(接上文《架构设计:系统存储(25)——数据一致性与Paxos算法(下)》)
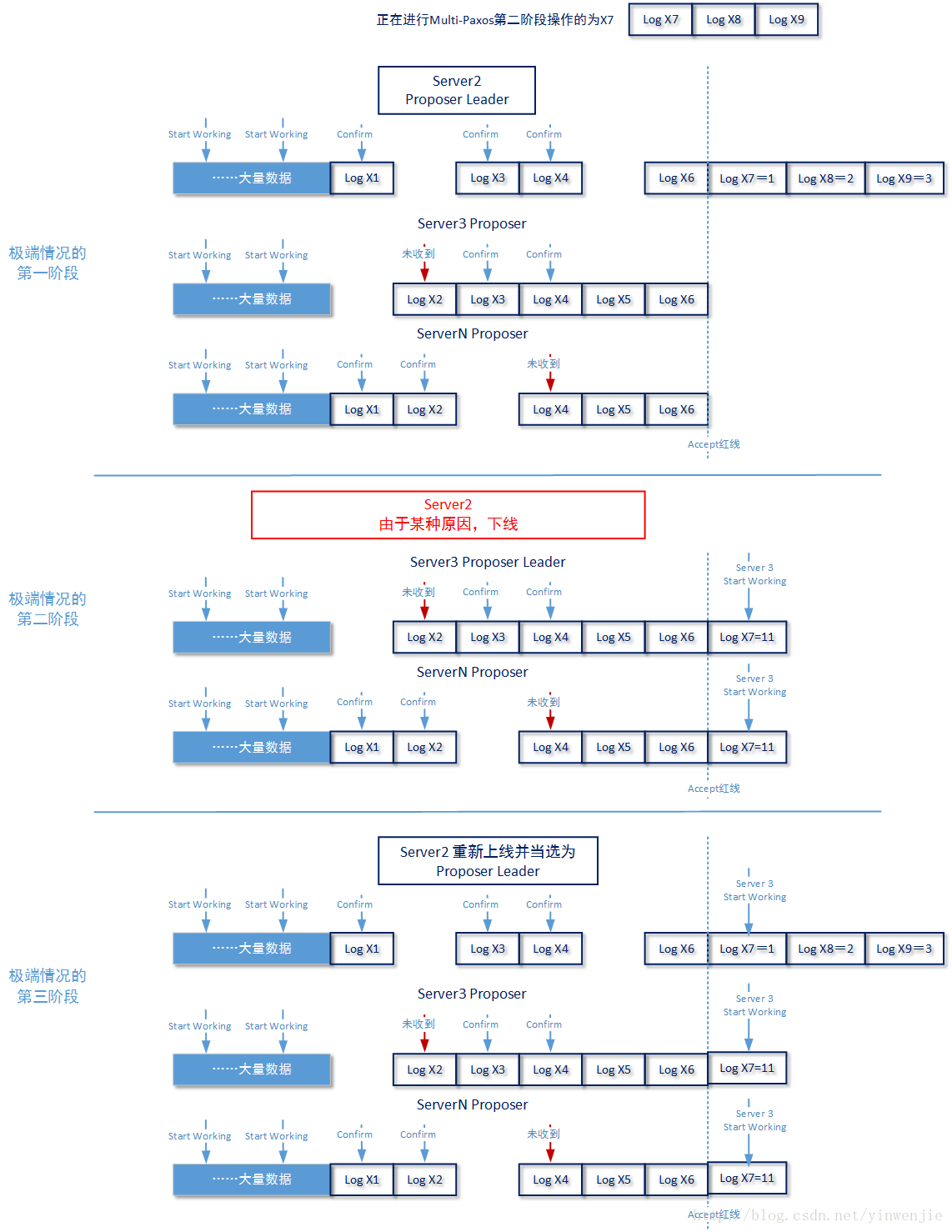
如上图所示,Server 2在宕机前正在对log7 、log8 、log9 进行Paxos,并且自身已经完成赋值过程(但是其它节点都还没有完成赋值过程,没有形成多数派)。这时Server 2由于某些原因下线了。Server 3通过选主过程拿到了Proposer Leader,但是它能获取到的最大log id为log6(因为现在存活的各个节点上最大的log id都是log6嘛),所以自己start working的log id 位置就是log7。就在这个时候,Server 2节点又恢复了工作,且技术人员人工命令从新授予Server 2 节点Proposer Leader身份。
这时在其上原有的log7、log8、log9虽然有值,但是也不能再使用了,需要重新进行恢复。那么Server 2依据什么来判断存储在自身节点的log7、log8、log9的值已经失效必须进行恢复的呢?那就是在start working的时候,记录了一个创建时间T1,在随后的工作中,节点每写入一条日志信息就要写入同时写入这个T1。当进行数据恢复时,如果发现某一条数据所记录的T1和其最近的start working标记点所记录的T1不一致,就认为这是一条记录时效的数据,需要进行恢复。
按照如上图所示的极端示例中,log7的值应该恢复成11,而log8、log9的值应该记为一个空值或者是恢复成一个NOP标记。
3. 其它说明
Paxos算法并不是所有最终一致性算法,Multi-Paxos也并不是唯一一种Paxos算法的变种,例如还有Fast-Paxos、Egalitarian-Paxos。Fast-Paxos进一步强调了Leaner角色在整个Paxos算法中的作用,进一步优化了多个Proposer的协作工作过程。在后续的文章中会适时回过头来介绍Fast-Paxos,这里确实不能在耽误时间向后推进了(本来计划3月下旬开始分布式文件系统Ceph的使用和原理介绍)
最终一致性算法除了Paxos外,还有ZAB算法、RAFT算法、GOSSIP算法和PacificA算法。其中ZAB算法应用在一个非常著名的软件Zookeeper中,而PacificA的思想则被用在Apache Kafka进行Partition Leader的选举过程中。关于Zookeeper的基本选举算法(FastLeaderELection)在笔者很早之前就向大家介绍过,感兴趣的读者可以参考以下文章:《zookeeper(2)——zookeeper核心原理(选举)》
后续的文章,我们将开始介绍分布式文件系统Ceph的使用和工作原理。从Ceph文件系统的介绍继续讲解