使用Scrapy编写职友集爬虫
本文针对刚刚接触爬虫或scrapy框架的朋友, 通俗的语言配以大量的截图, 相信能够帮助你入门爬虫, 对于平时想要从网上抓取信息的个人需求也已足够
一般来说编写一个完整的爬虫需要四个基本步骤
- 确定目标
- 获取数据
- 清洗数据
- 存储数据
之后我们所做的所有工作都是在这四步的基础之上扩展的, 如果你是刚刚接触爬虫的新手, 请在心中牢记这四个基本步骤, 它们会让你在写爬虫的过程中思路更加清晰
接下来就按照这个基本思路开始我们的爬虫
1. 明确目标
首先我们需要明确目标网站—–职友集
公司详情的展示页面

首先我们要做的就是先确认数据的位置
一般来说有三种情况
数据在html文档内且是规范的html文档
这是最理想的情况, 因为scrapy的选择器就是专门针对这种界面的数据提取而设计的
数据在html文档内但是不是规范的html文档
这是一种常见的网站反爬措施, 数据信息以注释或者是其他形式隐藏在html文档中, 然后由JS代码插入到对应的标签内以完成界面的正常显示. 这种情况, 使用scrapy的选择器就无效了, 但是我们还有终极武器—–正则表达式, 只要我们能获取到内容, 正则就一定匹配的到
数据由ajax动态加载
ajax技术的初始目的是让用户获得更好的体验, 不用刷新整个界面就可以得到新内容, 但是对于我们爬虫来说, 却让爬取过程变得复杂, 我们必须利用浏览器自带的抓包工具或者fiddler等抓包软件去寻找与所需数据相对应的请求, 并且模拟该请求来获取数据
在这里我们开始进行测试
使用Chrome浏览器访问任意一个公司详情界面, 按F12检查网页, 在Network中选中Doc, 此时排在第一个的文档应该就是我们请求这个url接收到的文档, 查看request url验证一下, 图中的request url与我们浏览器地址栏的url一致, 说明该响应是这个url的响应
检查response, 我们必须找到我们要获取的数据在哪里. 在该界面中寻找一个有代表性的字段, 然后再response中搜索, 此时我们选青岛链家四个字来搜索, 发现可以找到并且周围是标准的html标签, 可以确定是第一种最理想的情况
使用scrapy创建我们的爬虫, 在命令行中输入命令
scrapy startproject zhiyou
使用scrapy自带的爬虫模板创建一个spider
scrapy genspider -t crawl ‘zhiyouji’ ‘zhiyouji.com’
使用IDE打开我们创建的项目, 笔者用的是pycharm,
根据scrapy的设计思想, 我们需要把我们要抓取的目标在items.py这个文件中确定好. 比如我们想要抓取公司的名称, 那么我们需要设置一个字段company_name来保存我们爬取到的公司名称. 这个类是scrapy帮我们创建好的, 继承自scrapy.Item类, 作为我们数据的存储容器, 是一种类字典的数据结构, 但是更贴合scrapy的使用需求.
- 同理, 我们就可以确定出我们的所有字段



class ZhiyouItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# pass
url = scrapy.Field()
crawl_time = scrapy.Field()
# 公司名称
company_name = scrapy.Field()
# 公司在该网站的id
company_id = scrapy.Field()
# 公司图标
company_brand_url = scrapy.Field()
# 浏览人数
view_num = scrapy.Field()
# 评价人数
evaluation_num = scrapy.Field()
# 关注人数
attention_num = scrapy.Field()
# 星级
star_rank = scrapy.Field()
# 简介
brief = scrapy.Field()
# 点赞数
good_num = scrapy.Field()
# 一般数
general_num = scrapy.Field()
# ##### 概况页面
# 公司投资情况
company_investment_status = scrapy.Field()
# 公司人数
company_people_num = scrapy.Field()
# 公司行业
company_industry = scrapy.Field()
# 公司简称
company_shortname = scrapy.Field()
# 公司概况文字描述
company_profile = scrapy.Field()
# ##### 公司的工商信息
business_info_url = scrapy.Field()
# 统一信用代码
credit_code = scrapy.Field()
# 注册资本
registered_capital = scrapy.Field()
# 经营状态
manage_status = scrapy.Field()
# 法定代表
legal_representative = scrapy.Field()
# 成立日期
establish_date = scrapy.Field()
# 营业期限
business_expire = scrapy.Field()
# 注册地址
registered_address = scrapy.Field()有的时候我们会想要获取页面中所有有用的信息, 那么我个人建议最好是用分块的思想, 将页面按照视觉上的直观感受分为各个部分, 然后在代码中有所体现, 这样不仅增加了代码的易读性, 还会使我们的思路更加清晰. 比如上面的代码, 通过五个星号来区分, 我甚至之后再看它能够回想起页面的样子.
