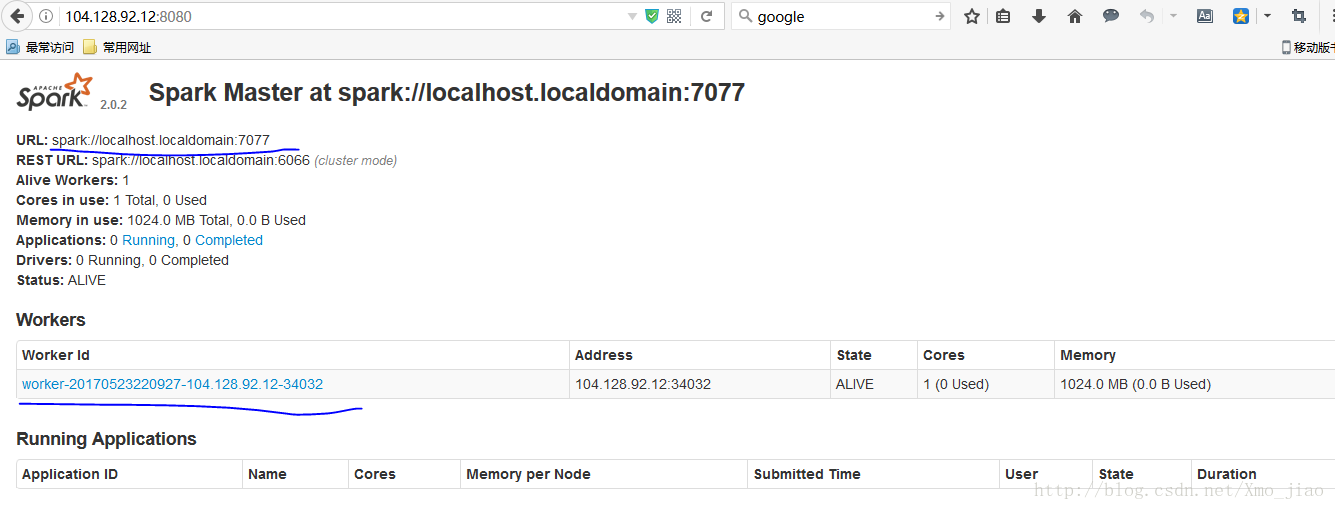
浏览器输入你的9.xx.xx.xx:8080,出现spark界面
2. 安装jupyter notebook
下载Anaconda3 找到linux环境下的python3的下载,复制链接,在命令行,使用wget下载工具下载
Anaconda官方下载页
wget https://repo.continuum.io/archive/Anaconda3-4.3.1-Linux-x86_64.sh使用bash安装,接连按很多次enter建,当出现是否时填yes,是否添加、/root/Anaconda到./bashrc时,回答yes,否则需要自己设置PATH路径,并影响jupyter notebook使用,显示找不到jupyter命令。**Note:**Anaconda3中自带jupyter notebook,也可以使用anaconda2 安装python2.7,但是不自带jupyter notebook,需手动安装
bash Anaconda3-4.3.1-Linux-x86_64.sh查看是否内置安装时内置PATH

vim ~/.bashrc测试是否安装成功:
jupyter notebook若你的linux系统有浏览器,则安装成功会在浏览器打开notebook编辑页
若你的linux没有浏览器,出现如下界面,说明你的linux环境找不到浏览器。此时我们也可以使用远程浏览器打开,比如一个可以连接你linux ip的windows 浏览器
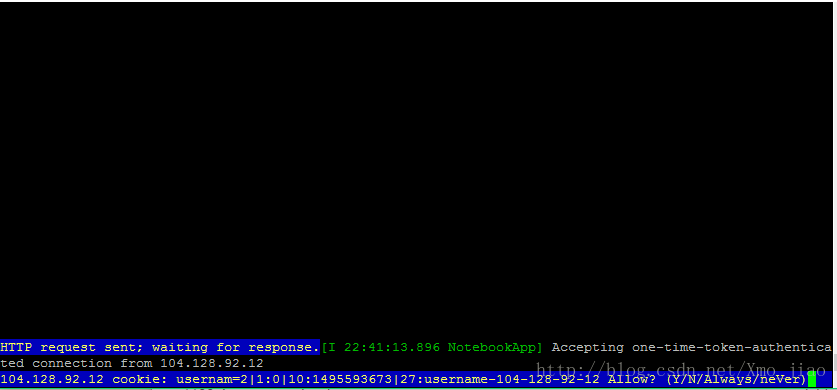
此时只能使用本机浏览器打开,若需要外部访问,还需要设置jupyter的配置文件,使可以远程浏览器访问,若本机存在浏览器,则跳过这一步。
创建并编辑config file,取消注释并设置IP,以及设置禁止自动打开浏览器
jupyter notebook --generate-config
vim /root/.jupyter/jupyter_notebook_config.py打开配置文件后找到如下设置,取消注释,并将c.NotebookApp.ip修改为你的ip地址,将 c.NotebookApp.open_browser修改为false
c.NotebookApp.ip = '9.xx.xx.xx'
c.NotebookApp.open_browser = False第一次在远程浏览器使用jupyter时,需要复制token到浏览器,即
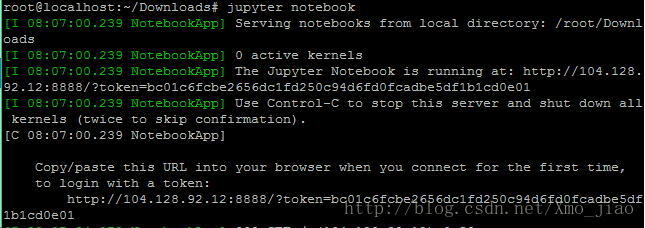
如上图,我的token为
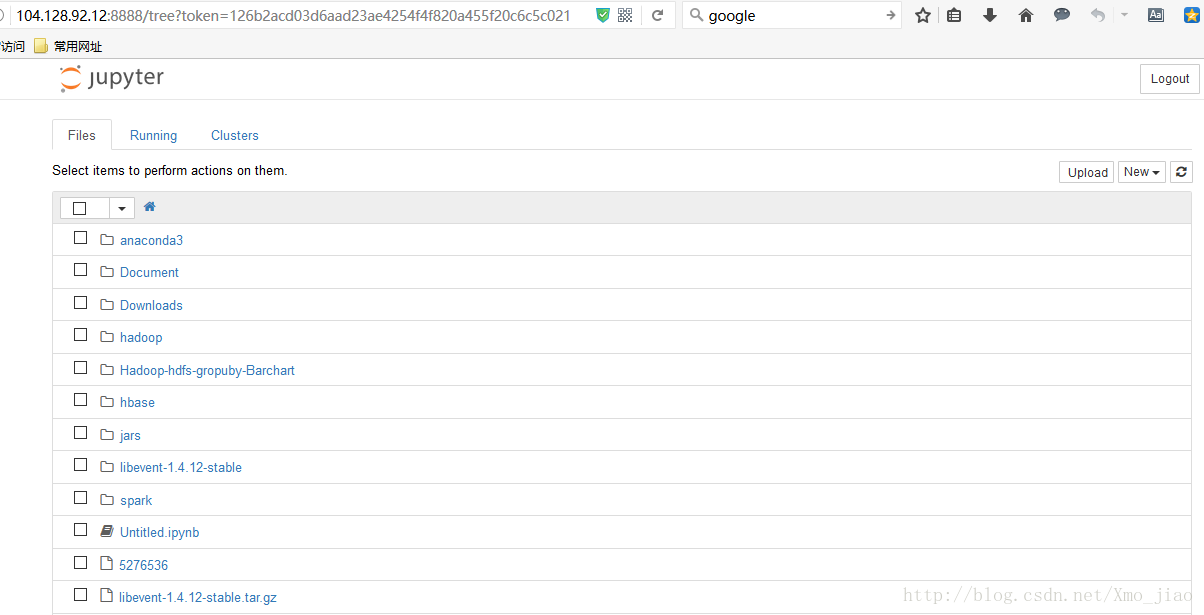
