思路
- 找到歌单的歌曲列表
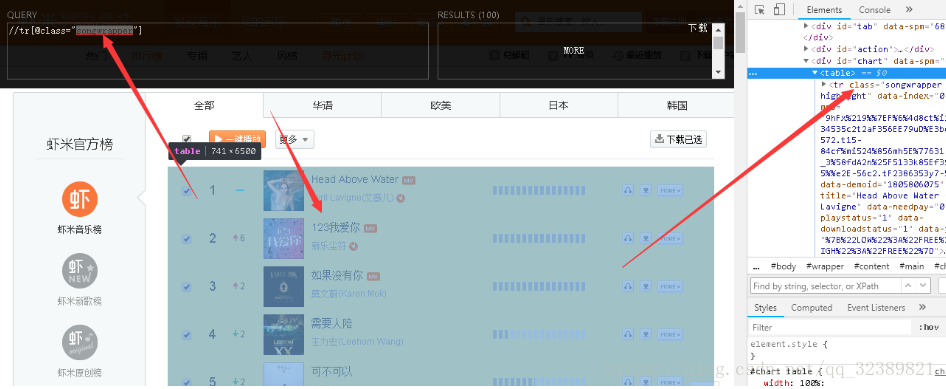
- 找到MP3超链接(虾米的链接需要进行凯撒解码)
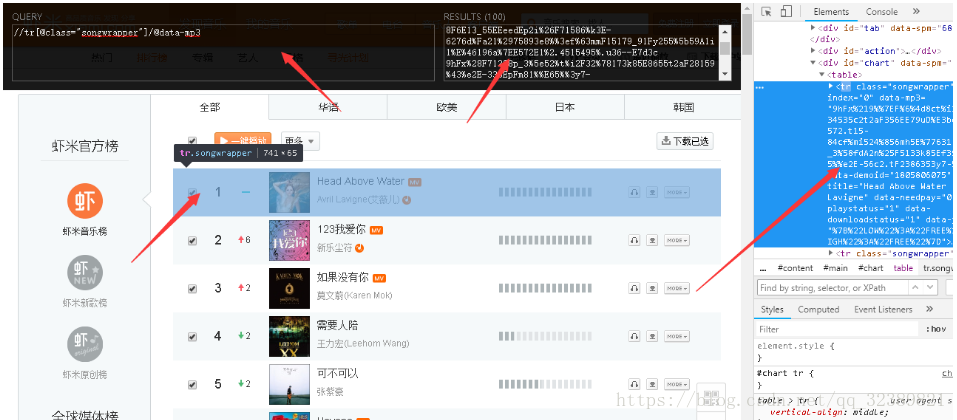
- 解码后,直接二进制写进文件即可
代码
import time
import requests
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from utils.kaisha import str2url
browser = webdriver.Chrome()
browser.set_window_size(800, 800)
wait = WebDriverWait(browser, 10)
def index_page():
url = 'https://www.xiami.com/chart/index/c/103/type/0?spm=a1z1s.2943549.6827461.1.a26OKv'
browser.get(url)
# 等待元素加载完成
wait.until(EC.presence_of_element_located((By.XPATH, '//tr[@class="songwrapper"]')))
# 获得页面的html
html = browser.page_source
return html
def pares_page(html):
# 转换属性
etree_html = etree.HTML(html)
# 获得所有歌曲标签mp3地址
data_mp3_list = etree_html.xpath('//tr[@class="songwrapper"]/@data-mp3')
# 获得歌曲名
data_mp3_name = etree_html.xpath('//tr[@class="songwrapper"]//strong/a/text()')
# 循环歌曲标签mp3地址
for index in range(len(data_mp3_list)):
# 凯撒密码解码
mp3_url = str2url(data_mp3_list[index])
# 组合名字
mp3_name = './song/' + data_mp3_name[index] +'.mp3'
headers = {"User-Agent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",}
response = requests.get(mp3_url, headers=headers)
# 写进文件
with open(mp3_name, 'wb') as f:
f.write(response.content)
print(mp3_name)
time.sleep(2)
def main():
# 获得歌单页面
page_source = index_page()
# 下载
pares_page(page_source)
if __name__ == '__main__':
main()
from urllib import parse
def str2url(s):
num_loc = s.find('h')
rows = int(s[0:num_loc])
strlen = len(s) - num_loc
cols = int(strlen/rows)
right_rows = strlen % rows
new_s = list(s[num_loc:])
output = ''
for i in range(len(new_s)):
x = i % rows
y = i / rows
p = 0
if x <= right_rows:
p = x * (cols + 1) + y
else:
p = right_rows * (cols + 1) + (x - right_rows) * cols + y
output += new_s[int(p)]
return parse.unquote(output).replace('^', '0')