注释必不可少, 我认为编写代码的过程就是一个翻译的过程
- 有的时候直接把脑中的想法翻译为代码的过程会产生一种直觉上想当然的错觉, 而如果先把脑中的想法翻译为自己的母语, 然后在转换为代码, 产生错觉的概率就会减小. 而且如果你的注释清晰且丰富, 别人在阅读你的代码的时候, 没准可以像看小说一样, 哈哈
吐槽下CSDN的Markdown竟然还不能支持表情,有的时候没有表情感觉说话变得怪怪的.......
获取数据
使用框架的好处就是我们不用总是去写那些需要重复写的代码, 但是框架也产生了一定的学习成本. 初识scrapy, 三个重要的类是必须要了解的. Request对象就是我们的请求对象, 里面包含了请求所需要的所有信息. Response对象是我们的响应对象, 我们获取的数据就在这个对象里面, items是我们存储信息的容器, 比单纯的字典要好用的多.
简单来说, scrapy运行之后一直在做的事情就是首先把起始的url打包成Request对象, 然后由交由调度器去重, 然后交给下载器下载数据得到Response对象, 从Response对象中抽取数据存入items对象中保存起来, items也会有对应的方法把这些数据存到文件或是数据库中. 同时也要抽取出需要下载的url打包成Response对象继续交给下载器下载. 官方给出的流程图非常的直观
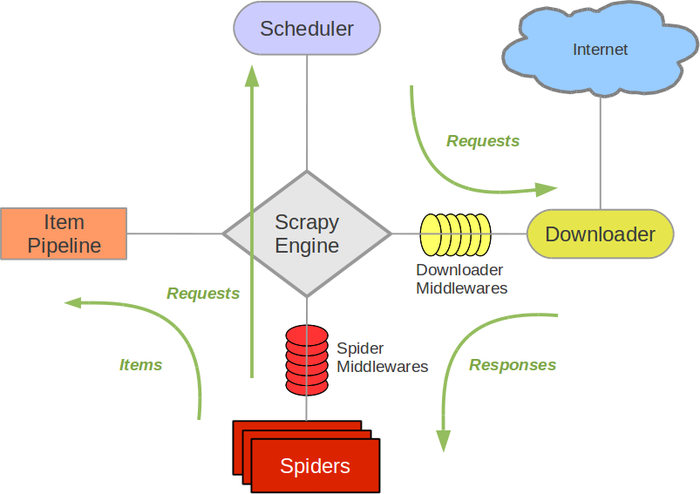
所以, 一般情况下, 下载器下载数据是scrapy自动完成的, 但是在遇到scrapy的下载器处理不了我们应对的问题时, 我们可能需要一些额外的操作, 这个以后再说. 本例中scrapy的下载器已足够满足需求.
提取数据
我们刚刚已经确定我们对url进行请求就可以直接获取到我们的数据, 接下来我们需要从html文档中提取出我们所需要的数据, scrapy内置的选择器可以很好的帮我们处理这一点. 为此, 你需要补充一些xpath的语法知识.在spiders文件夹下的zhiyouji.py中编写如下代码
import scrapy
import time
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from zhiyou.items import ZhiyouItem
class ZhiyoujiSpider(CrawlSpider):
name = 'zhiyouji'
allowed_domains = ['jobui.com']
start_urls = ['http://www.jobui.com/cmp?area=%E5%85%A8%E5%9B%BD&sortField=sortTime']
rules = (
Rule(LinkExtractor(allow=r'/company/\d+/$'), callback='parse_detail_page', follow=True),
Rule(LinkExtractor(allow=r'/cmp.*?sortTime&n=\d+'), follow=True),
)
def parse_detail_page(self, response):
if response.status != 200:
return None
item = ZhiyouItem()
item['url'] = response.url
item['company_id'] = item['url'].split('/')[-2]
item['crawl_time'] = time.ctime()
item['company_name'] = response.xpath('//*[@id="companyH1"]/a/text()').extract_first()
item['company_brand_url'] = response.xpath('//div[@class="company-logo"]//img/@src').extract_first()
item['good_num'] = response.xpath('//*[@id="goodNum"]/text()').extract_first()
item['general_num'] = response.xpath('//*[@id="generalNum"]/text()').extract_first()
content = response.xpath('//div[@class="company-logo"]/following-sibling::div[1]//div[@class ="fl ele fs16 gray9 mr10"]/text()').extract_first()
if content is not None:
con_list = content.split()
item['view_num'] = con_list[0].split('人')[0][:-1:1] if len(con_list) > 0 else None
item['view_num'] = float(item['view_num'])
item['evaluation_num'] = con_list[2] if len(con_list) > 2 else None
item['attention_num'] = con_list[4] if len(con_list) > 4 else None
item['star_rank'] = response.xpath('//div[@class="star fl"]/div/@title').extract_first()
item['brief'] = response.xpath('//div[@class="company-head-information"]//p[@class="fs16 gray9 sbox company-short-intro"]/text()').extract_first()
investment_and_people = response.xpath('//div[@class="intro"]/div[2]//dd[1]/text()').extract_first()
try:
item['company_investment_status'] = investment_and_people.split('/')[0].strip()
except:
print('无法获取到公司投资状态')
item['company_investment_status'] = None
try:
item['company_people_num'] = investment_and_people.split('/')[1].strip()
except:
print('无法获取到公司人数')
item['company_people_num'] = None
# 采集公司行业信息
ind_list = response.xpath('//dd[@class="comInd"]/a')
ind_con = []
for ind in ind_list:
ind_con.append(ind.xpath('./text()').extract_first())
item['company_industry'] = ind_con
item['company_shortname'] = response.xpath('//dd[@class="gray3"]/text()').extract_first()