http://104.128.92.12:8888/?token=bc01c6fcbe2656dc1fd250c94d6fd0fcadbe5df1b1cd0e01,复制到远程浏览器,就可以打开notebook编辑界面,如下图:
3.安装spark kernel
到目前为止jupyter只有一个默认的python3的kernel,而且并没有连接任何spark.使用一下命令查看
jupyter kernelspec list1 基于pyspark的jupyter notebook
此处我们使用spark bin目录下的pyspark连接notebook,即启动./pyspark默认启动notebook.只需要在全局文件./bashrc中设置即可。
打开./bashrc文件
vim ~/.bashrc
添加如下两条全局命令
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook"在spark bin目录下测试notebook是否安装了pyspark,成功即出现如下图:
cd /root/spark/bin
./pyspark

2 基于Scala spark的jupyter notebook
此处使用Apache toree给notebook安装scala kernel
toree官网下载页,不需要解压,直接使用pip install安装
wget https://dist.apache.org/repos/dist/dev/incubator/toree/0.2.0/snapshots/dev1/toree-pip/toree-0.2.0.dev1.tar.gz
pip install toree-0.2.0.dev1.tar.gz接着使用一下命令安装,其中spark://localhost.localdomain:7077为你的spark地址,/root/spark为你的spark安装目录
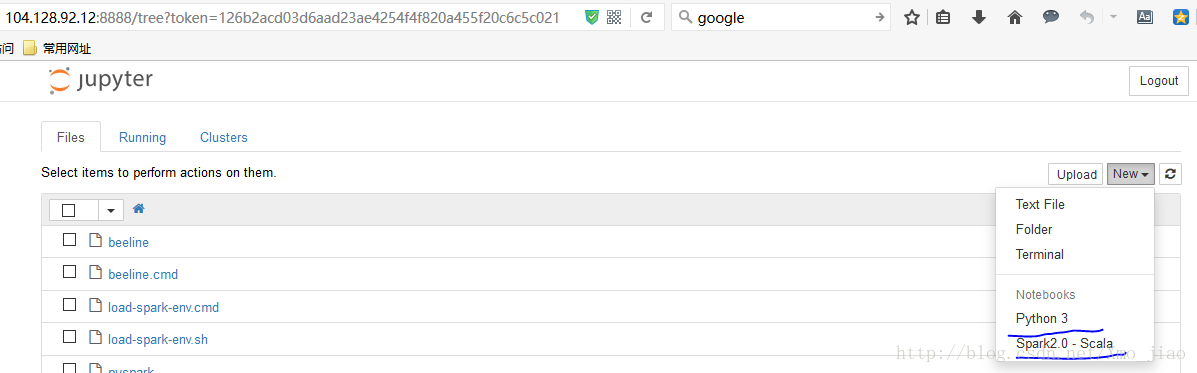
jupyter toree install --spark_opts='--master=spark://localhost.localdomain:7077' --user --kernel_name=Spark2.0 --spark_home=/root/spark测试是否安装成功,列出kernel列表,发现有两个kernel:python3 和spark 2.0_scala
jupyter kernelspec list
此时,python和scala版的jupyter安装成功
参考链接
http://blog.csdn.net/suzyu12345/article/details/51037905
https://www.douban.com/note/565651872/