# 获取公司概况 company_profile
profile_list = response.xpath('//*[@id="textShowMore"]/text()').extract()
profile_con = ''
for profile in profile_list:
profile_con += profile.strip()
item['company_profile'] = profile_con
# 获取公司的工商信息
business_url = 'http://www.jobui.com/async/company_info_businessInfo/' + item['company_id'] + '.html'
yield scrapy.Request(url=business_url, callback=self.parse_business_page, priority=1, meta={'item': item})
def parse_business_page(self, response):
# print(response.status, '-'*100)
item = response.meta['item']
item['business_info_url'] = response.url
info_node = response.xpath('/html/body/div/div[2]/div')
item['credit_code'] = info_node.xpath('./p[1]/span[2]/text()').extract_first()
item['registered_capital'] = info_node.xpath('./p[6]/span[2]/text()').extract_first()
item['manage_status'] = info_node.xpath('./p[2]/span[2]/text()').extract_first()
item['legal_representative'] = info_node.xpath('./p[3]/span[2]/text()').extract_first()
item['establish_date'] = info_node.xpath('./p[4]/span[2]/text()').extract_first()
item['business_expire'] = info_node.xpath('./p[5]/span[2]/text()').extract_first()
item['registered_address'] = info_node.xpath('./p[6]/span[2]/text()').extract_first()
yield item这个ZhiyoujiSpider类给定了起始的url, 并且定义了response的抽取规则.
scrapy的执行过程是先把start_urls里面的url打包成Request, 下载器得到response之后会把response对象交给我们的链接提取器, 根据我们给定的正则表达式提取出页面中符号要求的url, 继续打包为Request, 同时定义了回调函数来处理响应的response
回调函数中主要在做的事情就是根据xpath语法提取response中的数据和链接, 数据存入到items中, 链接打包成Request. scrapy一个非常巧妙的设计是用的迭代器, 这样我们就可以随时返回我们想要交给scrapy引擎的对象了.
存储数据
打开pipelines.py
class ZhiyouCsvPipeline(object):
def __init__(self):
self.file = {}
@classmethod
def from_crawler(cls, crawler):
pipeline = cls()
crawler.signals.connect(pipeline.spider_opened, signals.spider_opened)
crawler.signals.connect(pipeline.spider_closed, signals.spider_closed)
return pipeline
def spider_opened(self, spider):
# print('我要开始了'*10)
# print(hash(spider))
file = open('zhiyouinfo.csv', 'wb')
self.file[spider] = file
self.exporter = CsvItemExporter(file)
self.exporter.start_exporting()
def spider_closed(self, spider):
# print('我要结束了'*10)
self.exporter.finish_exporting()
file = self.file.pop(spider)
file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item我们调用了scrapy自带的csv输出器来把我们的数据转换为csv文件
然后再settings.py中开启我们的pipeline
ITEM_PIPELINES = {
# 'zhiyou.pipelines.ZhiyouPipeline': 300,
'zhiyou.pipelines.ZhiyouCsvPipeline': 301
}简单的反爬处理
在settings.py设置一个默认的请求头, 让我们更像一个浏览器发送的请求
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
# 'Cookie': 'jobui_area=%25E5%258C%2597%25E4%25BA%25AC; Hm_lvt_8b3e2b14eff57d444737b5e71d065e72=1515945094; jobui_p=1515945093750_17983135; jobui_seSun=1; PHPSESSID=lt6lipbei9p46spd7o08tkebc3; job-subscribe-guide=1; jobui_user_passport=yk15159456732654; Hm_lpvt_8b3e2b14eff57d444737b5e71d065e72=1515945722; TN_VisitCookie=16; TN_VisitNum=5',
'Host': 'www.jobui.com',
# 'If-Modified-Since': 'Sun, 14 Jan 2018 16:01:57 GMT',
'Referer': 'http://www.jobui.com/cmp?area=%E5%85%A8%E5%9B%BD&keyword=',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36',
}设置延迟, 遵守robots协议设置为False, 由于不需要登录, 所以可以不携带cookie
DOWNLOAD_DELAY = 0.1
ROBOTSTXT_OBEY = False
COOKIES_ENABLED = False项目代码: https://github.com/luokezhen/zhiyouji_spider
以上均为我个人的学习感悟, 欢迎批评指正
灵感源于交流 :
QQ: 1396737599
微信: 18500094110